
How to increase datas, Data Augmentation
개인적으로 수어 지문자 번역 시스템 프로젝트를 하면서 자가 데이터 확보 방법을 선택했는데, 31가지의 지문자를 일일이 찍자니 45장씩만 찍었는데도 참 고된 작업이었습니다.
하지만 고된 것은 고된 것이고 ㅠ 좋은 성능을 기대하기엔 현저히 데이터 수가 적습니다.
그래서 회전, 확대, 이동 등의 어파인 변환을 통해 데이터를 부풀려 주는 과정을 기록하고자 합니다.
조금 변형된 사진의 경우 사람이 보기엔 같은 사진일지라도 컴퓨터는 서로 다른 사진으로 인식하게될 것이므로 데이터 수가 많아지면 성능이 높아질 뿐 아니라, 제 프로젝트에 국한시킨 장점을 설명하자면.. y축 대칭이동만 하더라도 왼손잡이의 수어 사용을 고려할 수 있다는 장점이 생기니까요!!
이 블로그를 참고하여 포스팅합니다.
Data Augmentation
CNN 성능을 높이기 위해 데이터를 부풀리는 일련의 과정을 Data Augmentation이라고 합니다.
학습(혹은 테스트) 이미지를 디스크에서 읽은 후 이미지를 회전, 확대, 축소, 이동, 크롭, 채도나 노이즈를 변경하는 등 여러 방법을 통해 변형(transfrom) 한 뒤에 네트워크의 입력 이미지로 사용하는 것이지요.
즉, data augmentation이란 레이블은 그대로, 픽셀을 변화시키는 방법입니다! 변형된 데이터를 이용하여 학습을 진행합니다.
data augmentation은 과거 진행했던 화상 인식 대회인 ILSVRC에서 우승한 AlexNet 부터 거의 모든 네트워크에서 이 방법이 사용되었 듯 보편적으로 사용한다고하니 알아두면 좋을 겁니다!
그렇다면 보정 및 변환할 필터를 직접 행렬로 구현해 씌워야할까요?ㅠㅠ
ㅎ ㅎ 다행히 keras에서의 ImagedataGenerator()라는 함수가 데이터 부풀리기 기능을 제공한답니다.
아래에서부터는 이와 관련된 코드를 설명하도록 하겠습니다.
ImagedataGenerator() 응용
이 블로그를 참고하여
이렇게 빠르게 살짝만 바꿔 임시로 테스트 코드를 작성했는데요,
참고로 제 포스트들을 순서대로 쭉 따라했을 경우에 이미지를 읽어들이기 위해 pillow 라이브러리를 추가적으로 설치해야할 필요가 있었습니다.
conda install pillow
가상환경이 활성화 된 상태에서 위 명령어를 cmd에서 입력하게되면 정상적으로 설치됩니다.
이 코드는 파일로 이미지를 읽어들여 데이터 증식 후 또 다시 파일로 저장해주는 코드입니다.
중요한 부분에 대해서만 소스코드를 설명하도록 하겠습니다.
먼저 ImageDataGenerator()의 인수들을 살펴봅시다.
- rescale
- 원본 영상은 0-255의 RGB 계수로 구성되는데, 이같은 입력 값은 통상적인 학습률을 사용할 경우에 모델을 효과적으로 학습시키기엔 너무 큰 수입니다. 따라서 이 값을 1./255로 설정하게 되면 1/255배로 스케일링하여 0-1사이의 범위로 표시할 수 있도록 변환해줍니다.
- 제일 먼저 적용되는 변형이지요.
- 원본 영상은 0-255의 RGB 계수로 구성되는데, 이같은 입력 값은 통상적인 학습률을 사용할 경우에 모델을 효과적으로 학습시키기엔 너무 큰 수입니다. 따라서 이 값을 1./255로 설정하게 되면 1/255배로 스케일링하여 0-1사이의 범위로 표시할 수 있도록 변환해줍니다.
- rotation_range
- 0˚~지정각도 범위 내에서 임의로 원본 이미지를 회전시킵니다.
- 0˚~지정각도 범위 내에서 임의로 원본 이미지를 회전시킵니다.
- width_shift_range
- 전체 너비에 대해 지정 비율만 큼 수평 방향으로 원본이미지를 이동시킵니다.
- 예를 들어 전체 너비가 100이며, 이 값이 0.1이라면 0~10픽셀 내외로 이동됩니다.
- 전체 너비에 대해 지정 비율만 큼 수평 방향으로 원본이미지를 이동시킵니다.
