
Intro of Zeppelin-Understading BigData(11)
Intro
학교 수강과목에서 학습한 내용을 복습하는 용도의 포스트입니다.
빅데이터 개념과 오픈소스인 아파치 하둡과 맵리듀스 및 스파크를 이용한 빅데이터 적용을 공부합니다.
맵 리듀스의 경우 사용하기에 다소 진입장벽이 있는편입니다.
스파크처럼 통합 환경을 제공하지 않아 원하는 유틸리티나 라이브러리를 별도로 연결해서 사용해야하기 때문입니다. 이를 해소하는 것이 스파크라는 분산 데이터 처리 통합 엔진입니다.
따라서 맵 리듀스로 먼저 공부해보고, 스파크로 넘어갑니다.
스파크 엔진의 경우 Java가 아닌 Scalar라는 언어로 사용하며, 기존 우리가 알고 있는 SQL을 통해 고급 질의가 가능하며, 시각화나 스트림 처리 및 기계학습등 까지의 높은 수준의 분석을 제공하는 통합 프레임 워크입니다.
빅데이터 컴퓨팅(분산시스템상의 분산처리 환경)의 기본 개념과 원리를 이해하고 이를 실습해보는 과정에서 2대 이상의 리눅스 클러스터 서버를 구축 및 활용할 것입니다.
빅데이터이해(1) 보러가기
빅데이터이해(2) 보러가기
빅데이터이해(3) 보러가기
빅데이터이해(4) 보러가기
빅데이터이해(5) 보러가기
빅데이터이해(6) 보러가기
빅데이터이해(7) 보러가기
빅데이터이해(8) 보러가기
빅데이터이해(9) 보러가기
빅데이터이해(10) 보러가기
빅데이터이해(12) 보러가기
이번 시간에는 제플린 설치에 대해 배웁니다.
Apache Zeppelin
실습 시 스파크를 웹상에서 사용하기 위해 제플린 노트북을 사용합니다.
웹상에서 코드를 작성하고 실행하고 결과를 확인할 수 있으며 코드 수정도 가능합니다.
데이터 수집, 발견, 분석, 시각화 및 협력작업도 지원하는 장점을 갖습니다.
python, scala 등을 플러그인하여 코드 작성이 가능하며 스파크 뿐만 아니라 Livy, Cassandra, Lens, SQL 등 다른 데이터 분석도구나 데이터베이스에 접근하여 질의 등의 확장 지원도 가능합니다.
Install Zeppelin
마스터 서버에 제플린을 다운로드 받습니다.
링크 : http://mirror.navercorp.com/apache/zeppelin/zeppelin-0.8.2/zeppelin-0.8.2-bin-all.tgz
다운로드를 위하여 아래 명령어를 입력해주세요.
wget http://mirror.apache-kr.org/zeppelin/zeppelin-0.8.2/zeppelin-0.8.2-bin-all.tgz
압축을 해제합니다.
tar -xvzf zeppelin-0.8.2-bin-all.tgz
기존 제플린에서 제공하던 설정파일들을 복사해서 조금 변경해 사용할 것입니다.
cd ~/zeppelin-0.8.2-bin-all/conf
cp zeppelin-site.xml.template zeppelin-site.xml
cp zeppelin-env.sh.template zeppelin-env.sh
cp zeppelin-env.cmd.template zeppelin-env.cmd
cp shiro.ini.template shiro.ini
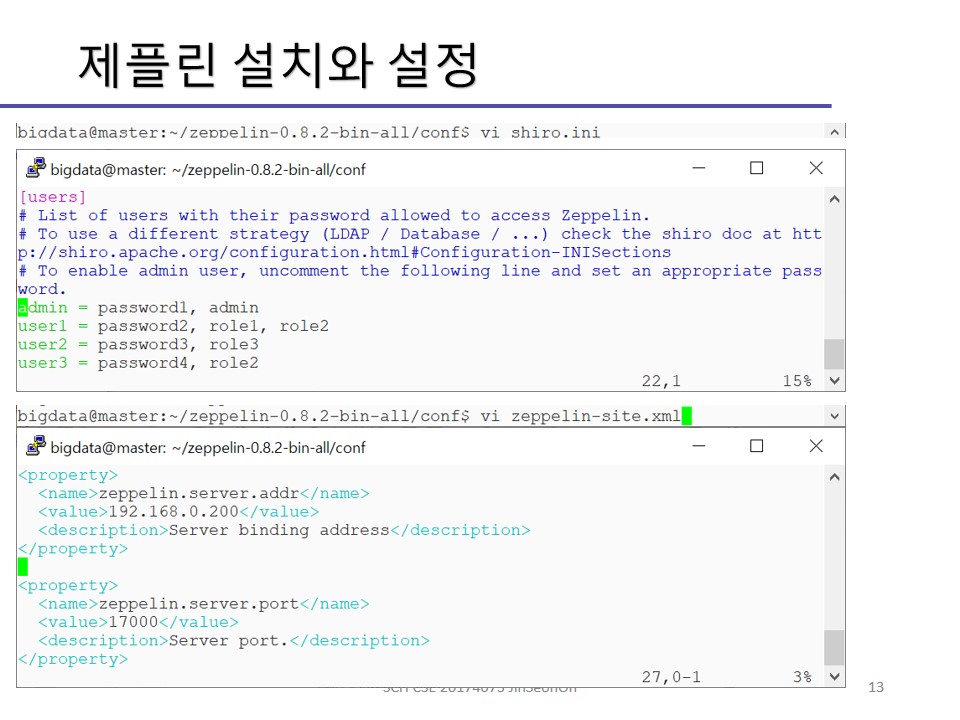
shiro.ini 파일을 변경함으로써 제플린 디폴트 계정 설정을 변경합니다.
