
Intro of Hadoop-Understading BigData(6)
Intro
학교 수강과목에서 학습한 내용을 복습하는 용도의 포스트입니다.
빅데이터 개념과 오픈소스인 아파치 하둡과 맵리듀스 및 스파크를 이용한 빅데이터 적용을 공부합니다.
맵 리듀스의 경우 사용하기에 다소 진입장벽이 있는편입니다.
스파크처럼 통합 환경을 제공하지 않아 원하는 유틸리티나 라이브러리를 별도로 연결해서 사용해야하기 때문입니다. 이를 해소하는 것이 스파크라는 분산 데이터 처리 통합 엔진입니다.
따라서 맵 리듀스로 먼저 공부해보고, 스파크로 넘어갑니다.
스파크 엔진의 경우 Java가 아닌 Scalar라는 언어로 사용하며, 기존 우리가 알고 있는 SQL을 통해 고급 질의가 가능하며, 시각화나 스트림 처리 및 기계학습등 까지의 높은 수준의 분석을 제공하는 통합 프레임 워크입니다.
빅데이터 컴퓨팅(분산시스템상의 분산처리 환경)의 기본 개념과 원리를 이해하고 이를 실습해보는 과정에서 2대 이상의 리눅스 클러스터 서버를 구축 및 활용할 것입니다.
빅데이터이해(1) 보러가기
빅데이터이해(2) 보러가기
빅데이터이해(3) 보러가기
빅데이터이해(4) 보러가기
빅데이터이해(5) 보러가기
이번 시간엔 하둡을 설치하고 하둡의 클러스터 동작을 확인하기 위해 간단한 프로그램 실행을 살펴봅니다.
이번엔 쉘 상에서 확인보다는 웹브라우저 클라이언트 상에서 확인할 겁니다.
NAT 포트포워딩 설정을 해놓았기 때문에 가능합니다.
이후부터의 실습은 모두 가상머신 실습환경이 완벽히 구축되어 있어야지만 가능합니다!
이 링크를 따라서 꼭 설정해주세요.
하둡 설치
우리의 클러스터 노드는 master node 하나, slave node1 하나 총 두개로 구성되어 있습니다.
slave node가 data node가 되도록 설치를 진행해보겠습니다.
우리가 클러스터를 구성할 때 두대밖에 없으니 master 호스트에는 namenode와 datanode까지 구성하고, slave1 호스트에는 secondary namenode와 data node로 구성하도록 하겠습니다.
이때 secondary namenode는 name node가 죽었을 때를 대비해서 두는 것 입니다.
하둡을 설치하기 위해서는 하둡이 java로 구현된 분산파일 시스템이기 때문에 자바 가상 머신이 설치되어있어야 합니다.
오라클의 자바 라이센스 정책 변경으로 인해 ppa가 폐기되어 tar.gz 형태의 jdk 파일을 수동으로 다운로드한 후에 압축해제해주며 진행해야합니다.
jdk 파일 다운로드 링크:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
아래 명령어를 순서대로 입력함으로써 모든 노드에 자바8을 설치해줍니다.
tar -xvzf jdk-8u201-linux-x64.tar.gz
sudo mkdir /usr/lib/jvm
sudo mv jdk1.8.0_201 /usr/lib/jvm
첫번째 명령에 대한 설명입니다.
x와 z는 압축해제, v옵션은 과정이 출력되도록 하는 것이고요 f는 파일을 지시하기 위한 것 입니다.
이후 Java 환경변수 설정을 위해 ~/.bashrc에 아래 내용을 추가해줍니다.
export JAVA_HOME="/usr/lib/jvm/jdk1.8.0_201"
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=$JAVA_HOME/lib:$CLASSPATH
추가 이후에는 적용을 해줍니다.
source ~/.bashrc
그 다음 아래 명령어를 차례로 입력해 자바의 심볼릭 링크를 생성해줍니다.
