
Intro of Spark-Understading BigData(8)
Intro
학교 수강과목에서 학습한 내용을 복습하는 용도의 포스트입니다.
빅데이터 개념과 오픈소스인 아파치 하둡과 맵리듀스 및 스파크를 이용한 빅데이터 적용을 공부합니다.
맵 리듀스의 경우 사용하기에 다소 진입장벽이 있는편입니다.
스파크처럼 통합 환경을 제공하지 않아 원하는 유틸리티나 라이브러리를 별도로 연결해서 사용해야하기 때문입니다. 이를 해소하는 것이 스파크라는 분산 데이터 처리 통합 엔진입니다.
따라서 맵 리듀스로 먼저 공부해보고, 스파크로 넘어갑니다.
스파크 엔진의 경우 Java가 아닌 Scalar라는 언어로 사용하며, 기존 우리가 알고 있는 SQL을 통해 고급 질의가 가능하며, 시각화나 스트림 처리 및 기계학습등 까지의 높은 수준의 분석을 제공하는 통합 프레임 워크입니다.
빅데이터 컴퓨팅(분산시스템상의 분산처리 환경)의 기본 개념과 원리를 이해하고 이를 실습해보는 과정에서 2대 이상의 리눅스 클러스터 서버를 구축 및 활용할 것입니다.
빅데이터이해(1) 보러가기
빅데이터이해(2) 보러가기
빅데이터이해(3) 보러가기
빅데이터이해(4) 보러가기
빅데이터이해(5) 보러가기
빅데이터이해(6) 보러가기
빅데이터이해(7) 보러가기
빅데이터이해(9) 보러가기
이번 시간에는 아파치 스파크를 소개합니다.
Apache Spark
아파치 스파크를 소개하고 그 위에서 빅데이터를 분석하는 내용으로 실습해볼 예정입니다.
맵리듀스가 하둡 프레임워크상에서 분산처리하는 기본시스템이지만, 맵리듀스를 사용하게되면 몇가지 어려움이 있습니다.
예를 들어서 머신러닝이나 스트리밍 처리 또는 SQL을 이용해서 데이터 조회를 한다거나 할 경우 다른 여러 에코시스템을 연계해서 실행해줘야합니다.
에코시스템 한 응용의 결과값을 하둡파일시스템에 저장을 하고 다시 그 저장된 내용을 가져와서 다른응용이 처리를 해야하기 때문에 성능에 문제가 있습니다.
또한 자바를 사용해서 맵리듀스의 템플릿을 이용한 프로그램 작성은 쉽지가 않았습니다.
따라서 이와 같은 문제를 해결하기 위해서 하나의 통합 프레임 워크 상에서 하나의 언어로 작성하고 메모리상에서 실행시킴으로서 성능도 향상시켜주는 스파크라는 시스템을 학습할 겁니다.
가장 먼저 스파크를 소개하고 하둡 얀 상에서 스파크를 설치하는 내용을 살펴보도록 하겠습니다.
아파치 스파크는 분산 데이터처리를 위한 통합 엔진입니다.
기존의 맵리듀스를 확장해서 각기 독립적인 엔진(에코시스템)들이 수행했던 것들을 처리 컴포넌트들을 통합시켜주지요.
스파크는 중요한 특징이 몇가지 있습니다.
첫 번째 특징은 바로 빠른 성능입니다.
기존의 맵리듀스만을 사용하게 될 경우 한 컴포넌트들의 결과를 HDFS와 같은 저장소에 출력하고, 다른 컴포넌트가 이를 읽어 들여 다음 처리를 하게 되었으므로 상당히 느렸습니다. 하지만 스파크는 메모리에 상주하는 동일한 데이터 상에서 컴포넌트들이 다양한 함수를 수행할 것이기 때문에 빠릅니다.
스파크는 디스크 상에서 10배, 메모리 상에서는 100배 이상 빠른 성능을 달성합니다.
두 번째 특징은 개발의 편의성입니다.
