
Create dataset with spark-Understading BigData(10)
Intro
학교 수강과목에서 학습한 내용을 복습하는 용도의 포스트입니다.
빅데이터 개념과 오픈소스인 아파치 하둡과 맵리듀스 및 스파크를 이용한 빅데이터 적용을 공부합니다.
맵 리듀스의 경우 사용하기에 다소 진입장벽이 있는편입니다.
스파크처럼 통합 환경을 제공하지 않아 원하는 유틸리티나 라이브러리를 별도로 연결해서 사용해야하기 때문입니다. 이를 해소하는 것이 스파크라는 분산 데이터 처리 통합 엔진입니다.
따라서 맵 리듀스로 먼저 공부해보고, 스파크로 넘어갑니다.
스파크 엔진의 경우 Java가 아닌 Scalar라는 언어로 사용하며, 기존 우리가 알고 있는 SQL을 통해 고급 질의가 가능하며, 시각화나 스트림 처리 및 기계학습등 까지의 높은 수준의 분석을 제공하는 통합 프레임 워크입니다.
빅데이터 컴퓨팅(분산시스템상의 분산처리 환경)의 기본 개념과 원리를 이해하고 이를 실습해보는 과정에서 2대 이상의 리눅스 클러스터 서버를 구축 및 활용할 것입니다.
빅데이터이해(1) 보러가기
빅데이터이해(2) 보러가기
빅데이터이해(3) 보러가기
빅데이터이해(4) 보러가기
빅데이터이해(5) 보러가기
빅데이터이해(6) 보러가기
빅데이터이해(7) 보러가기
빅데이터이해(8) 보러가기
빅데이터이해(9) 보러가기
빅데이터이해(11) 보러가기
이번 시간에는 스파크 데이터세트 생성에 대해 배웁니다.
하둡클러스터에 저장된 외부데이터 소스로부터 스파크에서 읽어들여서 분석하기 전에 외부에 있는 데이터를 가져오는 데이터 생성에 관해 배웁니다.
데이터 세트와 데이터 프레임 생성하는 방법에 대해 먼저 배우고, 이후 오픈된 데이터소스인 SFPD를 가지고 데이터 세트를 생성하는 실습을 진행하겠습니다.
Intro of Data Set and Createing Data Frame
하둡 클러스터가 지원하는 모든 저장장치에서 스파크로 적재가 가능합니다.
로컬 파일 시스템 뿐아니라 HDFS와 Hive, HBase, Amazon S3, MapR-FS, JDBC 데이터베이스 등으로부터 데이터를 스파크에 적재할 수 있습니다.
스파크는 하둡이 지원하는 모든 데이터 형식을 지원합니다.
간단하게는 txt, csv 파일부터 JSON, 파케이(Parquet)라는 컬럼 기반 저장 파일, Sequence File라는 이진 키/값 저장파일, Protocol Buffer라는 Google에서 개발한 직렬화 형식, Object Storage라는 데이터를 객체로 관리 및 저장하는 형식까지 지원하고 있지요.
스파크 API 발전 단계를 살펴보면, 초기에 저수준 데이터 컬렉션인 RDD를 지원하고 있었습니다.
RDD는 분산된 JVM의 컬렉션입니다.
한 단계 진화하여 DataFrame이 지원되도록 버전업되었습니다. Data 형태가 행과 열 즉, table형식을 띈 객체들의 분산 데이터라고 할 수 있습니다.
또 한번 더 진화해서 DataSet이라는 형태로 제공되고 있는데요, 사용자 입장에선 큰 차이가 없을 수 있지만, 내부적으로 type의 안정성을 제공하고있지요.
그에 반해 기존 DataFrame은 실행 시에 에러를 체크하므로 실행중 에러위험이 있는 것이지요.
하지만 객체들로 데이터를 표현하기때문에 DataSet보다는 비교적 빠릅니다.
