
How to use the Annotation Tool, YOLO_Mark for YOLO
본 포스팅은 yolo darkflowdarknet (원래 YOLO의 tensorflow 버전인 darkflow에서 사용할 목적이었는데, YOLO-mark는 openCV, C++기반이며 여기서 레이블 작업한 것을 tensorflow로 옮겨서 바로 학습 입력데이터로 넣어주기에는 annotaion 형식이 서로 다르기 때문에 결과 text 파일을 xml 형식으로 바꿔줘야한다고합니다..ㅎㅎ)로 자가학습 모델을 만드는 과정의 일부로 windows10 환경에서 자가 데이터를 resizing & labeling 하기 위해서 YOLO_Mark라는 annotation tool을 이용하는 방법을 기록합니다.
Annotation이란?
YOLO는 CNN 을 기반으로하는 Object Detection 제공 라이브러리입니다.
CNN은 지도학습의 한 종류로서 가중치 학습을 위해서는 각각의 학습이미지에 desired output, 즉 정답 레이블을 달아줘야합니다.
Object Detection의 경우는 정답 레이블은 Label명 & 경계박스의 쌍으로 구성되며 이를 Annotation이라고 합니다.
이 포스트에서는 GUI 환경의 Annotation Tool을 이용하여 레이블링 작업을 용이하게 하는 방법에 대해 기록합니다.
YOLO mark 다운로드 및 빌드
YOLO_mark 레퍼런스 및 다운로드 링크 : https://github.com/AlexeyAB/Yolo_mark
위 링크를 통해 해당 툴을 다운로드 받으신 후 압축 해제합니다.
YOLO_mark-master라는 폴더가 확인되실 겁니다. 해당 폴더 내의 솔루션 파일 yolo_mark.sln를 Visual Studio로 열어주세요!
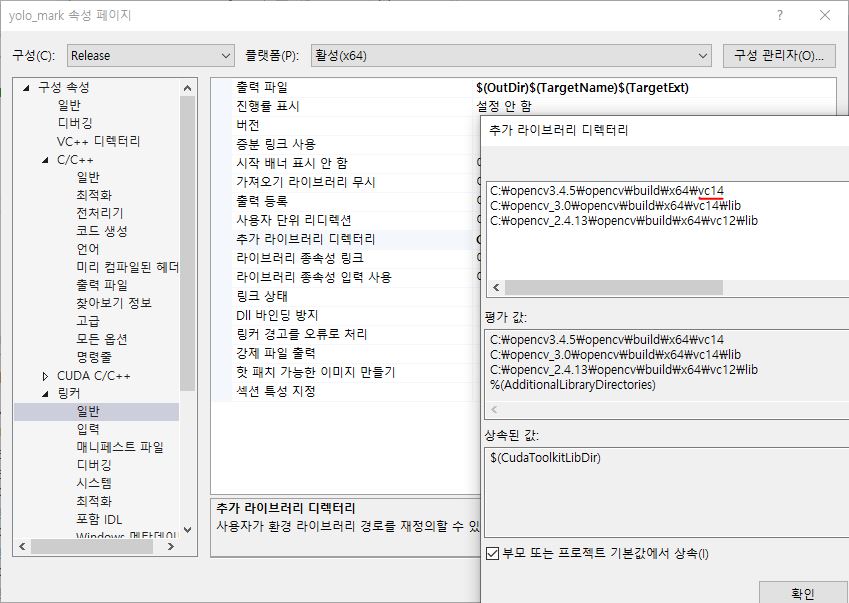
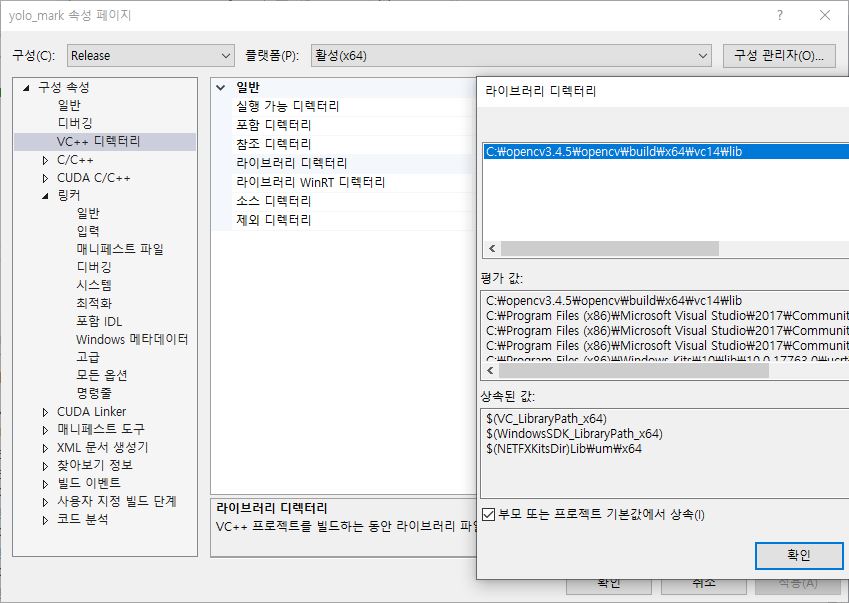
| 프로젝트가 열렸다면 프로젝트 속성의 Release | x64로 구성 및 플랫폼을 설정하여 속성을 확인하면 링커 > 일반 > 추가 라이브러리 디렉터리에 opencv 디렉토리를 추가해줘야 합니다. |
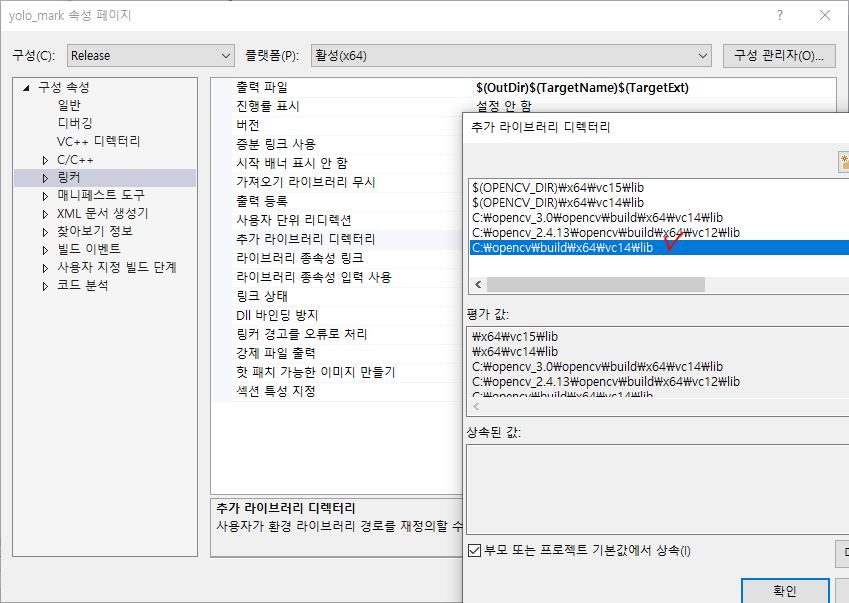
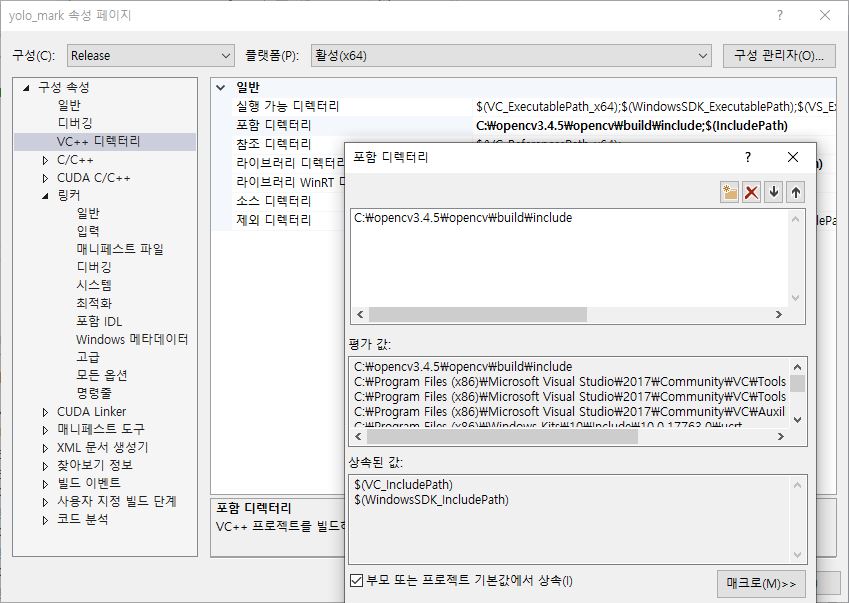
프로젝트 속성 > C/C++ > 일반 > 추가 포함 디렉터리에서도 opencv 경로를 넣어줍니다.