맵리듀스보다 풍부한 연산을 제공하며, 라이브러리도 많이 제공하고 있는 스파크는 비교적 적은 코드로 알고리즘을 구현할 수 있으며, 고난도 데이터 처리 알고리즘의 신속한 구축이 가능합니다.
뿐만 아니라 스칼라와 파이선 등을 사용한 대화형쉘을 제공하므로 개발 테스트와 디버깅에 용이합니다.
세 번째 특징은 유연한 실행 환경입니다.
하둡 빅데이터 환경에서 실행가능합니다.(YARN 환경에서 HDFS, MapR-FS, HBase, HIVE) 등에 저장된 데이터 처리가 가능하지요.
아파치 Mesos(오픈소스 클러스터 관리자), 아마존 S3(스토리지 서비스) 등 다양한 실행 환경을 지원합니다.
또한 단일 컴퓨터에서나 로컬에서도 실행이 가능합니다.
네 번째 특징으로는 통합개발환경이 제공된다는 점입니다.
그래프처리나 고급 질의, 스트림 처리, 기계학습 등과 같은 고수준 분석 도구를 위한 통합 프레임워크가 서비스되고 있습니다.
통합 개발환경을 통해 전체 작업 과정에서 단일 프로그래밍 언어를 사용하여 하나의 응용으로 이들 라이브러리들의 결합이 가능하다는 강력한 장점이 있습니다.
다섯 번째 특징으로는 스칼라, 파이선, 자바, SparkR이라는 언어 등 다양한 언어를 지원하고 있습니다.
스파크는 IoT나 App들 또는 Web service의 데이터들 따위로부터 데이터 소스를 받아들여서 Extract Transfom Load Processing을 거친 후 Stream Processing, Machine Learning, Queries, Graph Processing 등의 분석을 하게 될건데, 이 때 각 과정들에서 사용이 가능한 라이브러리들을 간단히 소개하는 사진을 첨부해드리겠습니다.
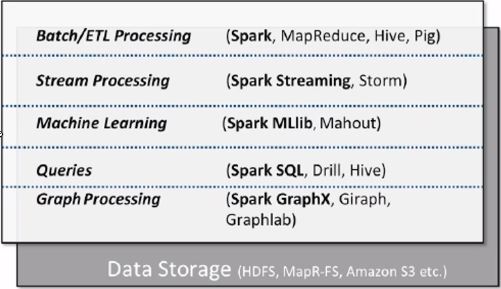
이렇게 분석이 되어 사용자에게는 대시보드 형태나 Enterprise Data Warehouse, Query/Advanced Analytics 등의 용도로 활용되게 되지요.
스파크 사용 사례
-
OLAP(OnLine Analytical Processing) 분석
서비스 제공자가 스파크를 사용하여 실시간으로 다차원 OLAP 분석을 할 수 있습니다.
특히 데이터 웨어하우스에서 많이 사용되는데, 빅데이터를 가지고 다차원 데이터 분석을 지원하는 것이 OLAP입니다.
의사결정 지원 시스템으로서 동일한 데이터를 여러 각도로 분석하게 됩니다. 어떤 형식의 데이터도 수집하여 처리 가능하며 1에서 2TB 까지의 대규모 데이터 분석을 하게 됩니다. -
운영 분석(Operational Analytics)
예를 들어 보험회사는 의료기록과 함께 환자 정보를 저장해두고 스파크가 환자의 재입원 확률을 계산하며 NoSQL을 사용하여 실시간 분석을 하게 됩니다. 재입원 확률이 높은 경우에는 재택 간호 등과 같은 부가 서비스를 제공합니다. -
복잡한 데이터 파이프라이닝
제약 회사에서 유전자 염기서열 분석에 스파크를 사용하기도 했습니다.