[users]
admin=password1, admin
user1 = password2, role1, role2
user2 = password3, role3
user3 = password4, role2
zeppelin-site.xml 파일을 변경하여 제플린 서버 주소와 웹 포트도 설정합니다.
<property>
<name>zeppelin.server.addr</name>
<value>192.168.0.200</value>
<description>Server address</description>
</property>
<property>
<name>zeppelin.server.port</name>
<value>17000</value>
<description>Server port.</description>
</property>
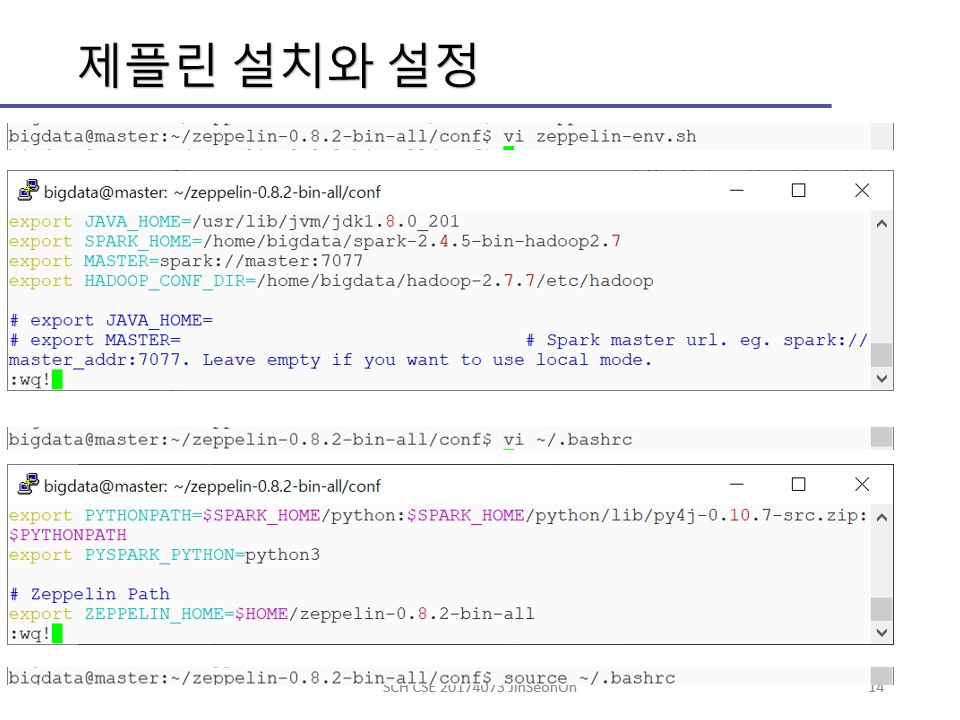
zeppeling-env.sh 파일에 아래 내용을 추가하여 제플린 환경 설정을 해주세요.
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_201
export MASTER=spark://master:7077
export SPARK_HOME=/home/bigdata/spark-2.4.5-bin-hadoop2.7
export HADOOP_CONF_DIR=/home/bigdata/hadoop-2.7.7/etc/hadoop
배포한 가상 머신 이미지에 설정까지 해주세요.
~/.bashrc 파일에 아래 내용을 추가해주시면 됩니다.
# Zeppelin Path
export ZEPPELIN_HOME=$HOME/zeppelin-0.8.2-bin-all
추가 이후에 아래 명령어를 통해 적용해주세요.
source ~/.bashrc
이렇게 하면 설정은 완료되었습니다.
제플린에서 스파크 실행시 에러 보정
제플린(0.8.2)에서 스파크(2.4.5) 실행 시 발생하는 에러 보정에 대해 기록합니다.
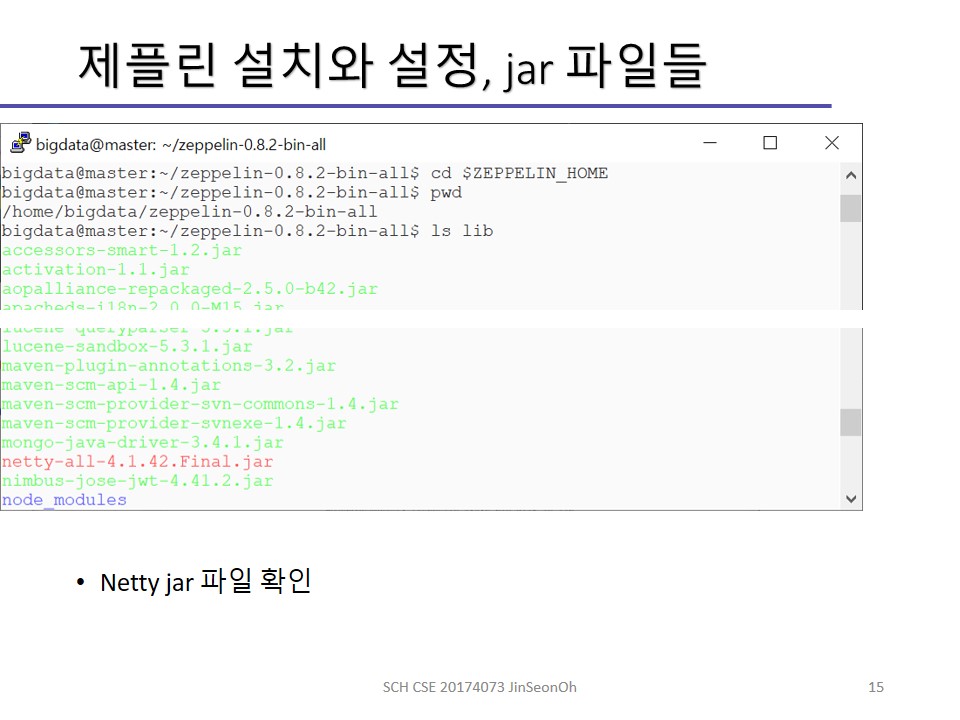
Netty 에러 보정
Netty는 자바 네트워크 응용 개발을 지원하는 비동기 이벤트 기반 네트워크 응용 프레임워크입니다.
class 파일,jar파일이 제플린버전과 스파크 버전이 있습니다, 우리 실습환경에 맞도록 스파크 버전의 Netty jar파일을 제플린에 복사해줍니다.