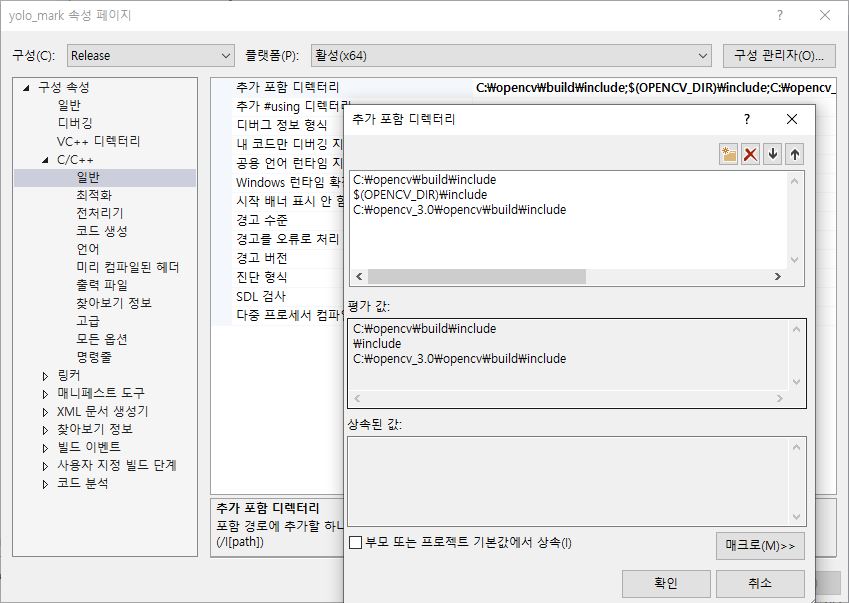
프로젝트 빌드 시에도 Release | x64로 빌드를 해줘야합니다!
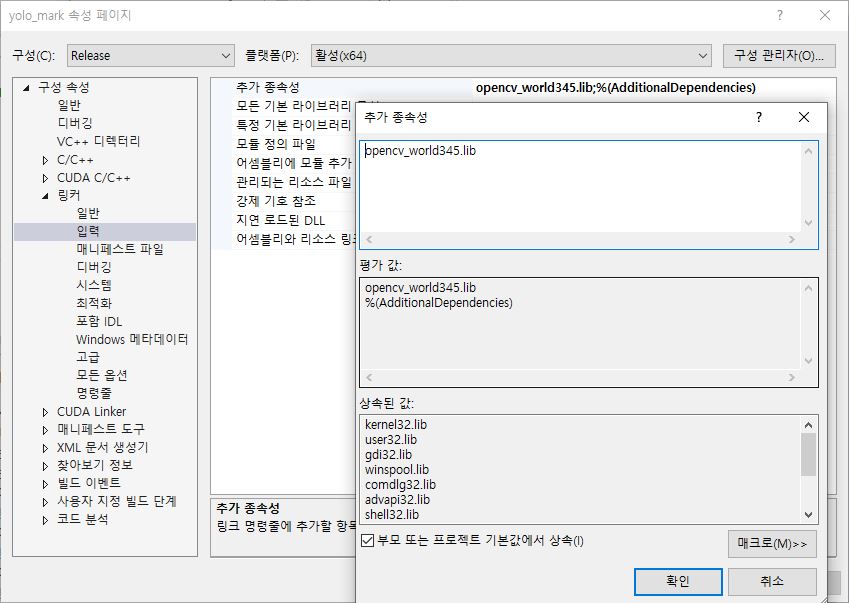
또한 링커 > 입력 > 추가 종속성에는 C:\opencv\build\x64\vc14\bin 폴더 내에 있는 dll 파일들의 목록을 작성해줘야하는데, 이 때 확장자 이름을 모두 lib로 바꾸면서 추가해줘야합니다. 아래는 그 목록입니다.