스파크 상에서 수행되는 ADAM 툴을 사용하여 염기서열의 일치여부 분석 처리에 몇 주 걸리는 작업을 수 시간만으로 단축시킬 수 있었지요. 맵리듀스를 사용하지 않고 복잡한 기계학습을 구현했습니다. -
배치 처리(Batch Processing)
로그 파일과 같은 원시 데이터 형식을 좀 더 구조화된 데이터 형식으로 변환하는 ETL 워크로드 등과 같은 대용량의 데이터 세트를 사용하는 배치 처리에 활용될 수 있습니다.
예를 들어 Yahoo의 개인화된 페이지 추천이나 Goldman Sachs에서 데이터 레이크 관리, Alibaba의 그래프 마이닝, Riusk Calculation의 Financial Value, Toyota의 고객의 피드백에 대한 텍스트 마이닝 등이 있습니다.
가장 큰 대규모 활용사례로는 Chinese social network Tencent의 8000개 노드의 클러스터 사용사례가 있습니다. 매일 1PB의 데이터를 수집하게 됩니다. -
스트림 처리(Stream Processing)
실시간 분석 및 의사 결정 응용 등에서 요구되는 실시간 처리를 효율적으로 구현하기 위해 스파크가 사용되기도 했습니다.
예를 들어 Cisco의 네트워크 보안 모니터링, 삼성 SDS의 처방전 분석, Netflix의 로그 마이닝 등에 활용되었습니다.
많은 응용들이 스트리밍을 구현할 때 배치와 상호작용 질의와 결합하여 사용하는데요, Conviva라는 비디오 회사는 콘텐츠 분배 서버의 성능 모델을 계속 유지보수하면서, 클라이언트들의 서버들 간에 이동하는지 여부의 질의 처리를 병렬로 수행하는 응용에 스파크를 사용하였습니다. -
과학 응용(Scientific applications)
대규모 스팸 검출이나 이미지 프로세싱, 게놈 데이터 처리 등의 과학 영역에도 스파크가 활용됩니다.
참고로 배치와 상호 작용 및 스트림 처리를 결합하여 사용하는 응용 예로는 Howard Huges Medical Institute의 신경 과학용 Thunder 플랫폼이 있습니다.
실시간으로 뇌의 이미지 데이터를 처리하도록 설계되었으며, 특정 열대어, 생쥐 등의 전체 뇌 이미지 데이터 처리에 최대 1TB/hour 속도로 처리합니다.
과학자들은 Thunder를 사용해서 특정 동작에 관여하는 뉴런을 확인할 수 있습니다. Thunder에는 클러스터링과 주성분분석 기법을 적용해 특정 동작에 관여하는 뉴런을 구분하는 기계학습 모델이 구현되어 있습니다.
스파크 컴포넌트
스파크의 내부 구성 및 동작 원리를 살펴보겠습니다.
스파크 응용의 주요 구성 요소는 클러스터 관리자(cluster manager)와 드라이버 프로세스(driver), 실행자 프로세스(executor) 입니다.
클러스터 매니저는 자원을 관리하는 역할을 합니다. 마치 YARN에서의 resource manager와 같은 역할이지요.
드라이버 프로세스는 스파크 세션을 생성하여 응용을 관리합니다. 각 분산 컴퓨터에 실행될 executor에게 응용을 배부합니다. 즉 작업을 스케줄링하고 실행된 결과를 분석하는 것이 드라이버 프로세스입니다.
실행자 프로세스는 각 분산노드에 실제 할당된 프로세스를 말합니다.
- 클러스터 관리자
- 스파크 응용의 자원을 할당하고 머신을 관리
- 스파크 응용의 자원을 할당하고 머신을 관리
- 드라이버 프로세스
- SparkSession 인스턴스를 생성하여 관리
- 스파크 응용에 관한 정보 관리
- 사용자 프로그램 응답
- 작업을 분석하고 실행자 프로세스들에 분산하고 스케줄링
- SparkSession 인스턴스를 생성하여 관리
- 실행자 프로세스
- 드라이버가 할당한 코드를 실행
- 계산의 상태를 드라이버에 보고
- 드라이버가 할당한 코드를 실행
프로그래밍 언어 API
스파크는 다양한 프로그래밍 언어의 API를 제공합니다.