아래 명령어를 입력해주면 됩니다.
복사하면서 기존 제플린의 netty-all-4.0.23.Final.jars는 제거(하거나 백업)합니다.
cp $SPARK_HOME/jars/netty-all-4.1.42.Final.jar $ZEPPELIN_HOME/lib
mv $ZEPPELIN_HOME/lib/netty-all-4.0.23.Final.jar $ZEPPELIN_HOME/lib/netty-all-4.0.23.Final.jar-old
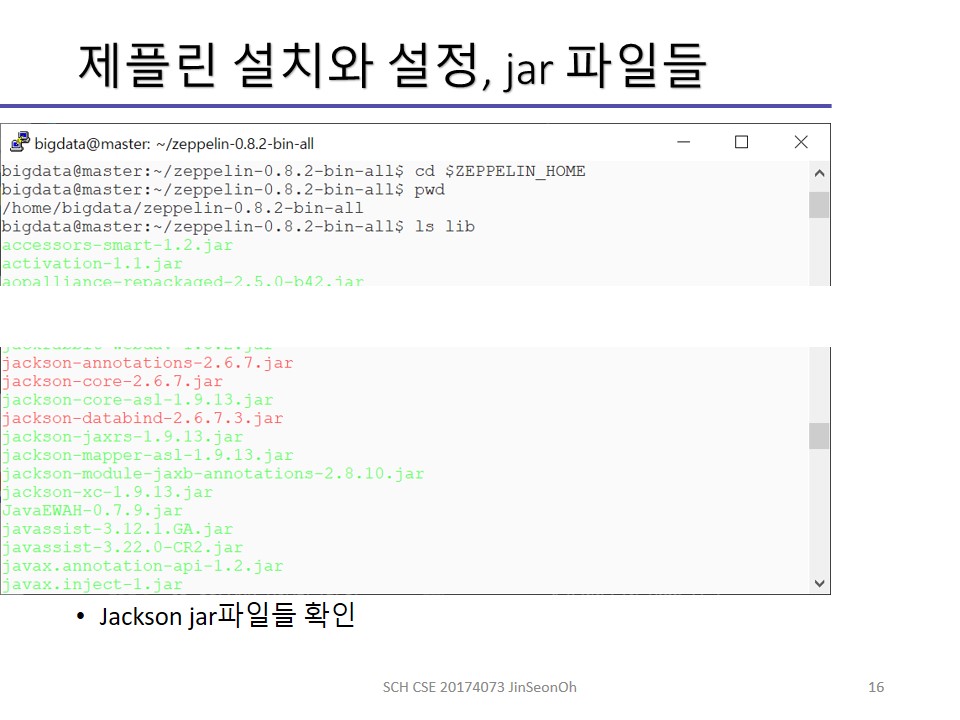
Jackson 에러 보정
Jackson은 JSON, XML 등 다양한 형식을 지원하는 자바 라이브러리입니다.
잭슨 역시 마찬가지로 스파크 버전의 Jackson jar 파일들을 제플린에 복사해줍니다.
cp $SPARK_HOME/jars/jackson-annotations-2.6.7.jar $ZEPPELIN_HOME/lib
cp $SPARK_HOME/jars/jackson-core-2.6.7.jar $ZEPPELIN_HOME/lib
cp $SPARK_HOME/jars/jackson-databind-2.6.7.1.jar $ZEPPELIN_HOME/lib
mv $ZEPPELIN_HOME/lib/jackson-annotations-2.8.0.jar $ZEPPELIN_HOME/lib/jackson-annotations-2.8.0.jar-old
mv $ZEPPELIN_HOME/lib/jackson-core-2.8.10.jar $ZEPPELIN_HOME/lib/jackson-core-2.8.10.jar-old
mv $ZEPPELIN_HOME/lib/jackson-databind-2.8.11.1.jar $ZEPPELIN_HOME/lib/jackson-databind-2.8.11.1.jar-old
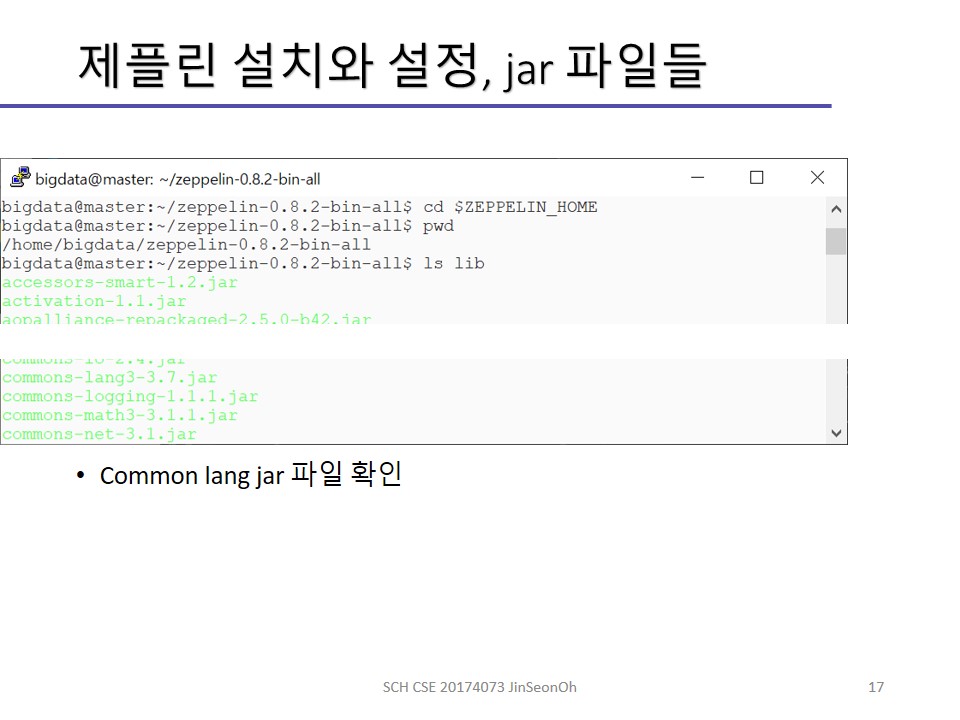
commons-lang 에러 보정
스파크 버전 commons-lang3-3.5.jar를 제플린에 복사합니다.