RDD(Resilient Distributed Datasets)
스파크의 저수준의 기본 컬렉션
- 비구조화된 데이터
- 타입이 정의되지 않은 데이터로 저수준 변환 및 액션 사용
- 응용에서 작성된 데이터세트는 최종 계산 시 내부에서 RDD를 사용
DataFrame
클러스터의 노드에 분산된 객체(테이블)들의 컬렉션
- 이름을 갖는 열(named column)들로 구성된 데이터프레임 상에서 연산 수행
- 관계형 데이터베이스의 테이블과 개념적으로 같으며 python의 데이터 프레임과 유사
- 데이터프레임이 생성된 후에는 변경 불가능(immutable)
- 데이터프레임은 디스크 또는 메모리 상에서 저장 및 캐싱
- 한 노드의 태스크가 실패하면 데이터프레임은 나머지 노드에서 자동으로 재구축되어 작업을 완료(fault tolerant, 고장감내)
- 각 열의 스키마(schema, 열과 열의 타입들의 리스트)를 지정하여 데이터세트로 변환
- 실행 시 스키마에 명시된 데이터 타입 일치 여부확인
DataSet
데이터프레임과 거의 유사
- 데이터프레임과 달리 컴파일 시 스키마에 명시된 데이터 타입 일치 여부 확인(type safe)
- 데이터프레임은 타입 Row를 갖는 데이터세트, Dataset[Row]
Row 타입은 스파크가 사용하는 ‘연산에 최적화된 내부적인 표현 방식’으로 데이터프레임 연산이 데이터세트 연산보다 성능면에서 우수
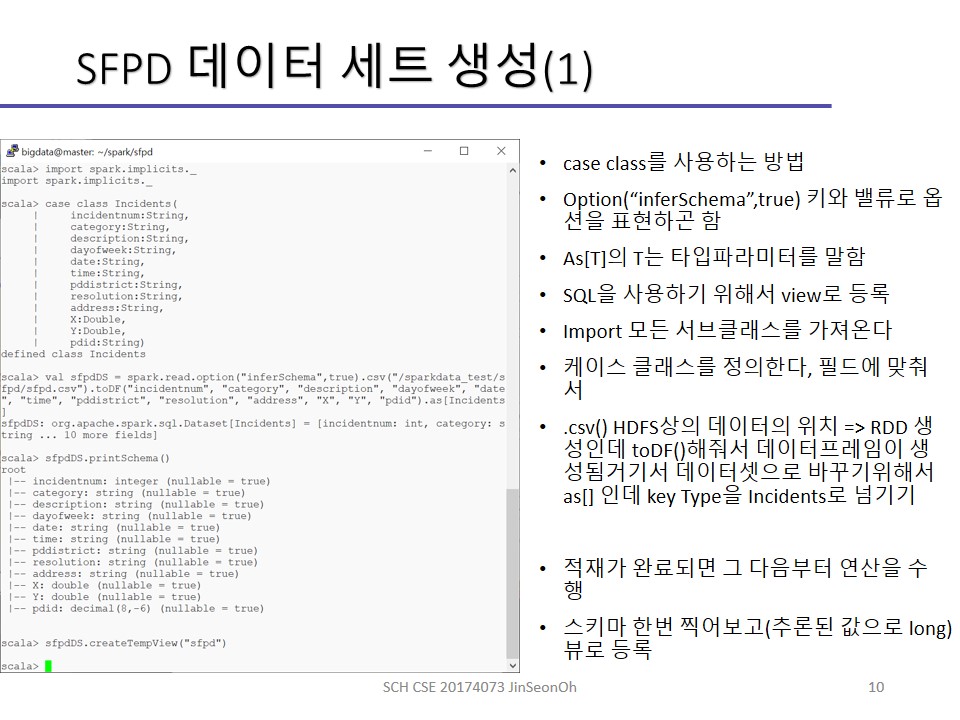
기본적으로 DataSet을 생성하려면 DataFrame을 먼저 생성하고 dataframe.as[T]를 통하여 사용자가 지정한 타입을 갖는 DataSet으로 변환해서 사용합니다.