- 스칼라(Scala)
- 스파크는 스칼라 언어로 구현되었고, 스파크의 디폴트 프로그래밍 언어
- JVM 위에서 실행되는 언어입니다.
- 스파크는 스칼라 언어로 구현되었고, 스파크의 디폴트 프로그래밍 언어
- 파이선(Python)
- 스칼라와 거의 유사할 정도로 파이선을 지원
- 스칼라와 거의 유사할 정도로 파이선을 지원
- SQL
- 데이터 프레임(dataframe) 자료에 대해 SQL 사용
- 데이터 프레임(dataframe) 자료에 대해 SQL 사용
-
JAVA
- R
- 통계 계산 프로그래밍에 사용되는 언어
- 통계 계산 프로그래밍에 사용되는 언어
스파크 데이터세트
데이터세트는 스파크의 기본 추상화로서 클러스터의 노드들에 분산된 객체들의 컬렉션입니다.
데이터를 분산할 뿐만 아니라 데이터세트 상에서 연산까지 수행합니다.
중요한 특징이 있습니다. 바로 immutable인데요, 데이터세트가 생성된 후에는 변경 불가능합니다.
동기화의 복잡성 때문에 이러한 특징이 생겼다고 설명했었습니다.
그리고 데이터세트는 디스크 또는 메모리 상에서 저장 및 캐싱되며, 한 노드의 태스크가 실패하게되면 나머지 노드에서 자동으로 재구축되어 작업을 완료하는 fault tolerant 특징도 있습니다.
데이터세트의 기본 연산은 아래와 같습니다.
데이터세트 상에서 변환(transformation)과 액션(action)을 수행하는데, 기존의 데이터세트를 변환하여 새로운 데이터세트를 생성합니다. 액션은 수행된 결과 값을 리턴합니다.
수정이 불가능하기 때문에 변환과 액션을 임의의 순서로 결합하여 데이터를 처리하고 분석합니다.
스파크 라이브러리
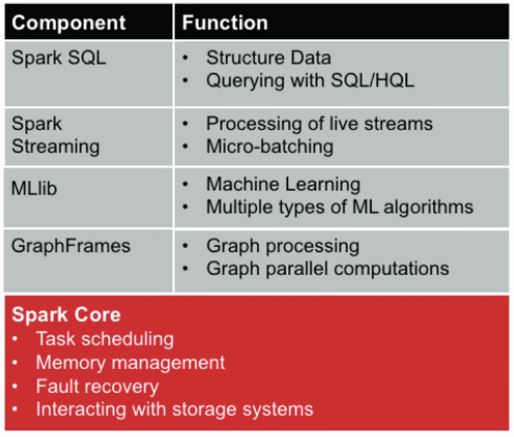
스파크 코어는 태스크 스케줄링, 메모리 관리, 고장 복구, 저장 시스템 접근 등을 수행하는 계산 엔진을 말합니다. 분산 컬렉션 객체인 데이터세트를 정의하고 관리하는 API도 포함합니다.
스파크 SQL은 구조화된 데이터(Hive 테이블, 복잡한 JSON 데이터 등) 상의 작업을 수행합니다.
스파크 스트리밍은 데이터 스트림들을 처리하고 실시간 분석을 지원합니다.
MLib는 분류, 회귀분석, 클러스터링 등의 다양한 머신러닝 알고리즘을 내장하고 있습니다.
그래프프레임은 그래프 관련 병렬 계산을 수행하는 라이브러리입니다.
하둡 YARN에서 스파크 설치
스파크 실행모드는 아래와 같습니다.