제플린의 기존 commons-lang3-3.4.jar는 제거(또는 백업)합니다.
cp $SPARK_HOME/jars/commons-lang3-3.5.jar $ZEPPELIN_HOME/lib
mv $ZEPPELIN_HOME/lib/commons-lang3-3.4.jar $ZEPPELIN_HOME/lib/commons-lang3-3.4.jar-old
이렇게 실습환경 특성상 발생 가능한 에러에 대해 보정한 이후에는 제플린노트북을 실행시켜봅시다.
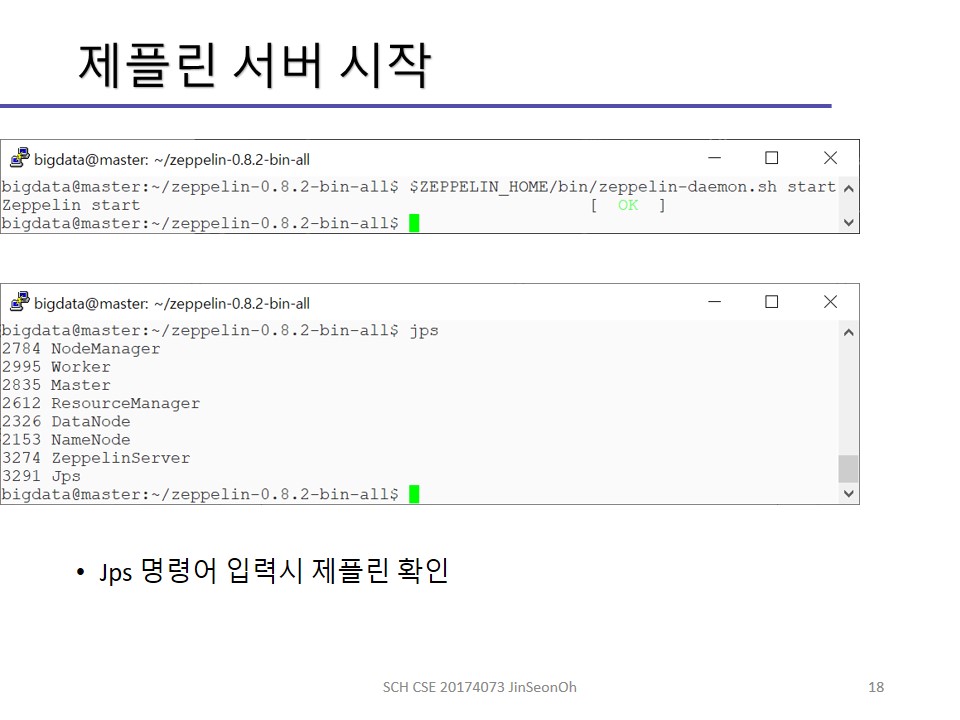
제플린 서버 실행
제플린 최상위 폴더 안에 있는 bin이라는 디렉토리에 zeppelin-daemon.sh가 있습니다.
스크립트를 실행하여 제플린 서버를 시작해봅시다.
하둡과 스파크는 먼저 실행되어있다는 가정 하에 아래 명령어를 입력해주세요.
$ZEPPELIN_HOME/bin/zeppelin-daemon.sh start
참고로 종료시에는 stop, 재시작 시에는 restart를 입력하시면됩니다.
시작되었는지 보려면 jps 명령어를 입력함으로써 제플린 백그라운드 데몬이 실행되었음을 확인하실 수 있을 겁니다.
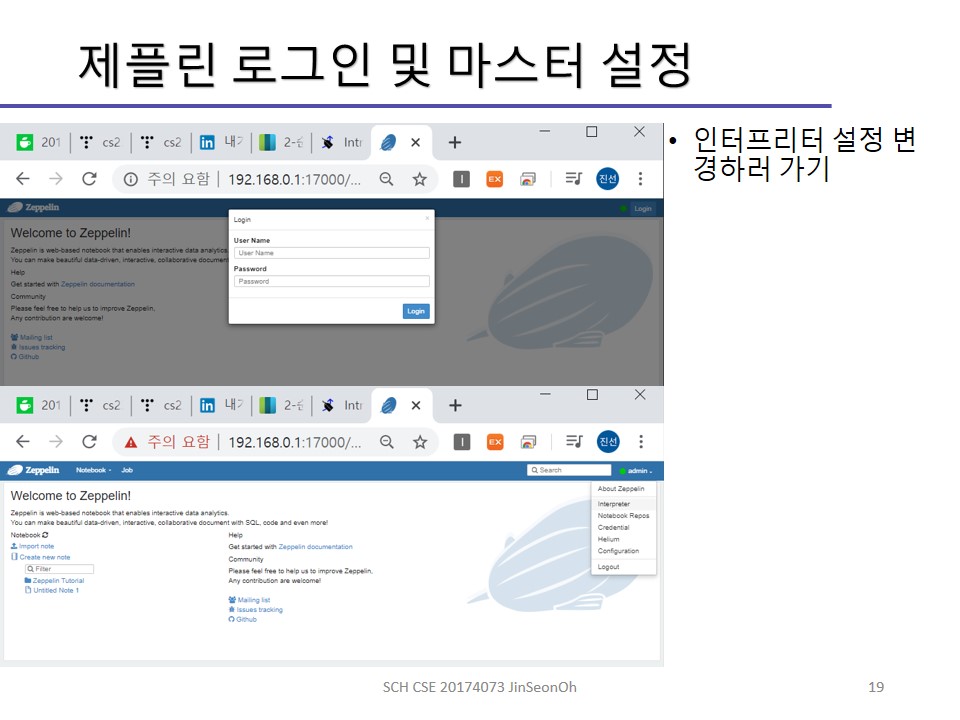
이렇게 실행된 제플린 서버는 웹상으로도 확인 가능합니다.