- opencv_calib3d2413d.lib
- opencv_contrib2413.lib
- opencv_contrib2413d.lib
- opencv_core2413.lib
- opencv_core2413d.lib
- opencv_features2d2413.lib
- opencv_features2d2413d.lib
- opencv_flann2413.lib
- opencv_flann2413d.lib
- opencv_gpu2413.lib
- opencv_gpu2413d.lib
- opencv_highgui2413.lib
- opencv_highgui2413d.lib
- opencv_imgproc2413.lib
- opencv_imgproc2413d.lib
- opencv_legacy2413.lib
- opencv_legacy2413d.lib
- opencv_ml2413.lib
- opencv_ml2413d.lib
- opencv_nonfree2413.lib
- opencv_nonfree2413d.lib
- opencv_objdetect2413.lib
- opencv_objdetect2413d.lib
- opencv_ocl2413.lib
- opencv_ocl2413d.lib
- opencv_photo2413.lib
- opencv_photo2413d.lib
- opencv_stitching2413.lib
- opencv_stitching2413d.lib
- opencv_superres2413.lib
- opencv_superres2413d.lib
- opencv_video2413.lib
- opencv_video2413d.lib
- opencv_videostab2413.lib
- opencv_videostab2413d.lib
주의하셔야 할 것이 여러분께서 사용하시는 opencv 버전에 따라 구성이 다른 듯 합니다. 한번 확인해보시길 권유드립니다.
빌드 실패의 경우
그런데..
제가 참고한 블로그에서는 저렇게 하면 뚝딱되던데 저는 아래와 같은 오류가 발생하면서 빌드에 실패하더군요..ㅜㅜ

그래서 구글링해본 결과 opencv 3.4.5버전을 사용함으로써 이를 해결했다고 하는 글을 보고 바로 설치를 다시하러 갔습니다.
OpenCV 3.4.5 다운로드 링크
기존의 2.4.13도 삭제하지 않고 함께 병행 사용하고싶다면 opencv 폴더 이름에 버전명을 추가해서 별도로 폴더를 구분하여 저장해도 무관합니다.
이후에 시스템 환경변수까지 등록해주시면 됩니다.
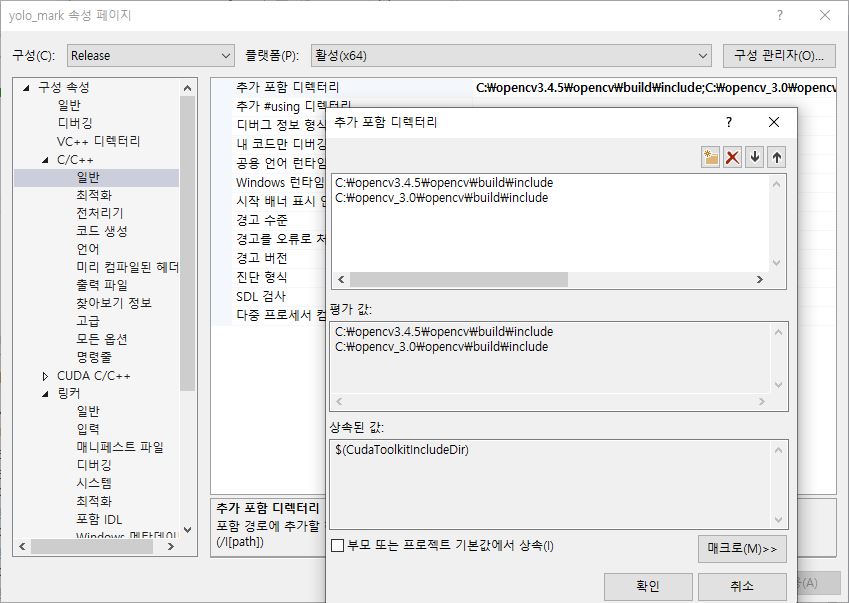
opencv 버전을 새롭게 다운받아 경로가 변경되었으니 yolo_mark 프로젝트의 속성에서도 새로운 버전의 opencv 경로로 속성들을 변경해주셔야겠지요!!
이렇게 설정을 전부 변경하고 나니 드디어 빌드가 되었는데요, Release | x64로 빌드가 성공하면 x64\Release 폴더 내에 yolo_mark.exe 파일이 생성된 것을 확인하실 수 있을 겁니다.