심볼릭 링크는 윈도우의 바로가기에 해당한다 설명했었습니다.
sudo update-alternatives --install "/usr/bin/java" "java" "/usr/lib/jvm/jdk1.8.0_201/bin/java" 1
sudo update-alternatives --install "/usr/bin/javac" "javac" "/usr/lib/jvm/jdk1.8.0_201/bin/javac" 1
sudo update-alternatives --install "/usr/bin/javaws" "javaws" "/usr/lib/jvm/jdk1.8.0_201/bin/javaws" 1
심볼릭 링크를 생성했다면, 적용이 정상적으로 되었는지 확인하기 위해 재부팅해줍니다.
sudo reboot
자바가 정말로 잘 설치 되었는지 확인해줍니다.
java -version
우리는 두대의 노드를 클러스터로 사용할 것인데, ip주소가 아닌 이름으로 사용하기 위해서 노드의 호스트 이름 설정을 하겠습니다.
/etc/hosts라는 파일이 있습니다.
그 파일에 아래 내용을 써줍니다.
...
ff02::2 ip6-allroutes
ff02::3 ip6-allhosts
여기 바로 밑에다가요.
192.168.0.200 master
192.168.0.201 slave1
이렇게 각 IP 와 부를 이름을 매핑해줍니다.
이제 본격적으로 모든 노드에 하둡을 설치해줄건데요, 번거로우니까 일단 마스터노드에 설치를 하고난 후에 슬레이브 노드에 설치 및 설정을 복사하도록 하겠습니다.
안정된 버전인 하둡 2.7.7 패키지를 다운로드합니다.
하둡 다운로드 링크
아래 명령어를 입력해 설치를 진행해줍니다.
wget https://archive.apache.org/dist/hadoop/core/hadoop-2.7.7/hadoop-2.7.7.tar.gz
다운로드가 완료되었으면 압축해제하겠습니다.
tar -xvzf hadoop-2.7.7.tar.gz
압축을 해제하면 사용자의 홈디렉토리 밑에 hadoop-2.7.7라는 디렉토리 밑에 압축해제된 파일들이 놓여있을 겁니다.
자유로운 사용을 위해서 마찬가지로 환경변수 설정을 합니다.
~/.bashrc에 아래 내용을 추가해줍니다.
export HADOOP_PREFIX=$HOME/hadoop-2.7.7
export HADOOP_HOME=$HOME/hadoop-2.7.7
export PATH=$PATH:$HADOOP_PREFIX/bin
export PATH=$PATH:$HADOOP_PREFIX/sbin
export HADOOP_MAPRED_HOME=${HADOOP_PREFIX}
export HADOOP_COMMON_HOME=${HADOOP_PREFIX}
export HADOOP_HDFS=${HADOOP_PREFIX}
export YARN_HOME=${HADOOP_PREFIX}
export HADOOP_YARN_HOME=${HADOOP_PREFIX}
export HADOOP_CONF_DIR=${HADOOP_PREFIX}/etc/hadoop
export YARN_CONF_DIR=${HADOOP_PREFIX}/etc/hadoop
#Native Path
export HADOOP_COMMON_LIB_NATIVE_DIR=${YARN_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=$YARN_HOME/lib"
추가하셨다면 적용을 해줍니다.
source ~/.bashrc
이해를 돕기 위해 캡처화면 첨부해드리겠습니다.
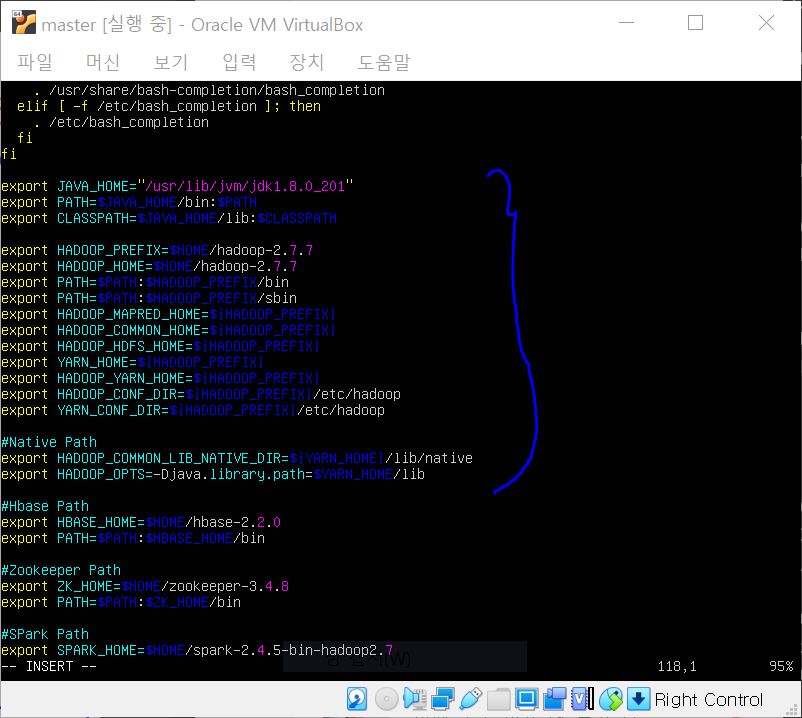
클러스터 설정에서 마스터 호스트와 슬레이브1 호스트 모두 데이터 노드로 설정하기로 했었죠?