- height_shift_range
- 전체 너비에 대해 지정 비율만 큼 수직 방향으로 원본이미지를 이동시킵니다.
- 전체 너비에 대해 지정 비율만 큼 수직 방향으로 원본이미지를 이동시킵니다.
- shear_range
- 밀림 변형으로 지정된 값만큼의 라디안 내외로 시계 반대 방향으로 밀림이 적용됩니다.
- 밀림 변형으로 지정된 값만큼의 라디안 내외로 시계 반대 방향으로 밀림이 적용됩니다.
- zoom_range
- 지정된 값만 큼 1에서 빼거나 더한 비율의 범위 사이에서 확대가 되거나 축소됩니다.
- 지정된 값만 큼 1에서 빼거나 더한 비율의 범위 사이에서 확대가 되거나 축소됩니다.
- horizontal_flip
- True일 경우 50%의 확률로 수평방향 뒤집기가 적용됩니다.
- True일 경우 50%의 확률로 수평방향 뒤집기가 적용됩니다.
- vertical_flip
- True일 경우 50%의 확률로 수직방향 뒤집기가 적용됩니다.
- True일 경우 50%의 확률로 수직방향 뒤집기가 적용됩니다.
- fill_mode
- 이미지를 변형시키면서 생기게 되는 공간을 채우는 방식을 정합니다.
- 이미지를 변형시키면서 생기게 되는 공간을 채우는 방식을 정합니다.
- 여기엔 안쓰여있지만 class_mode
- 라벨 분류 방식에 대해 지정합니다.
- 라벨 분류 방식에 대해 지정합니다.
- 기타 등등 많습니다.
flow()함수의 경우 Generator를 이용하여 변형된 이미지에 이상한 점이 없는지 확인해주는 함수입니다.
위 코드를 실행시키게되면 아래와 같은 결과를 얻게 됩니다.
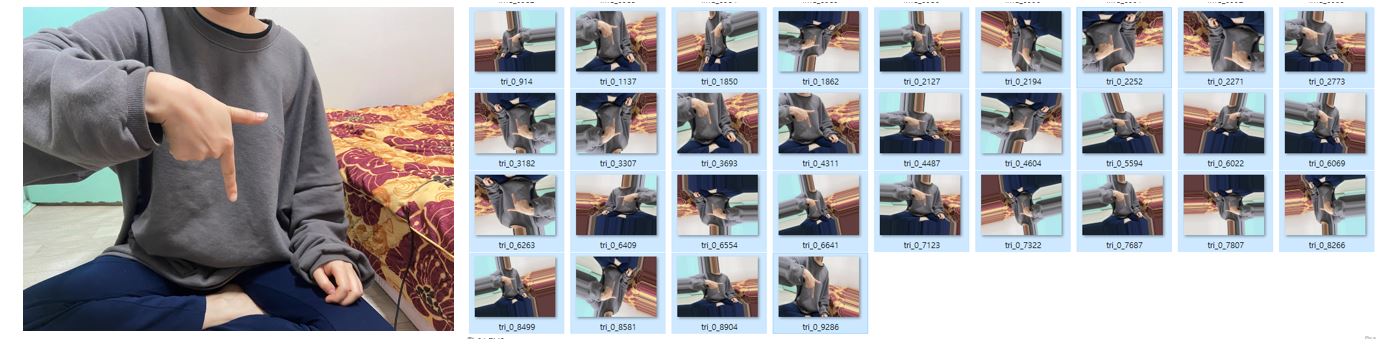
자신의 모델에 맞게 부적절하거나 불필요한 변형은 빼고 파라미터들을 조정해서 데이터를 알맞게 부풀려보도록 합니다.
저의 경우 아래와 같이 변경했습니다.

우선 제 데이터셋은 아래와 같이 객체별로 구분하여 디렉토리에 넣어뒀습니다!
그래서 위 테스트 코드는 단 한가지 사진에 대해서만 30여가지의 변형을 적용한 것이기 때문에 전체 객체별 전체 사진에 대해서 4번정도의 변형을 적용해 최소 180장 이상의 데이터를 얻도록 변경했습니다.
또한 위 아래가 뒤집힐 경우 서로 다른 의미의 지문자가 될 우려가 있어 좌우반전은 적용시키되 상하반전은 적용하지 않았답니다.
그런데 이 코드를 돌려놓고 좀 지나고 보니 메모리 에러가 나더라구용..!
그 부분은 아직 수정중입니다!
제 변경된 자세한 코드는 여기에 작성되어있습니다.
(수정중)