YOLO mark 테스트 실행
yolo_mark.exe가 아니라 yolo_mark.cmd를 더블 클릭하면 실행됩니다!
짠!
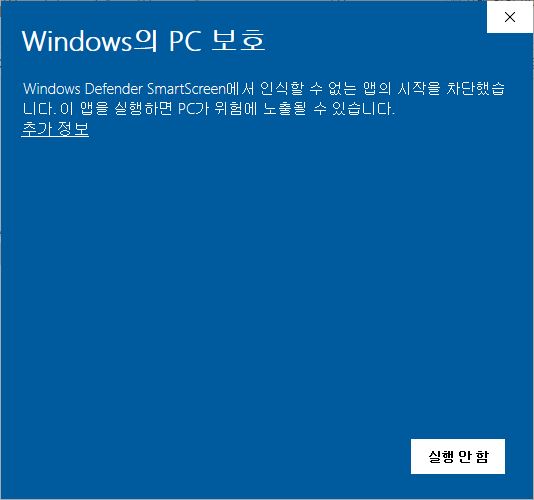
ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅠㅠ산 너머 산입니다.
혹시나 저와 같은 상황에 처하신 분들이 계시다면 해제를 하기 위해 간단하게 따라하실 수 있는 참고자료 링크를 여기에 걸어드리겠습니다.
단, 작업을 마치신 후에 다시 보안을 걸어두시길 권장합니다!
드디어 됐네요!! 매우기쁩니다. :-D
이 프로그램을 끌때에도 마찬가지로 cmd 파일을 종료해줘야합니다!
잘 실행이 되는지만 확인하신 뒤 잠시 꺼두시고, 본격적으로 labeling 작업에 들어가기 전에 사전 작업들을 해줄겁니다.
Resizing & Labeling
——
학습시키고자 하는 이미지 파일들을 Release > data > img **에 넣어줍니다.
 기존에 있는 샘플 이미지와 레이블링 작업결과인 텍스트파일을 삭제하시면 됩니다.
기존에 있는 샘플 이미지와 레이블링 작업결과인 텍스트파일을 삭제하시면 됩니다.
같은 위치에 있는 **obj.names라는 파일에는 학습시킬 객체들의 레이블명을 작성합니다. 메모장으로 열어 아래와 같이 수기로 입력합니다.

저의 경우에는 수어 지문자 번역을 위해서 한글의 자음과 모음을 입력하고 싶지만, non-ascii를 사용하면 문제가 생기는 경우를 많이 겪어보아서 그냥 ㄱ의 경우 영문 자판 그대로 r로 레이블을 달아줬습니다.
캡처처럼 각 객체의 레이블을 구분할때 개행을 넣어주면됩니다. 즉, 객체 레이블1을 작성하셨으면 엔터치고 객체 레이블2을 쓰시면 된답니다.
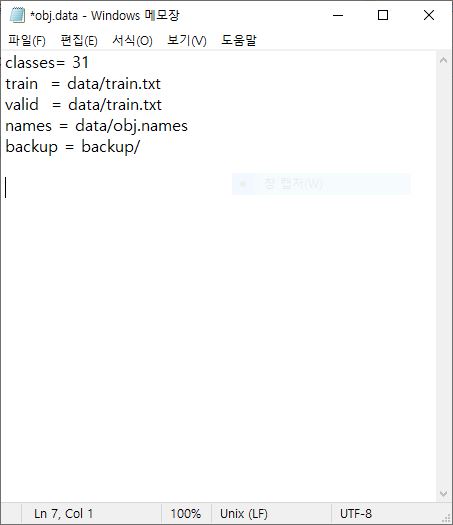
레이블명 작성을 다 하셨으면 저장 후 종료해주시고, 이번엔 obj.data라는 파일을 메모장으로 열어 classes의 수를 자신이 분류하고자 하는 객체의 종류/개수와 동일하게 변경하여 저장합니다.