~/hadoop-2.7.7/etc/hadoop/slaves 파일에 아래 내용을 입력해주세요.
master
slave1
ip로 구분하지 않아도 이름을 등록해줬으니 알아 들을 수 있겠지요?
우리가 마스터 노드에서 슬레이브 노드로 암호없이 SSH로 접속할 것이기 때문에 하둡에서도 SSH 인증 설정을 해줍니다.
모든 노드의 홈 디렉토리 아래에 .ssh라는 디렉토리에 SSH 키를 생성합니다.
우선 마스터 노드에서 아래 명령어를 입력하여 각 노드의 공용키를 생성합니다.
ssh-keygen -t rsa
ssh slave1 'ssh-keygen -t rsa'
각 노드에 생성된 공용 키를 ~/.ssh/authorized_keys에 수집합니다.
cat ~/.ssh/id_ras.pub >> ~/.ssh/authorized_keys
ssh slave1 'cat ~/.ssh/id_ras.pub' >> ~/.ssh/authorized_keys
위 명령어는 슬레이브 노드의 공용키를 마스터 노드의 auth 키에다가 원격으로 append 시키는 명령어입니다.
그럼 마스터에서는 자기 자신의 키와 슬레이브 키를 가지고 있는건데요, 슬레이브에서도 마찬가지로 가지고 있어야합니다.
그래서 마스터에서 수집된 공용키를 슬레이브 노드로 배포합니다.
scp ~/.ssh/authorized_keys slave1:~/.ssh/authorized_keys
암호 입력 요구 없이 접속이 되는지 테스트를 해봅시다.
ssh slave1
이후에 하둡 설정을 일부 수정할 겁니다.
하둡은 XML형식의 설정파일을 가지고 있습니다.
먼저 네임 노드의 URI를 설정합니다.
HDFS와 MapReduce에 공통으로 사용되는 하둡 코어를 위한 환경 설정을 진행할 건데요,
fs.default.name 항목이 네임노드를 가리키면 하둡의 맵리듀스 작업은 자동으로 HDFS를 이용하여 입력파일을 전달하게 됩니다.
~/hadoop-2.7.7/etc/hadoop/core-site.xml 파일의 내용을 아래와 같이 수정해주세요.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
그 다음은 네임노드, 보조 네임노드, 데이터노드 등과 같은 HDFS 데몬을 위한 환경 설정을 하기 위해 ~/hadoop-2.7.7/etc/hadoop/hdfs-site.xml 파일을 수정합니다.
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/home/bigdata/hadoop-2.7.7/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/bigdata/hadoop-2.7.7/hdfs/data</value>
</property>
<property>
<name>dfs.http.address</name>
<value>master:55070</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave1:50090</value>
</property>
</configuration>
이렇게 설정하게되면 웹으로 마스터에 접속할 때는 50070, 슬레이브1에 접속할 때는 50090으로 입력하시면 됩니다.
다음은 YARN의 자원관리자, 노드관리자를 위한 환경 설정입니다.
