
Analyze YOLO neural network for object detection
object detection을 제공하는 강력한 라이브러리인 YOLO를 간단하게 분석하여 그 내용을 기록하려고 합니다.
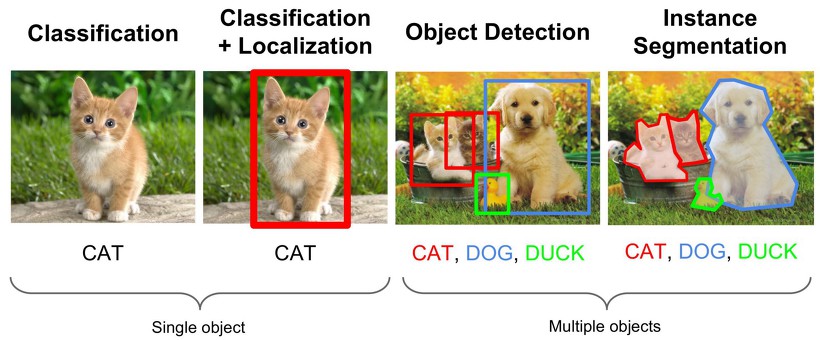
Object Detection
컴퓨터 비전 접목 딥러닝 객체 검출과 관련하여 여러 기술 및 용어가 있습니다.
그 중 classification과 object detection, segmentation 분야를 구분해봄으로써 Object detection에 대한 대략적인 이해를 먼저 해보려고 합니다.
-
Classification
첫 번째 분류(Classification)란 입력 이미지 별 Class label을 구분하는 기술입니다.
분류는 이후 세 가지 기술의 근간이 되는 기술이므로 우선적인 이해가 필요합니다. 그래서 대표적인 모델인 CNN에 대한 설명을 작성해 놓은 링크를 여기에 걸어드리겠습니다.
보통 우리가 다루게 될 이미지들은 그 이미지 내 다양한 객체들이 다양한 영역에 분포가 되어있고 이를 인식 및 추출하기 전에 어디 영역에 있는지를 확인해 줄 필요가 있습니다. -
Localization
그림상 두 번째 Localization은 이미지 안에 ROI 즉 우리가 찾고자 하는 Object가 전체 영상 내 어디에 존재하는 지 위치 정보를 출력해주는 기술입니다.
주로 bounding box가 이에 사용됩니다. -
Detection
세 번째 객체 탐지(Object Detection)란 classification과 Localization이 동시에 수행되는 기술입니다.
모델의 학습 목적에 따라 특정 객체만 탐지하는 경우도 있고 멀티 클래스의 객체를 탐지하는 경우도 있으며, 때로 위치정보만을 파싱해오는 데에만 사용되어 Localization의 의미로만 사용되는 경우도 있습니다.
Object detection 기술에서의 Localization 구현에 있어서도 역시 bounding box가 흔히 사용됩니다. -
Segmentation
네 번째 object segmentation은 object detection을 통해 검출된 객체의 형상을 따라서 해당 객체의 영역을 표시하는 기술을 말합니다.
보통 이미지의 각 pixel을 classification하여 경계를 따낸 결과를 도출한다고 합니다.
이 기술은 배경과 전경을 구분하는 용도로도 흔히 사용됩니다.
조금 더 자세히 설명하자면 이미지 전체에 대한 영역을 분할하는 기술은 Image segmentation이라고 불리는데 이렇게 분할된 영역들에 대해 각 의미요소를 찾는 적당한 알고리즘을 접목시켜 object segmentation을 수행합니다.
이 중 제가 분석하고자 하는 YOLO 네트워크는 바로 세 번째 객체 탐지를 구현한 라이브러리입니다.
Systems for object detection
object detection을 제공하는 시스템은 제가 사용한 YOLO(You Only Look Once) 말고도 R-CNN계열과 SSD(Single Shot Multibox Detector) 등이 있습니다.
이들의 장단점을 간단히 비교해 놓은 글 링크를 아래에 걸어두겠습니다.
https://jetsonaicar.tistory.com/12
https://sites.google.com/site/bimprinciple/in-the-news/dibleoning-euliyonghangaegchegeomchulr-cnnyolossd
YOLO(You Only Look Once)
YOLO는 C/C++호환 버전의 darknet으로도 구현되었고, python tensorflow 버전인 darkflow로도 구현되어 제공되고 있습니다.
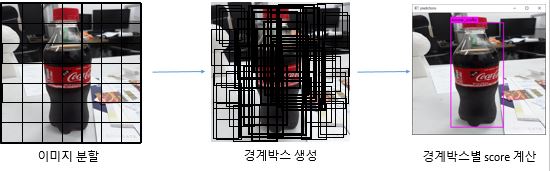
YOLO 네트워크의 Object Detection 시행에 대한 워크 플로우는 아래와 같습니다.
-
이미지 분할 단계
S x S grid로 전체 이미지를 분할합니다. -
경계박스에 대한 proposal 단계
분할된 grid cell 안에 특정 객체의 중심 커널이 포함될 경우 그 부분을 탐지해볼 필요가 있다는 컨셉으로 proposal이 이루어집니다.
각 grid cell은 B개의 bounding boxes를 예측하고 각 box에 대한 confidence score도 예측합니다. -
경계박스별 score 계산 및 threshold와의 대소비교를 통한 출력
Score 계산식은 아래와 같습니다.