스키마(schema)
열의 이름과 데이터의 타입을 기술하는게 스키마죠?
데이터가 저장되는 논리적인 구조를 말합니다.
스파크의 데이터세트는 테이블형식으로 저장됩니다.
csv나 파케이 등의 원시 데이터의 파일들은 정의된 스키마(테이블 구조)와 일치해야 해요.
스키마를 정의하는 방식은 크게 두가지가 있습니다.
첫 번째는 스칼라의 case class를 사용하여 열의 이름과 타입을 지정하여 테이블 스키마를 정의할 수 있습니다.
소스 데이터의 열의 이름과 케이스 클래스의 정의와 일치해야합니다.
데이터를 저장할 때 애초에 소스 데이터 파일에 열의 이름이 정의되어있을 수 있어요.
그와 동일해야한다는 말을 하는 것입니다.
단 스칼라의 케이스클래스는 22개의 필드로 제한됩니다.
데이터프레임을 데이터세트로 변환할 때에도 케이스 클래스를 사용합니다.
as[T] 적용 시에요.
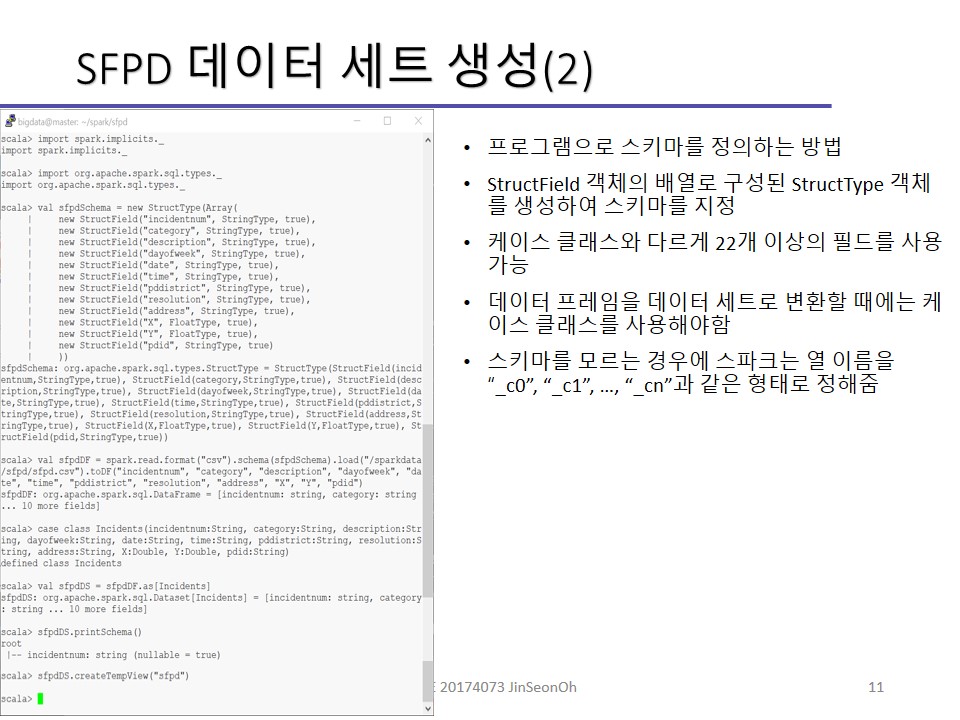
두 번째 방법은 프로그램으로 스키마를 정의하는 방법입니다.
StructField 객체의 배열로 구성된 StructType 객체를 생성하여 스키마를 지정합니다.
케이스 클래스와 다르게 22개 이상의 필드를 사용할 수 있습니다.
데이터 프레임을 데이터 세트로 변환할 때에는 케이스 클래스를 사용해야합니다.
스키마를 모르는 경우에 스파크는 열 이름을 “_c0”, “_c1”, …, “_cn”과 같은 형태로 정해줍니다.