~/hadoop-2.7.7/etc/hadoop/yarn-site.xml 파일을 아래와 같이 수정해주세요.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8025</value>
</property>
<property>
<name>yarn.resourcemanager.sheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8050</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
그리고 맵리듀스의 JobTracker와 TaskTracker 데몬을 위한 환경 설정으로 ~/hadoop-2.7.7/etc/hadoop/mapred-site.xml파일을 아래와 같이 수정해주세요.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
그리고 하둡을 구동하는 스크립트에서 사용되는 환경 변수도 설정해줍니다.
~/hadoop-2.7.7/etc/hadoop/hadoop-env.sh파일을 수정해주세요.
export JAVA_HOME="/usr/lib/jvm/jdk1.8.0_201"
export HADOOP_HOME=PREFIX=${HADOOP_HOME}
...
이상과 같이 마스터 노드의 설치 및 설정을 슬레이브 노드에 배포해야하는데요,
변경했던 .bashrc 먼저 배포해봅시다.
scp /home/bigdata/.bashrc slave1:~
하둡 설치 디렉토리도 배포합니다.
scp -r /home/bigdata/hadoop\-2.7.7 slave1:~
ssh 암호 없이 바로 복사 가능한 것을 확인하실 수 있을 겁니다.
이제 하둡 실행을 한번 해봅시다.
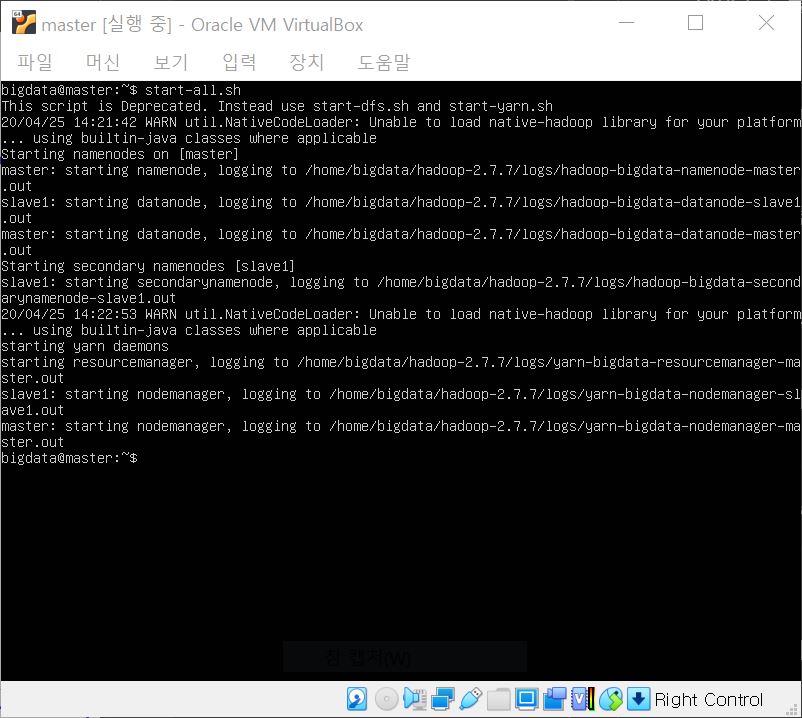
모든 하둡 클러스터의 HDFS 시작, YARN 데몬 실행을 위한 명령어인 아래 명령어를 입력해주세요.
start-all.sh
종료 시에는 반드시 마스터에서 아래 명령어를 입력해 하둡을 종료시켜주셔야합니다.
stop-all.sh
종료 시키지 않고 컴퓨터를 꺼버리게 되면 설치된 하둡이 깨질 수 있어요.
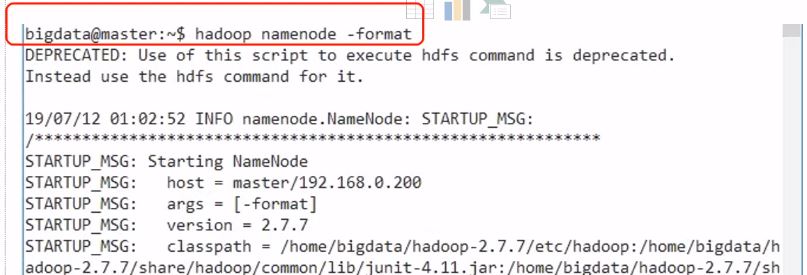
최초 한 번 실행시에 마스터에서 아래 명령어를 입력해 네임 노드를 포맷해줘야합니다.
hadoop namenode -format
참고로 하둡 hdfs를 시작하는 명령어는
start-dfs.sh
이며 yarn 데몬 실행을 위한 명령어는
start-yarn.sh
입니다.