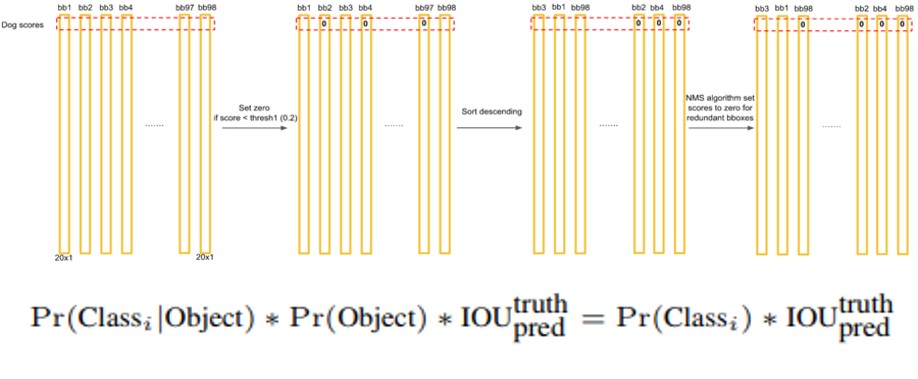
Score는 해당 box안에 object가 있을 확률이 얼마나 되는지 그리고 해당 object가 자신(모델)이 예측한 object가 맞을 확률이 얼마나 되는지에 대한 확률에 대한 점수입니다.
이를 수식으로 표현하면, Pr(Classi)*IOU(truth,pred)입니다.
참고로 grid cell에 object가 없으면 confidence score는 0이어야합니다.
우리는 confidenece score가 IOU(=실제값과 예측박스의 교집합/실제값과 예측박스의 합집합)과 같기를 원합니다.
각 grid cell은 Pr(Classi|Object)에 대한 조건부확률 C도 예측합니다. 이 확률은 오브젝트가 있다는 조건이 전제되는데, YOLO는 경계박스의 숫자 B와 관련 없이 그리드셀 당 한개의 클래스집합만을 예측합니다.
테스트시간에 이 조건부확률과 각각의 박스들의 score 값(이 때의 score는 각 박스들에 대한 클래스 구체적인 점수임)들을 곱하게됩니다.
이 때 계산된 score가 지정된 threshold 이상일 경우에만 경계박스가 출력됩니다.
그 식이 바로 Pr(Classi|Object)*Pr(Object)*IOU(truth,pred) 인데, 조건부확률 공식에 의해 약분되고 나면 Pr(Classi교집합Object)*IOU(truth,pred)로 해당 식이 대체될 수 있습니다.
또한 Object가 있을 사건이 Classi일 사건의 전체 집합이 되버리므로 Pr(Classi)*IOU(truth,pred)로 다시 식이 대체될 수 있습니다.
전체 예측값은 SxSx(B*5+C) 텐서로 인코딩됩니다.
S는 그리드 개수, B는 경계박스개수, C는 클래스 개수, 5는 각 경계박스가 예측하는 항목이 5개라서 나온 상수입니다.
- 경계박스가 예측하는 것들 : 중앙의 x, y좌표, w, h, score
YOLO_Network Design
CNN을 기반으로 구현되어있습니다.
YOLO 네트워크의 앞단의 convolutional layer는 image로부터 특징을 추출하며 뒷단의 fully connected layer는 출력확률과 좌표를 예측하는 역할을 합니다.
(v1의 경우)총 24개의 합성곱 계층과 2개의 전연결 계층으로 구성되어있습니다.
그리고 네트워크의 최종 output은 위에 작성했듯이 SxSx(B*5+C) 텐서로 출력이 됩니다.
PASCAL VOC 데이터셋으로 평가하기 위해 S=7, B=2로 설정하고 PASCAL VOC의 20개의 레이블로 최종 7x7x30 텐서를 갖게 됩니다.
YOLO_Training
최적화에는 sum-squared error 함수를 사용합니다.
최적화 시키기에 쉽기 때문에 이를 채용하긴 했지만 가중치들의 localization error와 classification error가 같다고 판단해버리는 문제때문에 YOLO의 목적인 average precision을 최대화하는데에 있어서 완벽하게 부합하지는 않습니다.
또한 한 이미지는 많은 grid cell을 가지고 있지만 대부분의 cell에는 object를 포함하지 않기 때문에 해당 cell의 confidence score가 zero로 평가될 것이고 이는 종종 object가 포함된 grid cell의 gradient가 지나치게 미미해져버릴 수 있기 때문입니다.
학습을 올바르게 하기 어렵기 때문에 bounding box의 좌표 예측으로부터 생성된 loss 값은 증가시키고, object가 포함되지 않을 것이라고 예측된 bounding box의 confidence로부터 생성된 loss는 감소 시키도록 구현해두었습니다.
YOLO의 loss function은 object가 해당 grid cell에 존재할 때에만 classification error에 대해서 처벌하도록 합니다.(Object가 없을 경우 Pr(Classi|Object)가 0이 될테니까)
마찬가지로 predictor가 ground truth box에 대해서 책임이 있는 경우에만 coordinate error에 대한 처벌을 합니다.
YOLO는 PASCAL VOC 2007과 2012 데이터셋을 사용해서 135번의 epoch로 네트워크를 학습시켰다합니다.
batch size는 64로, 0.9의 momentum을 주고 0.0005의 decay값을 설정했다합니다.
(수정중)