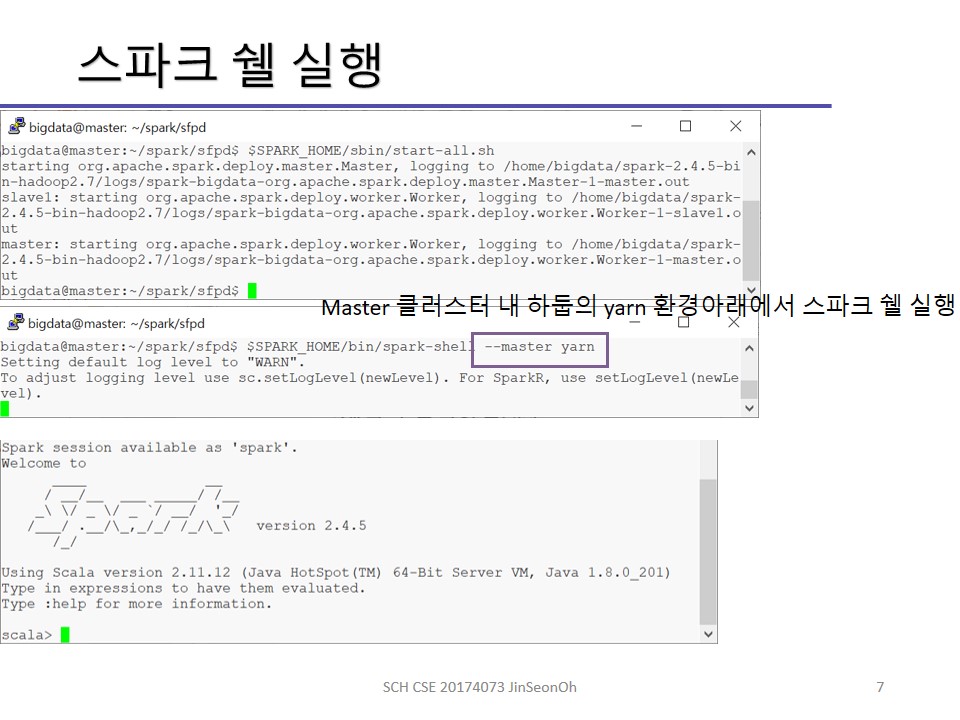
Spark Shell
스파크 쉘은 사용자와 상호작용하며 프로그램 작성이 가능합니다.(Read-Evaluate-Print Loop, REPL)
스칼라, 파이선 쉘을 제공하고 있습니다.
쉘이 시작하면 스파크 세션이 초기화되고 셀에 적재합니다.
스파크세션은 한 응용의 클러스터 연결 접근 방식을 관리합니다.
이처럼 스파크 쉘을 통해 데이터 세트를 생성하는 예제를 소개하겠습니다.
SFPD 데이터세트 생성
데이터에 대한 이해가 가장 먼저 입니다.
우리가 사용할 SFPD(San Francisco Police Department) 데이터의 출처는 여기에 링크를 걸어놓겠습니다.
이 데이터는 2013년 1월 ~ 2015년 7월까지 SFPD 범죄 사건 리포팅 시스템의 데이터로 지역 내 최대 범죄 발생지역, 최대 5가지 범죄의 유형등을 조사할 예정입니다.