종료시에는 start를 stop으로만 바꿔주시면 됩니다.
하둡이 잘 설치되었는지 확인하기 위해 두 명령어도 입력해 확인해주세요.
hdfs version
이 명령어는 하둡 버전 확인을 위한 명령어입니다.
프로세스 확인을 위해서 jps라는 명령어도 입력해주세요.
jps
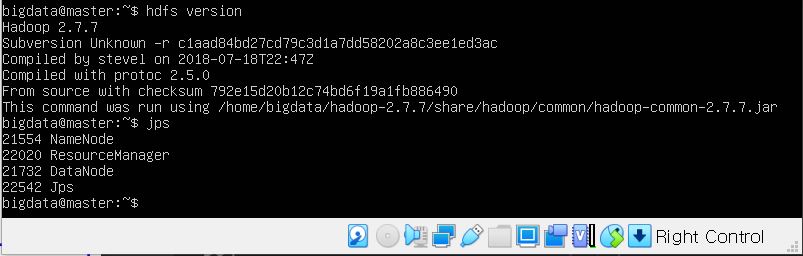
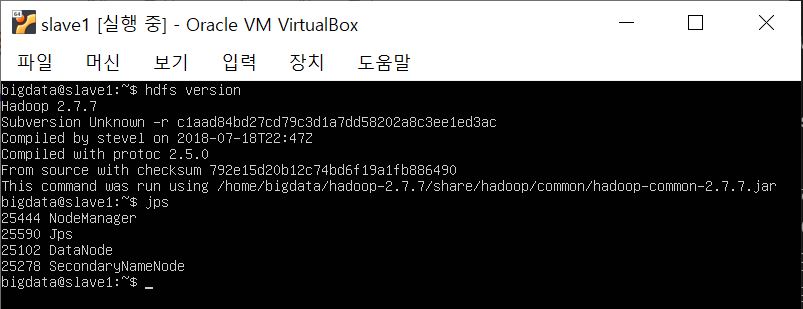
위 캡처에서 보는 바와 같이 하둡 버전이 2.7.7인 것을 확인했으며, 마스터에서는 자원관리자 resource manager, nodemanager, datanode, namenode가 확인되어야 마스터 노드로서 역할하는 것이고요, 슬레이브에서는 datanode, 보조 네임노드인 secondarynamenode, nodemanager가 떠야 정상 동작하게 됩니다.
네임노드에 웹으로 접속하여 확인해봅시다.
http://192.168.0.1:50070으로 접속하여 확인합니다! 즉, nat 테이블상의 192.168.0.200으로 접속합니다!