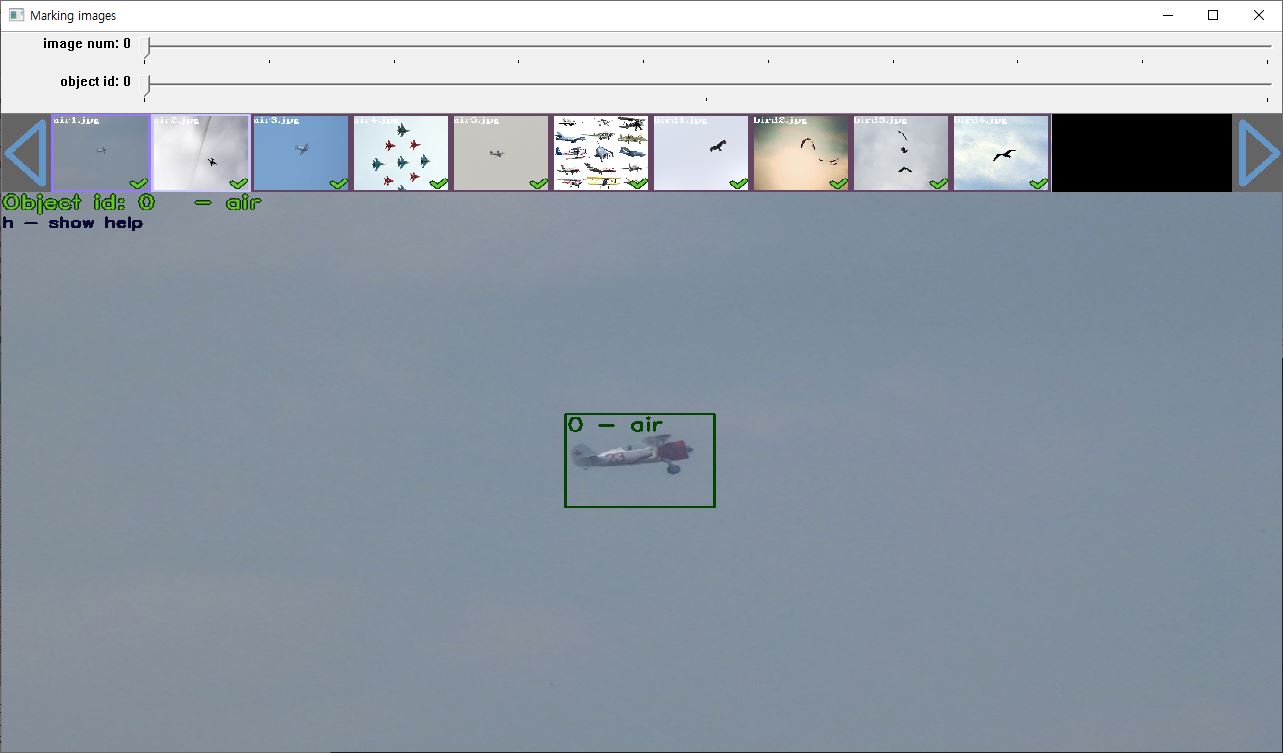
다시 yolo_mark.cmd를 실행시킵니다.
아래처럼 조금 전에 img 폴더에 넣어둔 자가 데이터가 확인되실건데요, 단축키 h를 누르면 설명이 나오니 보고 따라하시면 됩니다.
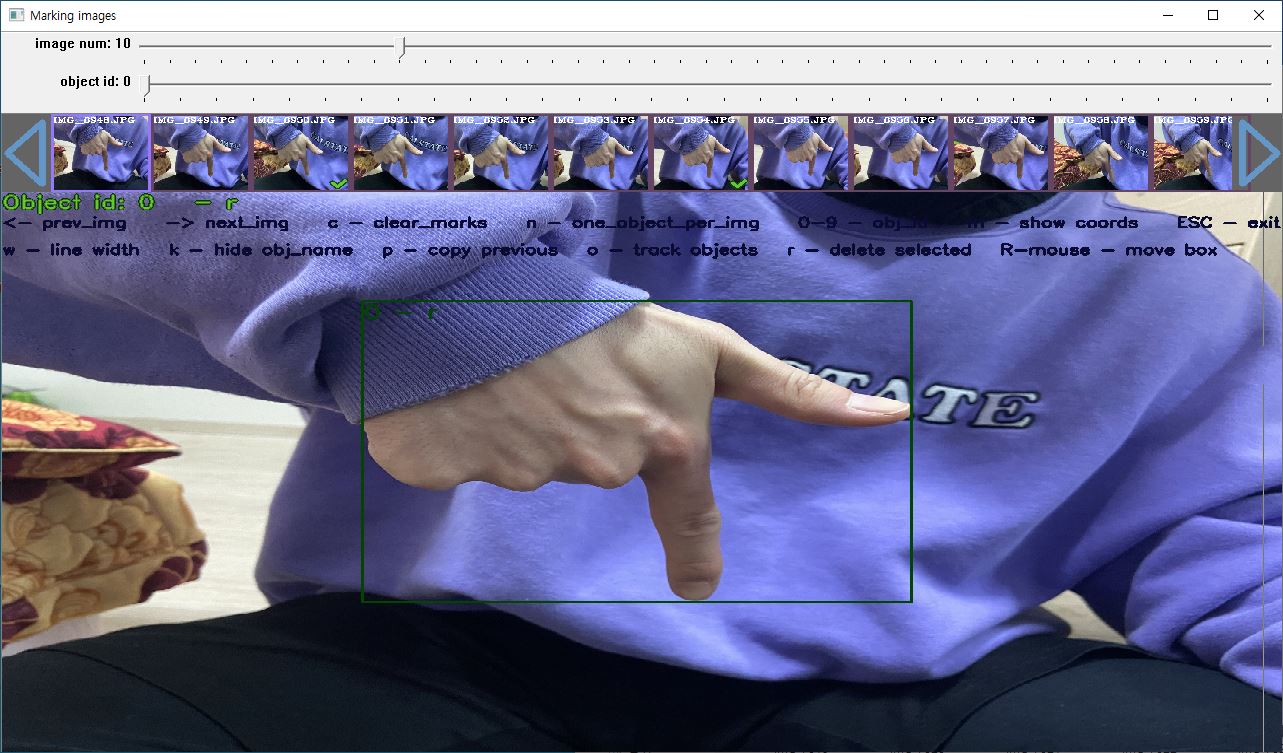
참고로 obj.names에 넣어놓은 이름들이 순서대로 숫자 0부터 배치됩니다.
0을 누르고 전처리 작업을 한다면 r(기역)에 대한 객체로 처리됩니다.