zeppelin-site.xml에서 설정한대로 포트 17000번으로 접속하시면됩니다.
아래와 같이 화면이 확인되실 건데요, shiro.ini에서 설정했던 ID와 PW로 로그인 가능합니다.
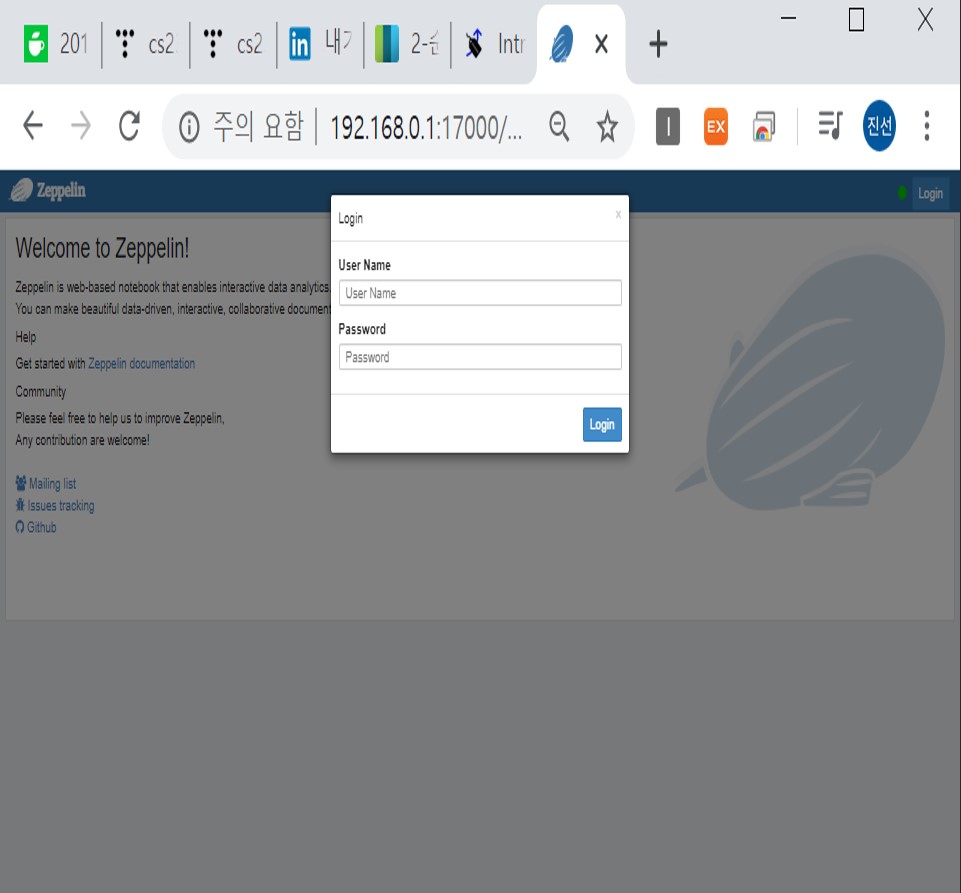
관리자 계정은 admin / password1 였고, 사용자 계정은 user1 / password2로 설정했었지요.
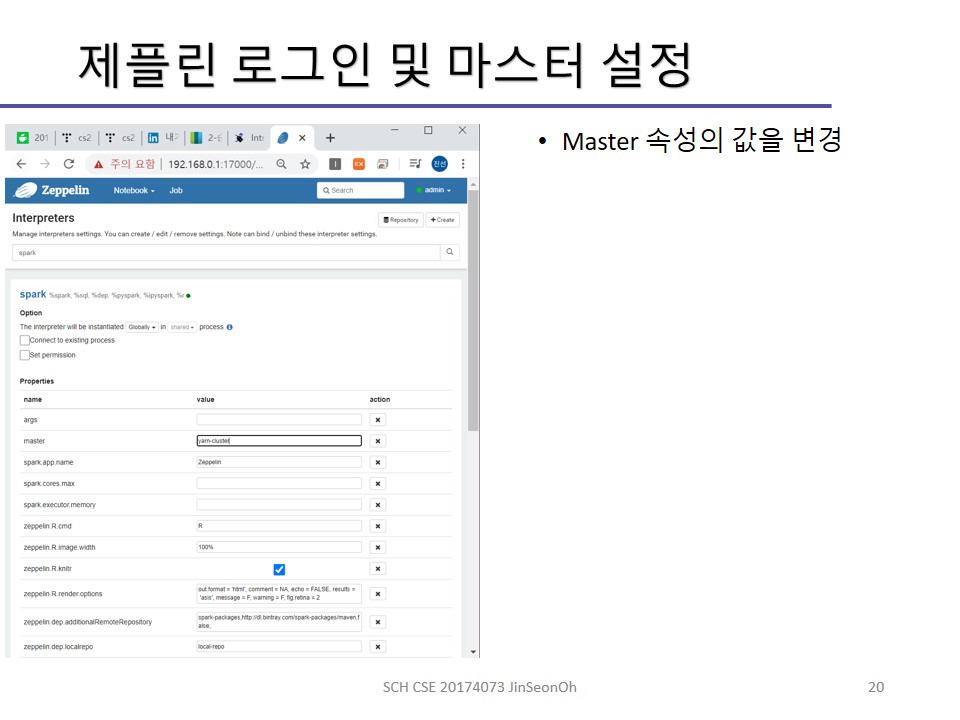
관리자계정으로 접속하게되면 스파크 인터프리터 설정을 확인하실 수 있습니다.