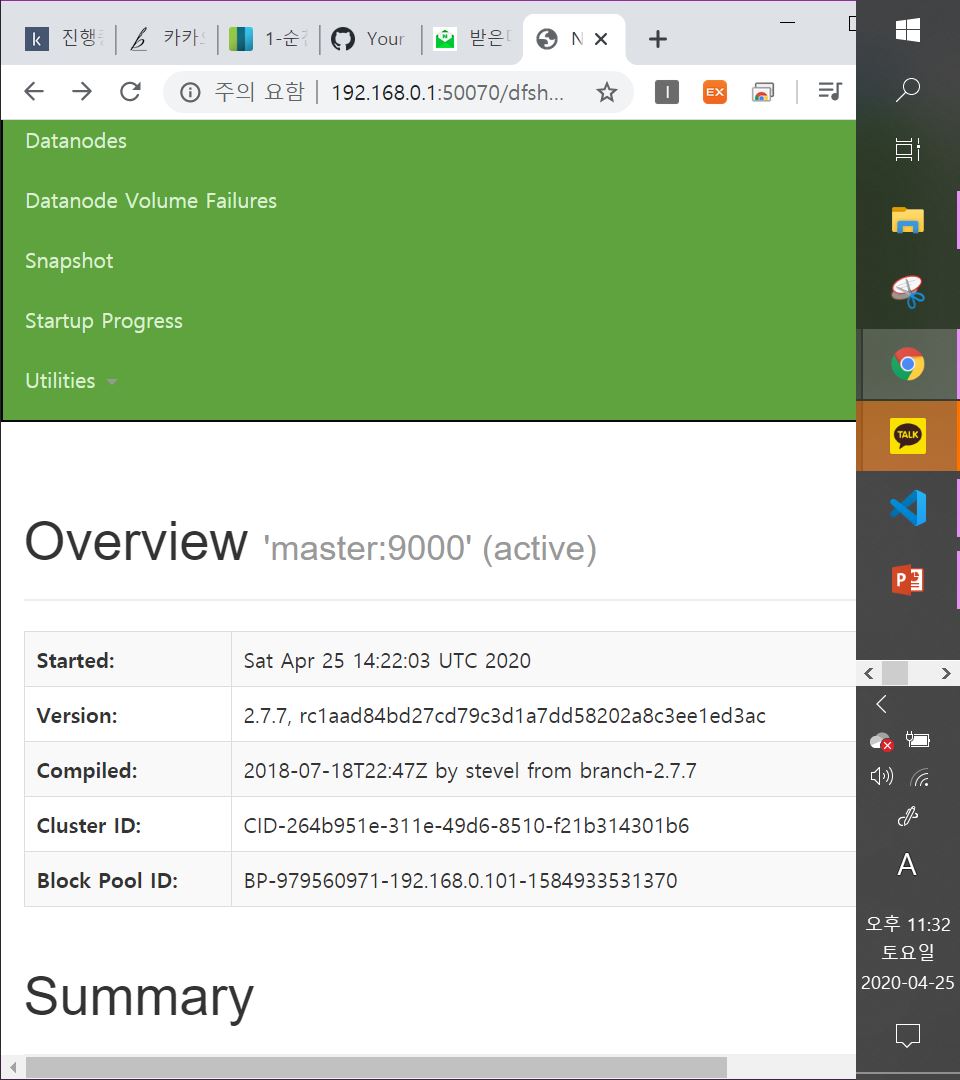
상단 메뉴 중에서 Datanodes 탭에서는 동작 중인 데이터 노드들을 확인하실 수 있으며, Utilities 탭에서는 HDFS 파일내용들도 보실 수 있습니다.
하둡 명령 형식은 아래와 같습니다.
hadoop fs -command [arg ...]
또는
hdfs dfs -command [arg ...]
인데요, 특정 명령어들은 특정 인터프리터에서만 되기도 하지만, 우리는 첫 번째 방식을 주로 사용하도록 하겠습니다.
테스트로 wordcount 앱 실습을 해봅시다.
HDFS 루트에 input 디렉토리를 생성해주세요.
hadoop fs -ls /
hadoop fs -mkdir /input
로컬 파일인 README.txt를 HDFS /input에 복사합니다.
hadoop fs -put /home/bigdata/hadoop-2.7.7/README.txt /input
hadoop fs -ls /input
wordcount 예제를 실행하고 실행 결과를 출력합니다.
hadoop jar /home/bigdata/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /input/README.txt /ouput
hadoop fs -cat /ouput/part-r-00000
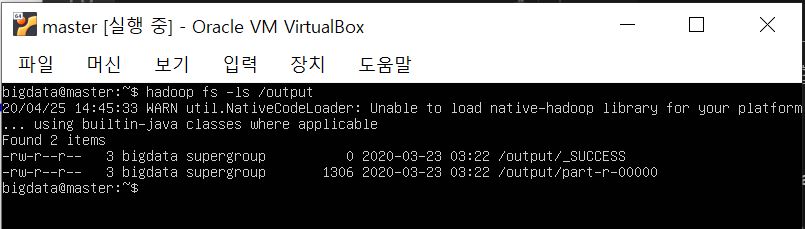
(버박으로 확인하니 잘린 부분 확인이 번거로워서 putty로 접속해서 part-r-00000 내용은 출력했습니다.)