스페이스바를 누르면 저장 후 다음 사진으로 넘어갑니다!
직접 해보시게되면 바로 박스에 레이블이 달리니 쉽게 따라하실 수 있을 겁니다.
레이블 작업을 거치게 되면 아래와 같이 작업 결과에 대한 txt 파일이 생성되었음을 확인하실 수 있을 겁니다.
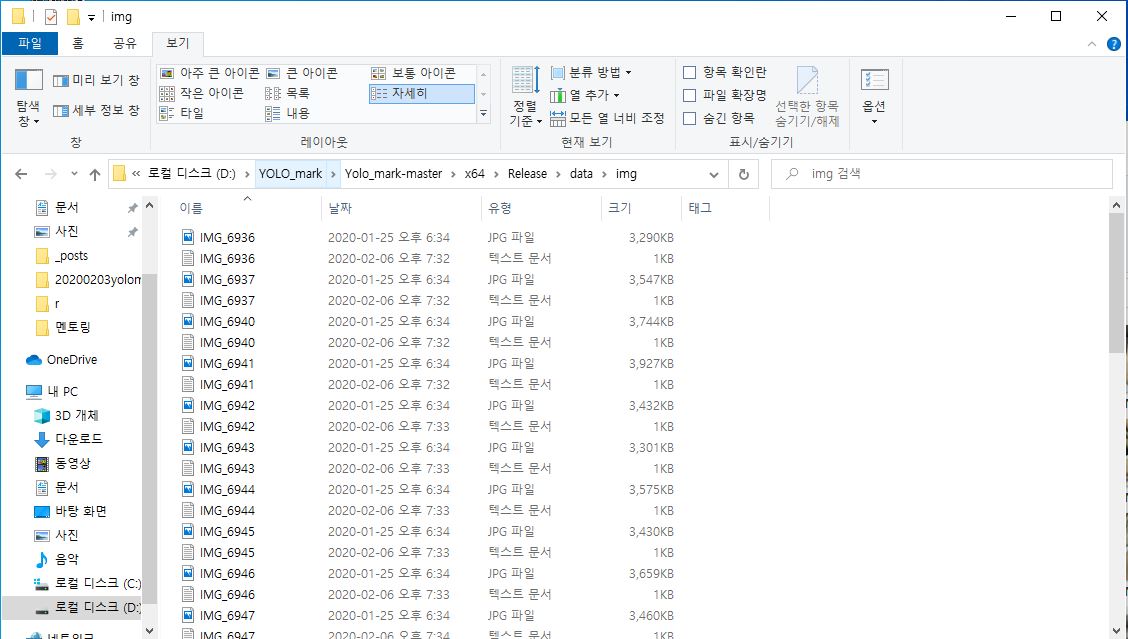 공백문자를 기준으로 구분지어보면 순서대로 객체식별번호, 중앙좌표의 x값, y값, w, h입니다.