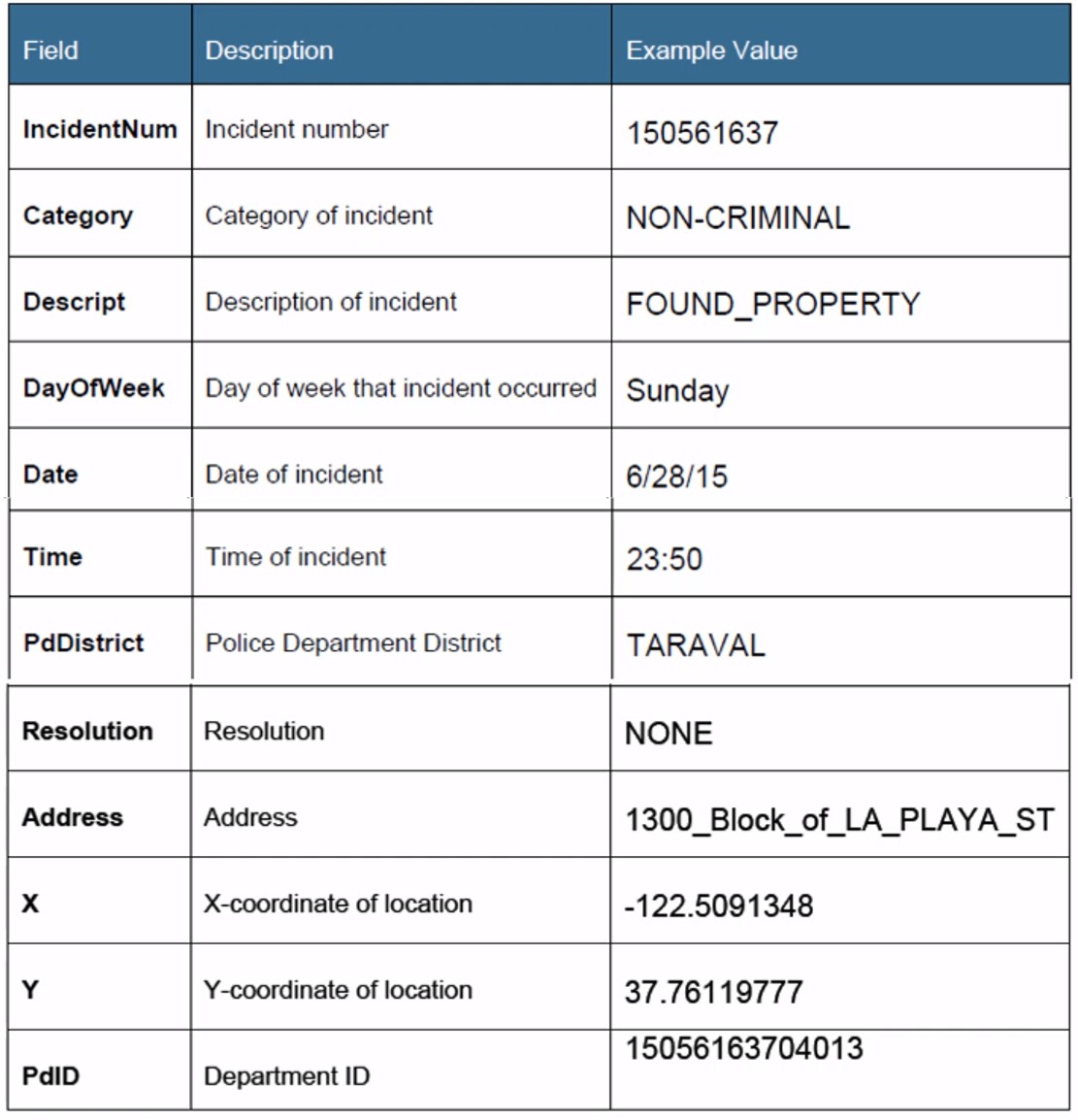
사건번호, 범죄유형, 범죄에 대한 설명, 요일, 날짜, 시간, 관할 경찰서, 해결 여부, 주소, 주소, x 좌표값, y 좌표값, 경찰서 ID 등의 필드로 구성되어있네요.
csv 파일로 로컬 파일 시스템에 저장하여 테이블 형식으로 각 행이 개별 사건을 나타내는 열들로 구성되도록 합니다.
우리가 하게 될 데이터 조사 질의 내용은 아래와 같습니다.
- 가장 사건이 많이 발생한 5개의 주소(address)는?
- 가장 사건이 많이 발생한 5개의 지구대(district)는?
- 가장 많은 10개의 사건 해결 유형(resolution)은?