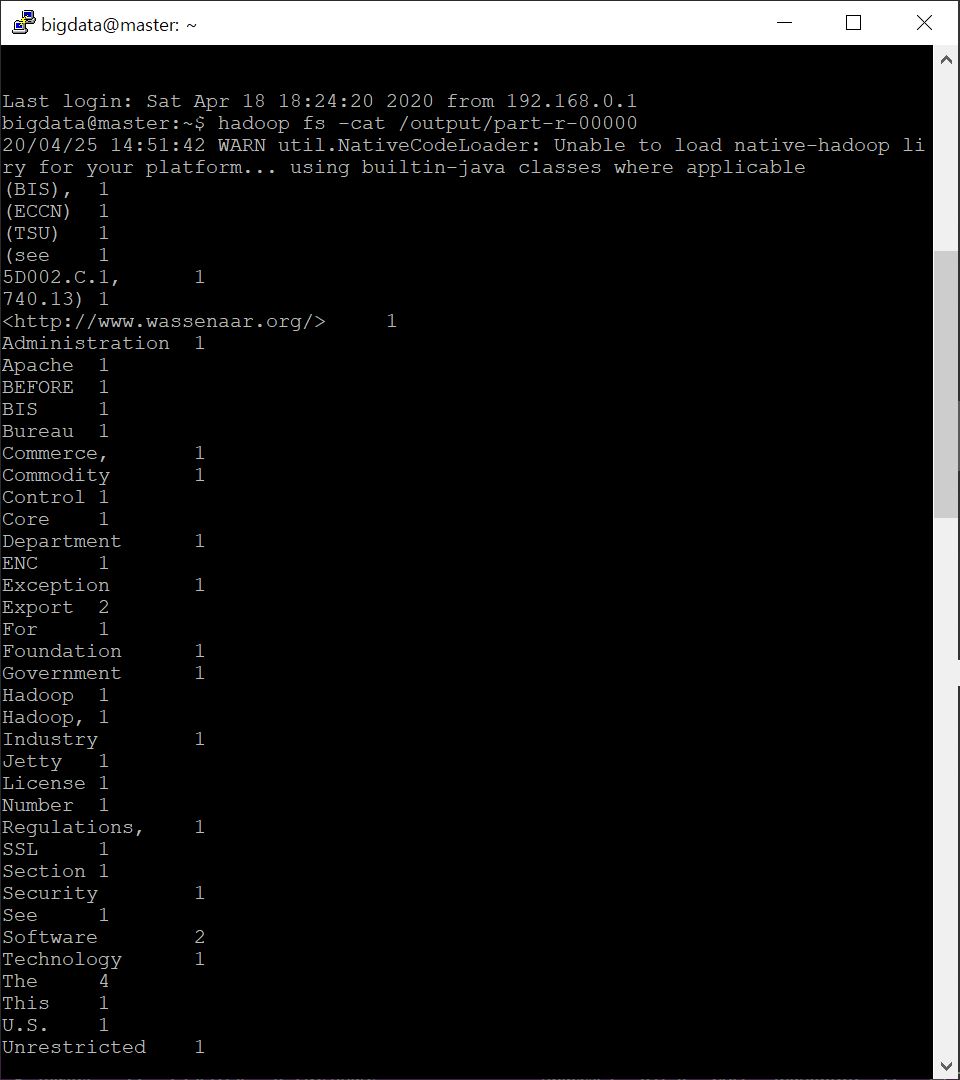
잘 나왔네요 ㅎㅎ.
YARN 자원 관리자를 웹으로 볼 수도 있습니다.