- 로컬모드(local mode) : 로컬머신 하나의 JVM에서 실행
- 독립형모드(standalone mode) : 독립적인 클러스터 상에서 실행
- 하둡 YARN : 하둡 YARN 상에서 실행
- 아파치 Mesos : 아파치 Mesos 자원 관리자 상에서 실행
이 중에서 저희는 하둡 YARN 상의 설치를 소개합니다.
1.스파크 다운로드 및 압축 해제
마스터 노드에서 설치한 후에 슬레이브 노드에 복사합니다.
스파크 2.4.5 설치를 진행합니다.
스파크 다운로드 경로 : http://spark.apache.org/downloads.html
제플린 노트북과의 연동 호환성을 고려해서 위 버전을 사용한 것입니다.
우리 수업에서 다루게되는 환경에서 설치 디렉토리는 아래와 같습니다.
~/spark-2.4.5-bin-hadoop2.7
편의에 따라서 아래 리눅스 명령어를 입력해 다운로드를 실행하셔도 좋습니다.
wget http://mirror.apache-kr.org/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz
압축 해제도 진행해주세요.
tar -xvzf spark-2.4.5-bin-hadoop2.7.tgz
2.환경 변수 설정
하둡 환경변수 설정이 필요합니다.
home 디렉토리 아래에 있는 .bashrc에 아래 내용을 추가해주세요.
#Spark Path
export SPARK_HOME=$HOME/spark-2.4.5-bin-hadoop2.7
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.7-src.zip:$PYTHONPATH
export PYSPARK_PYTHON=python3
추가하셨다면 아래 명령어를 통해 적용해주세요.
source ~/.bashrc
3.스파크 설정 : 설정 파일 복사
기존 스파크 설정 파일들 복사 & 변경
경로는 (Home)/spark-2.4.5-bin-hadoop2.7/conf입니다.
slaves.template과 spark-defaults.conf.template, spark-env.sh.template 등의 템플릿 파일들을 제공하는데 이들을 복사할 겁니다.
아래 명령어를 입력해주세요.
cp slaves.template slaves
cp spark-defaults.conf.template spark-defaults.conf
cp spark-env.sh.template spark-env.sh
그 다음은 스파크 환경변수 설정입니다.
경로는 (Home)/spark-2.4.5-bin-hadoop2.7/conf/spark-env.sh입니다. 아래 내용을 추가해주세요.
export HADOOP_CONF_DIR=${HADOOP_DIR}/etc/hadoop
export SPARK_WORKER_MEMORY=2g
추가하셨다면 아래 명령어를 입력해 활성화해주세요.
source ~/spark-2.4.5-bin-hadoop2.7/conf/spark-env.sh
4.스파크 설정 : 설정 파일 변경
그 다음 스파크 설정 파일을 변경해줍니다.
경로는 (Home)/spark-2.4.5-bin-hadoop2.7/conf/spark-defaults.conf입니다.
spark.master spark://master:7077
spark.yarn.jars hdfs://master:9000/jar/spark-jars/\*.jar
그 다음, 스파크 슬레이브 설정도 해줍니다.
경로는 (Home)/spark-2.4.5-bin-hadoop2.7/conf/spark-defaults.conf입니다.
slave1
5.스파크 설정 : jar 파일 적재
하둡을 실행하고 모든 스파크의 자바 아카이브 파일들을 하둡의 파일 시스템으로 적재해줍니다.
--master yarn 모드 실행을 위한 작업입니다. 아래 명령어를 입력해주세요.
hadoop fs -mkdir /jar
hadoop fs -mkdir /jar/spark-jars
hadoop fs -put $SPARK_HOME/jars/* /jar/spark-jars/
여기까지 다하셨다면 웹으로 하둡에 접속하여 파일이 잘 복사되었는지 확인해줍니다.
http://192.168.0.1:50070이었지요..
물론 ls명령으로도 확인 가능합니다.
6.스파크 설정 : 스파크 배포
각 서버로 스파크 설치 디렉토리를 배포합니다.