공백문자를 기준으로 구분지어보면 순서대로 객체식별번호, 중앙좌표의 x값, y값, w, h입니다.
모든 학습데이터에 대해 레이블링 작업을 다하시면 yolo를 통해 학습해주시면 됩니다.
Training
yolo_mark-master\x64\Release에 있는 yolo-obj.cfg를 열어 가장 밑에 있는 [region] 안쪽에 classes를 분류하고자하는 객체의 종류로 변경하고, [convolutional] 안에 filters를 5*(classes + 5)의 결과 값으로 변경해줍니다.
다음으로는 http://pjreddie.com/media/files/darknet19_448.conv.23 경로에서 파일을 다운로드받아 darknet\x64 디렉토리 안에 저장해줍니다.
이 파일은 어노테이션 작업이 완료된 데이터들을 yolo 네트워크에 입력해주고 학습을 돕는 프로그램이라고 생각하시면 됩니다!
다음, 조금 전 수정했덨던 yolo-obj.cfg파일을 darknet\64 안에, yolo-mark 하위 디렉토리였던 img폴더와 obj.names, obj.data, train.txt 파일들을 darknet\x64\data 경로로 이동시켜주시면 됩니다.
여기까지 완료하셨다면 cmd를 실행시켜 현재 경로를 darknet\x64로 이동하고 아래 명령어를 입력해줍니다.
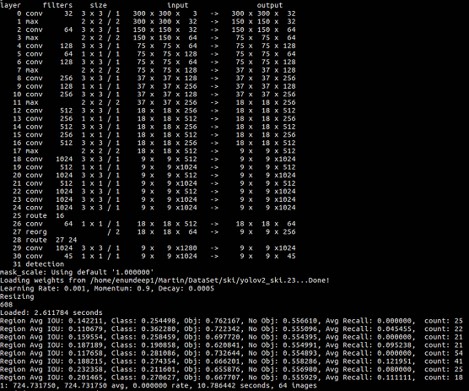
darknet detector train data/obj.data yolo-obj.cfg darknet19_448.conv.23
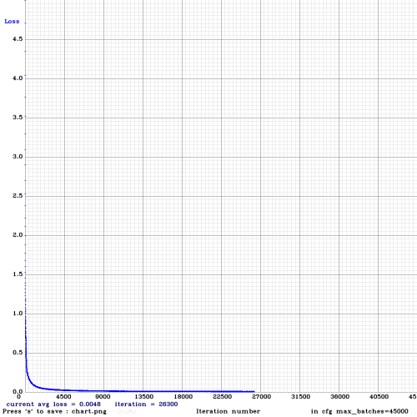
학습 및 최적화를 진행하고 시간이 한참 흐르고나면 아래와 같은 loss 함수 그래프를 만나보실 수 있을 겁니다.
etc
원래 YOLO의 tensorflow 버전인 darkflow에서 사용할 목적이었는데, YOLO-mark는 openCV, C++기반이며 darknet에는 편리하게 사용할 수 있으나, 여기서 레이블 작업한 것을 tensorflow로 옮겨서 바로 학습 입력데이터로 넣어주기에는 annotaion 형식이 서로 다르기 때문에 결과 text 파일을 xml 형식으로 바꿔줘야한다고합니다..ㅎㅎ
그래서 다음 포스트는 YOLO darkflow를 위한 labelImg 툴 사용법에 대해 올려보려고합니다.
https://ohjinjin.github.io/machinelearning/darkflow-5/
만약 몇백, 몇천장의 데이터에 대해 이미 박스처리를 완료하신 분이시라면 다행히도 방법이 있습니다! 같은 고충을 겪어보신 분께서 친절하게 포스팅해주셨더라구요 ㅎㅎ 여기를 눌러주세요.

개인이 공부하고 포스팅하는 블로그입니다. 작성한 글 중 오류나 틀린 부분이 있을 경우 과감한 지적 환영합니다!