- 가장 많은 10개의 범죄 유형(category)은?
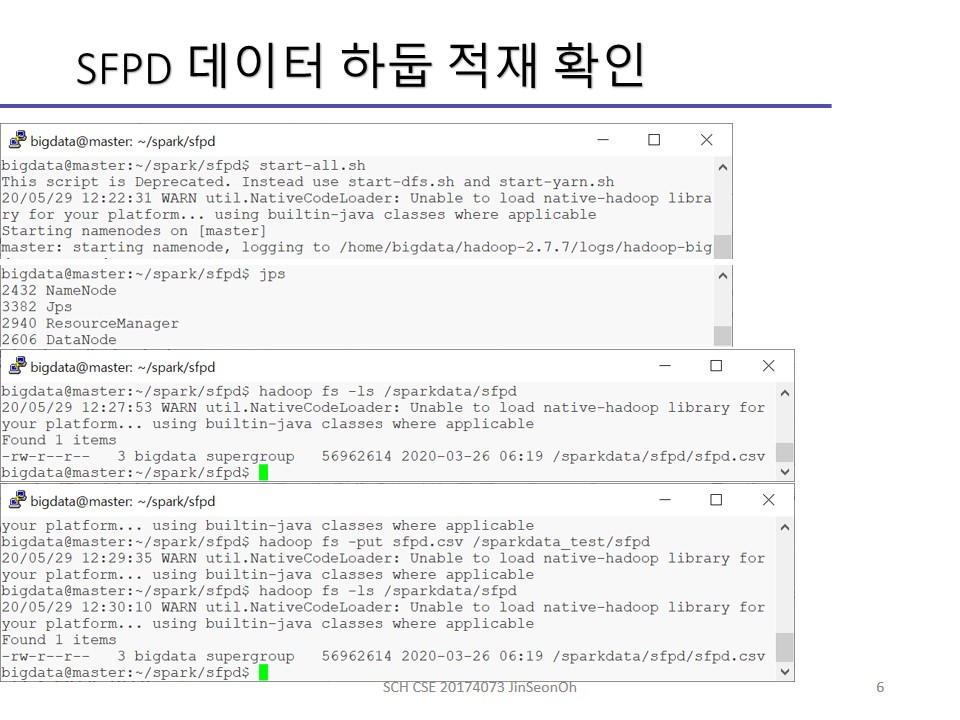
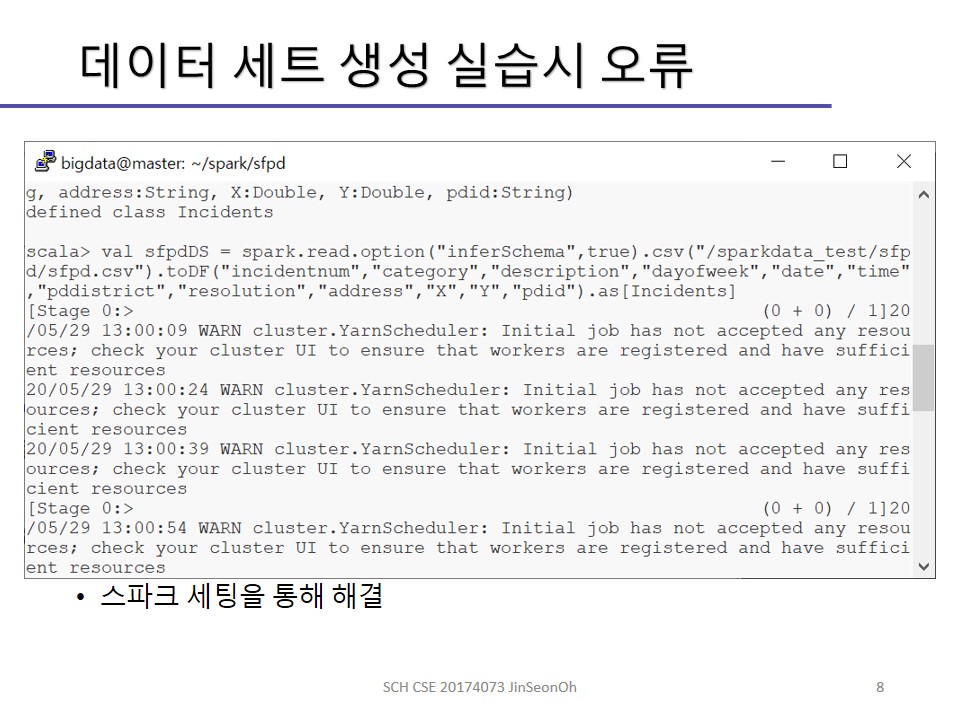
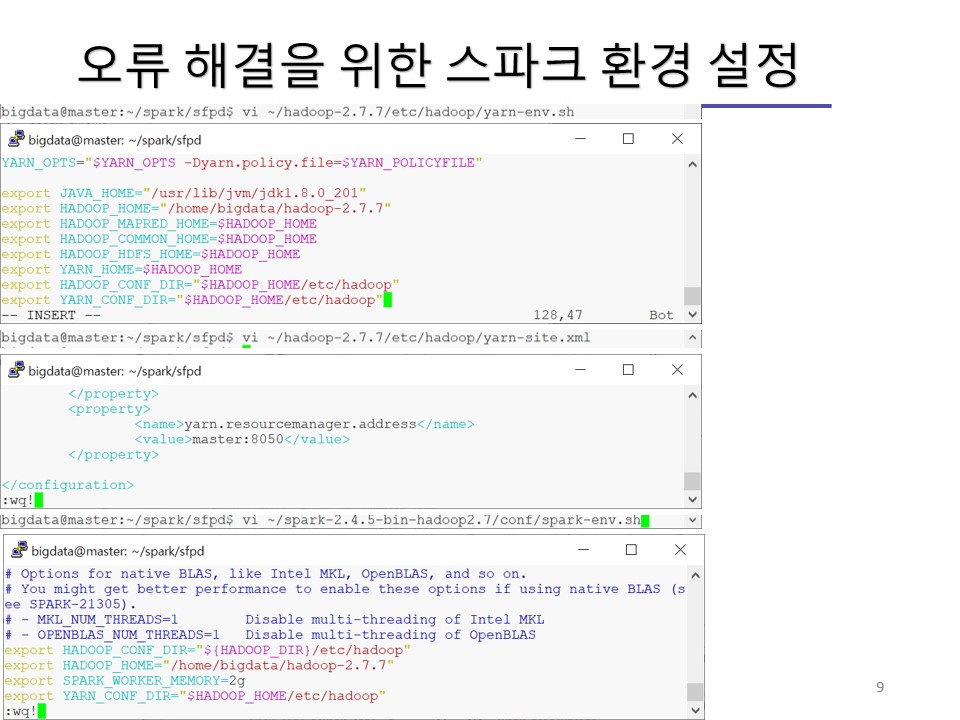
실습 내용을 이미지로 공유해드립니다.
데이터 유형별 적재 메소드
- 파케이 : spark.read.load(“파일”)
- JSON,파케이,CSV : spark.read.load(“파일”).format(“타입”)
- 텍스트파일 : spark.read.text(“파일”)
- 텍스트파일 적재 후 Dataset[String]을 리턴 : spark.read.textfile(“파일”)
- JDBC연결DB테이블적재 : spark.read.jdbc(URL,Table,Connection_Properties)
- spark.read.csv(“파일”)
spark.read.load(“파일”).format(“csv”)와 동일 - spark.read.json(“파일”
)
spark.read.load(“파일”).format(“json”) - spark.read.parquet(“파일”)
spark.read.load(“파일”).format(“parquet”)
개인이 공부하고 포스팅하는 블로그입니다. 작성한 글 중 오류나 틀린 부분이 있을 경우 과감한 지적 환영합니다!