아래 명령어를 입력해주세요.
scp .bashrc slave1:~/
scp -r ~/spark-2.4.5-bin-hadoop2.7 slave1:~/
설치가 완료되었다면 스파크를 실행해보고 동작을 확인합니다.
스파크 실행 및 동작 확인(via jps)
스파크를 실행하기 위해 아래 명령어를 입력해주세요.
$SPARK_HOME/sbin/start-all.sh
참고로 스파크 중지 명령어는 아래와 같습니다.
$SPARK_HOME/sbin/stop-all.sh
실행 이후에는 jps 명령어를 통해 Master와 Worker가 잘 켜졌는지 확인해주시면 됩니다.
스파크 실행이 잘 되었는지 확인은 jps 명령어 뿐만 아니라 웹에서도 확인 가능합니다.
스파크 마스터 포트로 즉 192.168.0.1:8080으로 웹 접속하여 확인하시면 됩니다.
스파크 쉘
스파크 쉘은 사용자와 상호작용하며 프로그램 작성이 가능합니다.
스칼라 또는 파이선 쉘이 제공되어 마스터, 슬레이브 노드 어디서나 실행 가능합니다.
쉘이 시작되면 드라이버에 의해 스파크 세션 객체가 초기화면서 변수 spark가 이를 가리킵니다.
앞서 스파크세션은 한 응용의 클러스터 연결 접근 방식을 관리한다고 설명했었습니다.
실행환경 옵션은 --master이며 하둡 클러스터는 --master yarn, 로컬 PC는 --master local[N] 입니다.
N은 실행할 스레드 수를 말하며 *로 지정할 경우 가용한 CPU 코어 개수로 자동으로 지정됩니다.
클러스터 실행에 대한 예 명령어는 아래와 같습니다.
$SPARK_HOME/bin/spark-shell --master yarn
실행하게 되면 프롬트가 scala로 바뀌는 것을 확인하실 수 있을 겁니다.
종료를 원하실 경우 quit을 입력하시면 됩니다.
이 역시 YARN 웹 192.168.0.1:8088에서 확인 가능합니다.
우리가 가상 머신 실습 시작 및 종료 시 주의할 사항이 있습니다.
실습을 시작할 경우 아래 순서를 반드시 기억해주세요.
- 마스터, 슬레이브 가상 머신 시작
- 가상 머신 마스터 로그인
- 마스터에서 하둡 시작 : start-all.sh
- 마스터에서 스파크 시작 : SPARK_HOME/sbin/start-all.sh
- putty로 마스터 연결하여 putty 콘솔에서 실습
실습을 종료할 경우 더 중요합니다. 아래 순서를 준수해주시기 바랍니다. 안그러면 시스템이 깨질 수 있어요.
- 마스터에서 스파크 종료 : SPARK_HOME/sbin/stop-all.sh
- 마스터에서 하둡 종료 : stop-all.sh
- 마스터/슬레이브 가상 머신 종료 : 저장 또는 전원끄기
오류가 발생하면 상황에 따라서 복구를 할 수도 있고 재설치해야할 수도 있습니다.
오류 복구 절차 하나를 공유해드리겠습니다.
- 스파크 종료 : SPARK_HOME/sbin/stop-all.sh
- 하둡 종료 : stop-all.sh
- 하둡 데이터 디렉토리 삭제 : rm -r $HADOOP_HOME/hdfs/data
- 하둡 재시작 : start-all.sh
- 하둡 포맷 : hadoop namenode -format (물론 기존 하둡데이터는 모두 삭제됩니다.)
- jar 파일 복사 : hadoop fs -mkdir /jar 그 다음 hadoop fs -mkdir /jar/spark-jars 그 다음 hadoop fs -put$SPARK_HOME/jars/* /jar/spark-jars/ 를 차례로 입력해주세요.
- 스파크 시작 : SPARK_HOME/sbin/start-all.sh
개인이 공부하고 포스팅하는 블로그입니다. 작성한 글 중 오류나 틀린 부분이 있을 경우 과감한 지적 환영합니다!