아래 순서로 spark에 대한 여러 속성을 확인할 수 있습니다.
admin > Interpreter > “spark”로 검색
edit 버튼을 눌러 master라는 property를 yarn-cluster로 수정하여 저장해주세요.
하둡의 YARN 관리하에 사용되도록 하기 위함입니다.
여기까지 설정을 모두 끝냈습니다.
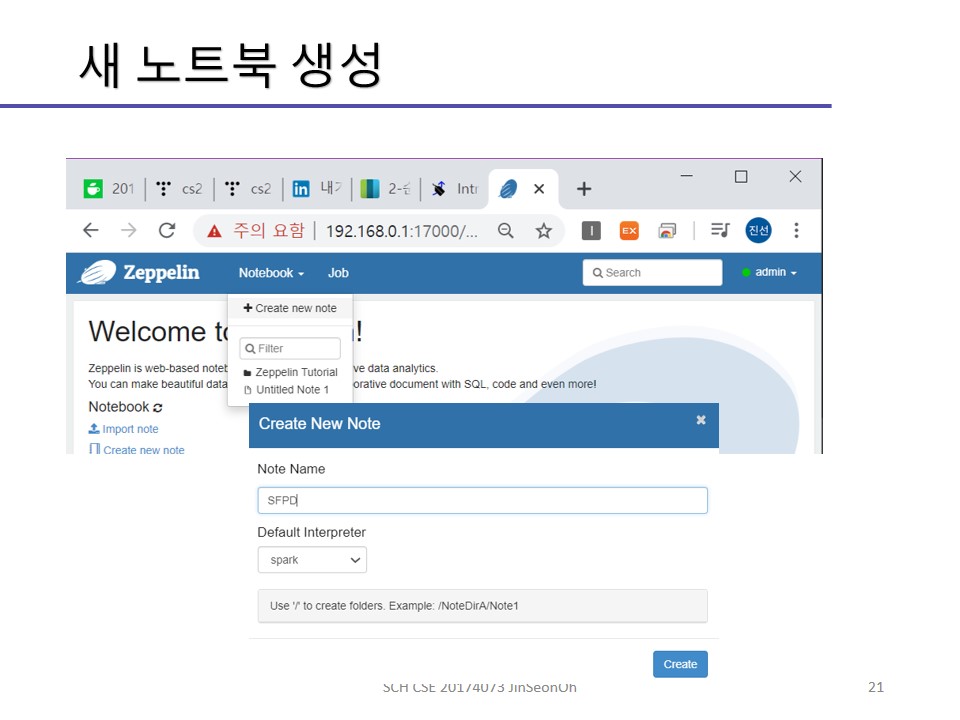
새 노트북 생성