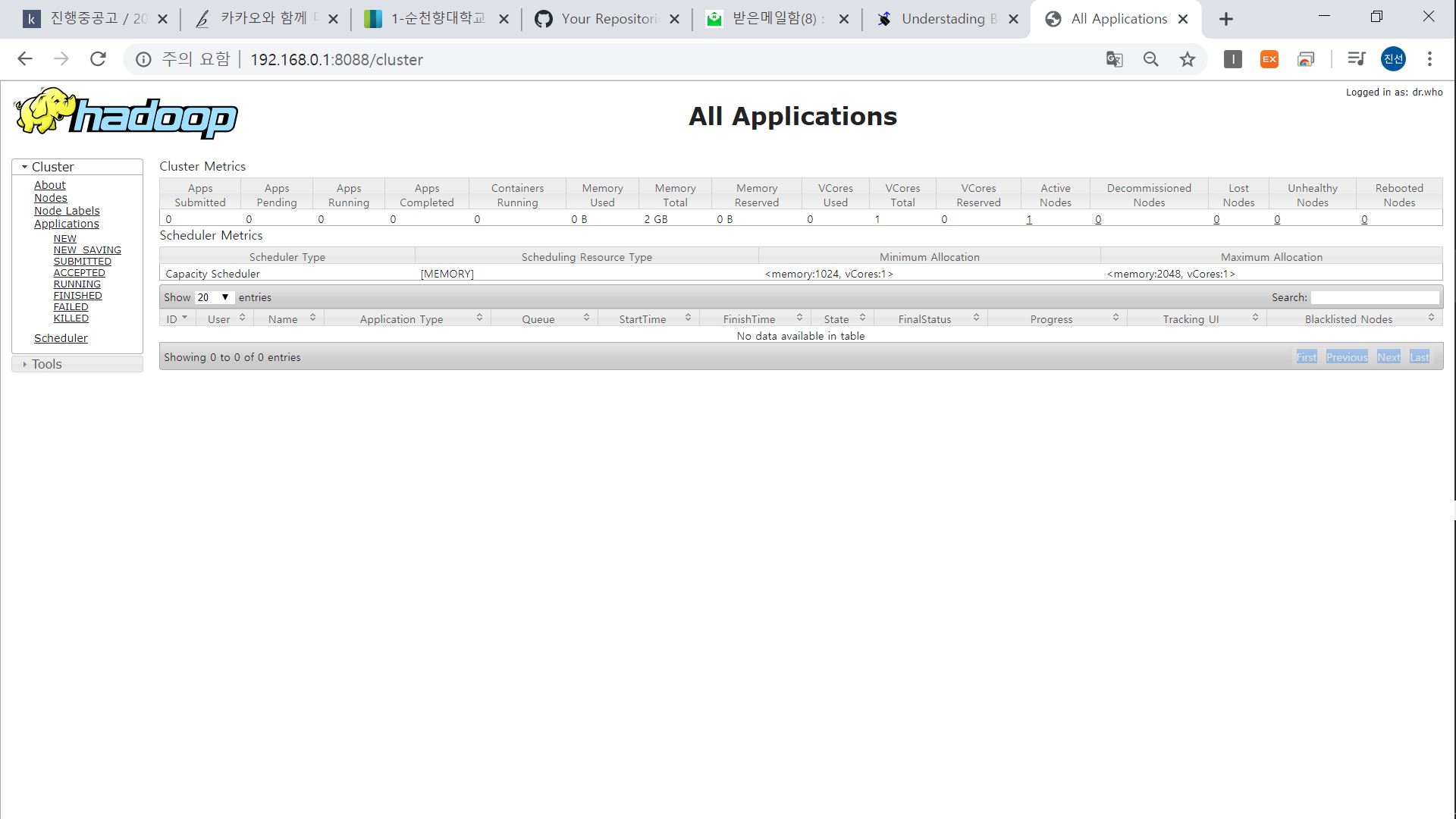
특정 프로세스가 돌고 있을 때 웹브라우저로 yarn 자원관리를 확인해보면 그 프로세스가 뜨겠지요?
이번 학습은 여기서 끝났지만 저는 readme.txt가 아닌 다른 임의의 데이터에 대해서도 wordcount 맵리듀스 프로그램을 실행하는 과제를 해보려고 합니다!
종료할때 꼭!!!! 잊지말고 하둡 종료 명령어 입력하고 끄세요~~!
개인이 공부하고 포스팅하는 블로그입니다. 작성한 글 중 오류나 틀린 부분이 있을 경우 과감한 지적 환영합니다!