조금 전 켰던 웹 페이지 상의 네비게이션바 중에 Notebook > Create new note 를 클릭해주시고 Note name과 기본 인터프리터를 선택하신 후 Create Note 버튼을 눌러주세요.
설정하신 인터프리터(저는 spark)가 해석할 수 있는 프로그래밍 언어(scala 등)로 코드를 작성해주시면 됩니다.
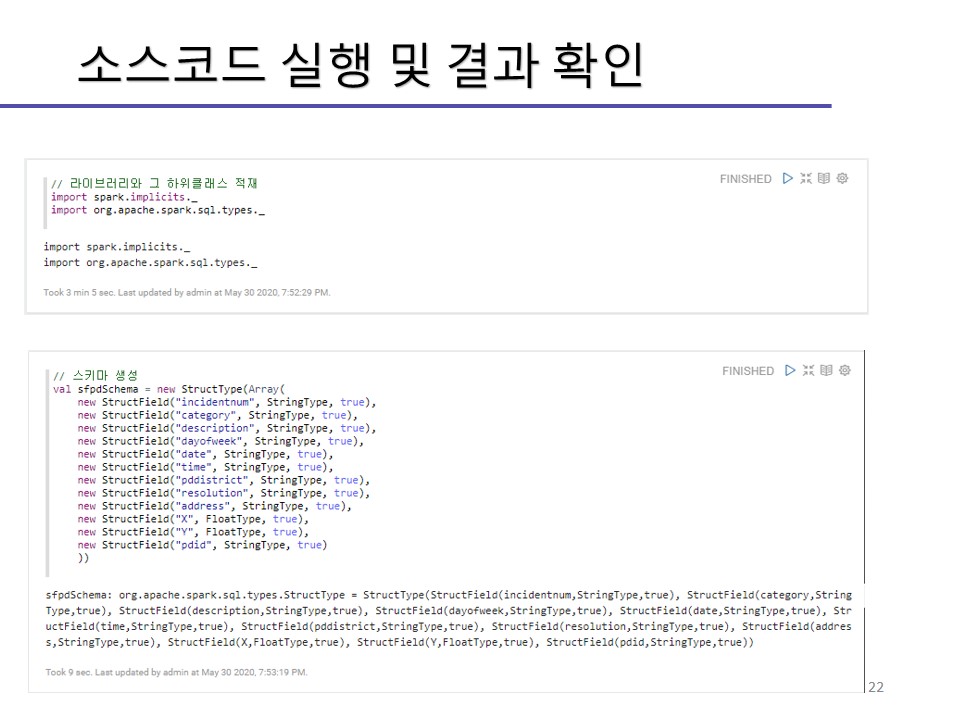
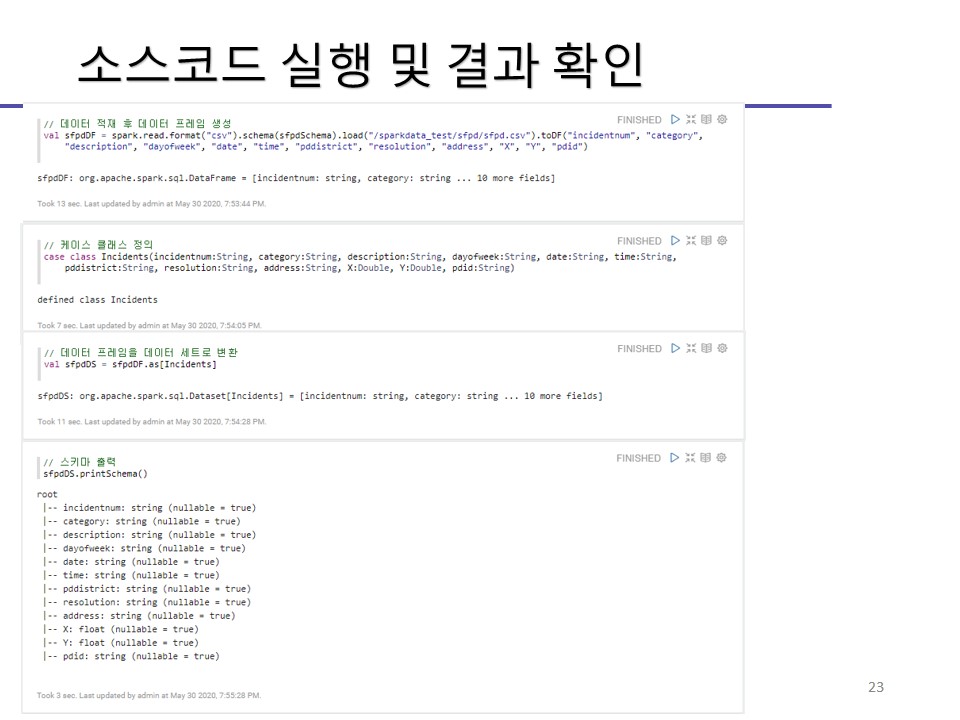
제플린 설치, 설정붙 예제 코드 실행까지의 과정을 이미지로 첨부해놓겠습니다.

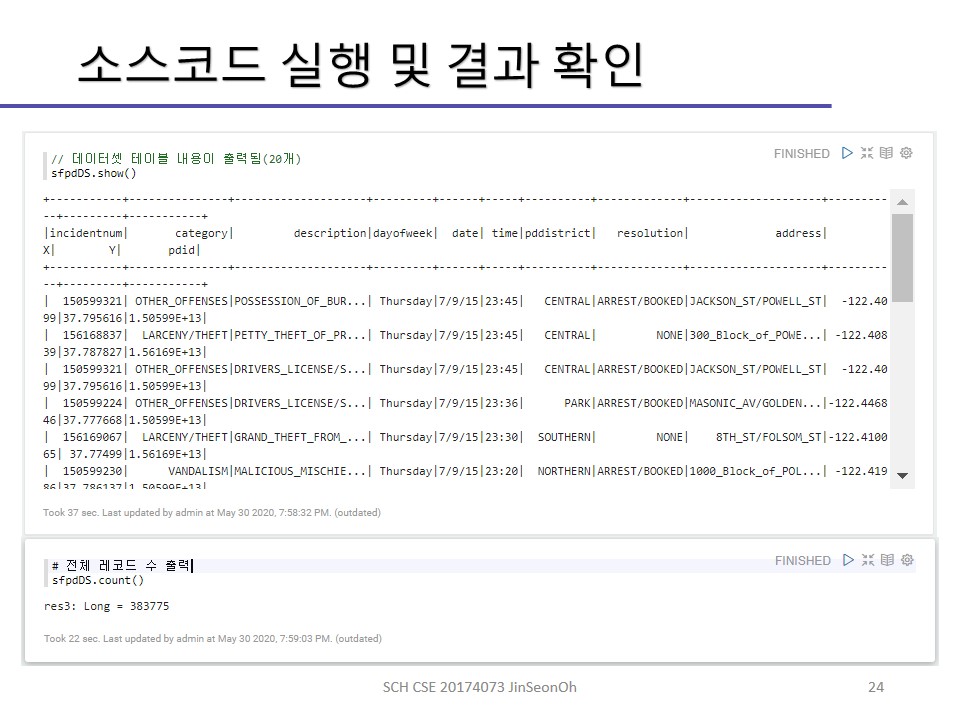
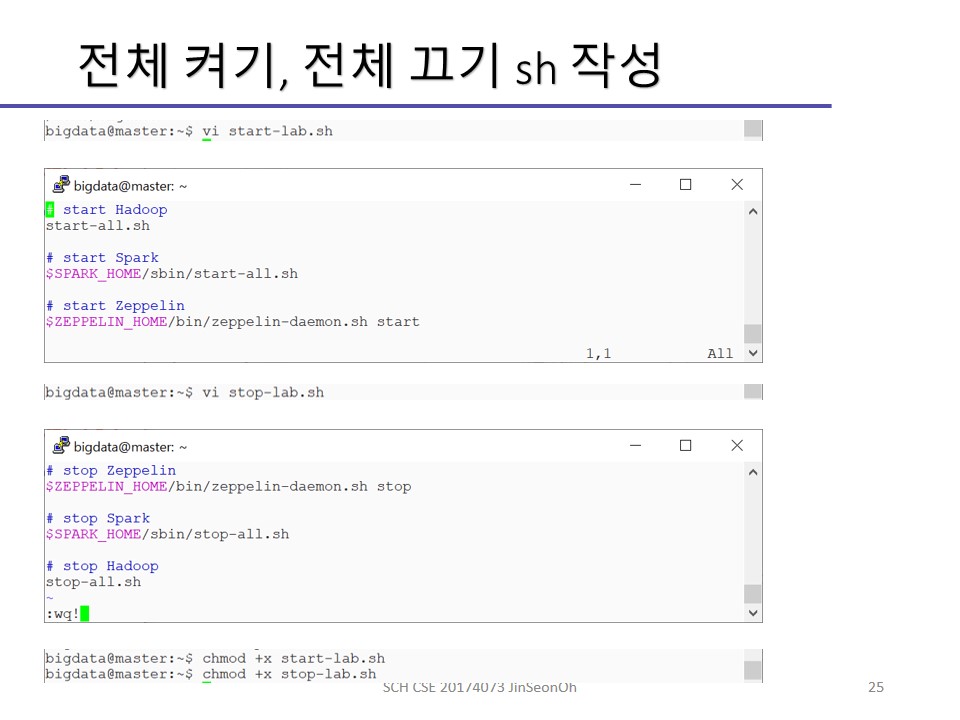
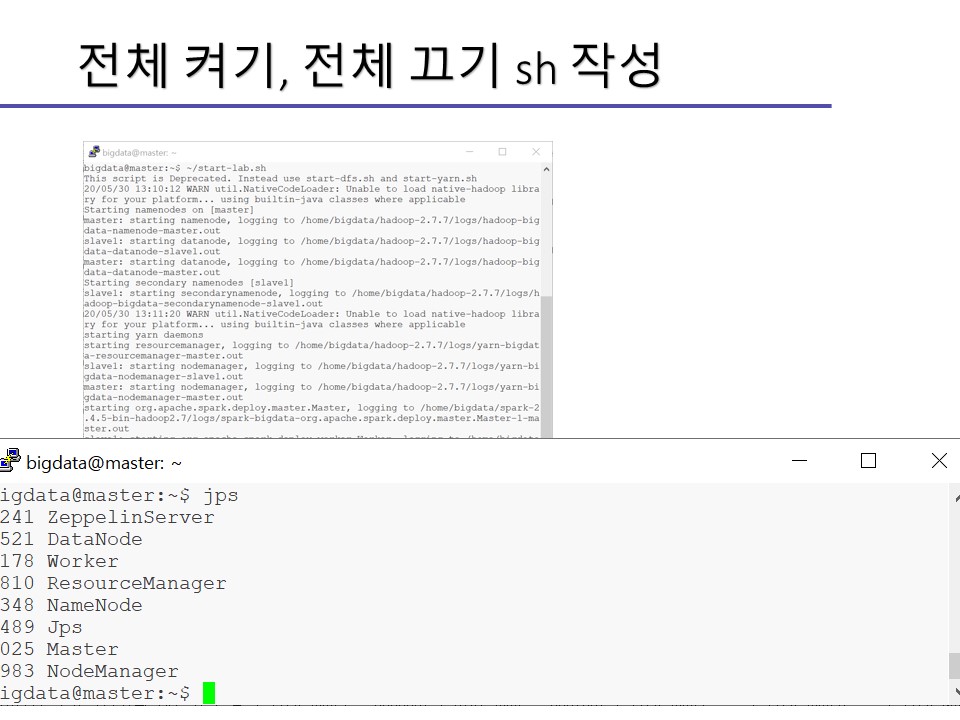
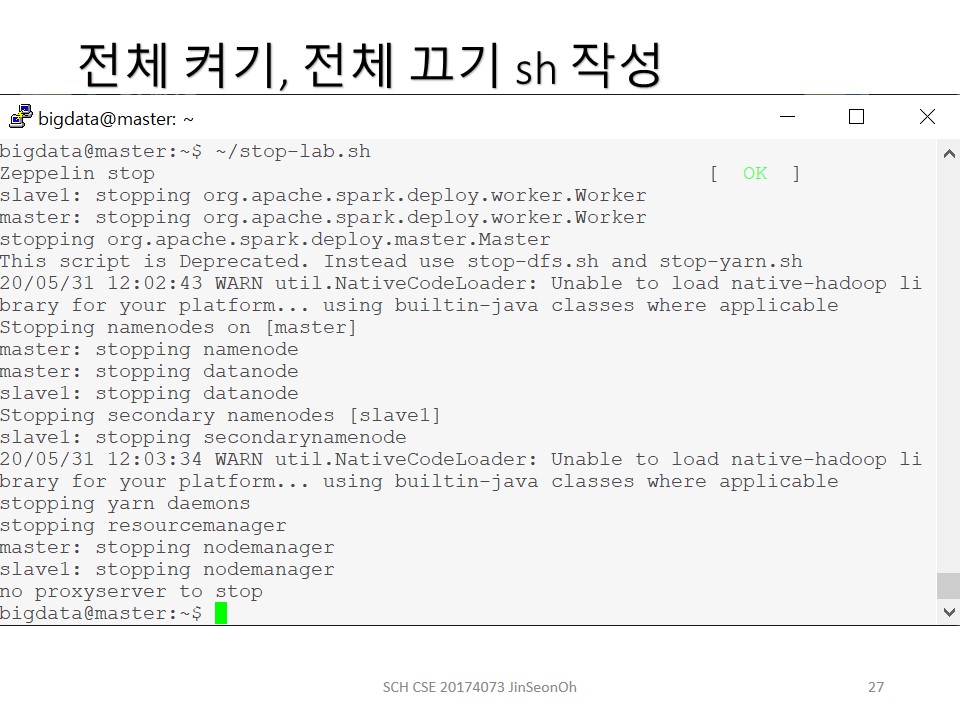
개인이 공부하고 포스팅하는 블로그입니다. 작성한 글 중 오류나 틀린 부분이 있을 경우 과감한 지적 환영합니다!