
Operation of Dataset(1)-Understading BigData(12)
Intro
학교 수강과목에서 학습한 내용을 복습하는 용도의 포스트입니다.
빅데이터 개념과 오픈소스인 아파치 하둡과 맵리듀스 및 스파크를 이용한 빅데이터 적용을 공부합니다.
맵 리듀스의 경우 사용하기에 다소 진입장벽이 있는편입니다.
스파크처럼 통합 환경을 제공하지 않아 원하는 유틸리티나 라이브러리를 별도로 연결해서 사용해야하기 때문입니다. 이를 해소하는 것이 스파크라는 분산 데이터 처리 통합 엔진입니다.
따라서 맵 리듀스로 먼저 공부해보고, 스파크로 넘어갑니다.
스파크 엔진의 경우 Java가 아닌 Scalar라는 언어로 사용하며, 기존 우리가 알고 있는 SQL을 통해 고급 질의가 가능하며, 시각화나 스트림 처리 및 기계학습등 까지의 높은 수준의 분석을 제공하는 통합 프레임 워크입니다.
빅데이터 컴퓨팅(분산시스템상의 분산처리 환경)의 기본 개념과 원리를 이해하고 이를 실습해보는 과정에서 2대 이상의 리눅스 클러스터 서버를 구축 및 활용할 것입니다.
빅데이터이해(1) 보러가기
빅데이터이해(2) 보러가기
빅데이터이해(3) 보러가기
빅데이터이해(4) 보러가기
빅데이터이해(5) 보러가기
빅데이터이해(6) 보러가기
빅데이터이해(7) 보러가기
빅데이터이해(8) 보러가기
빅데이터이해(9) 보러가기
빅데이터이해(10) 보러가기
빅데이터이해(11) 보러가기
이번 시간에는 스파크 데이터세트의 연산에 대해 배웁니다.
Operation of Dataset
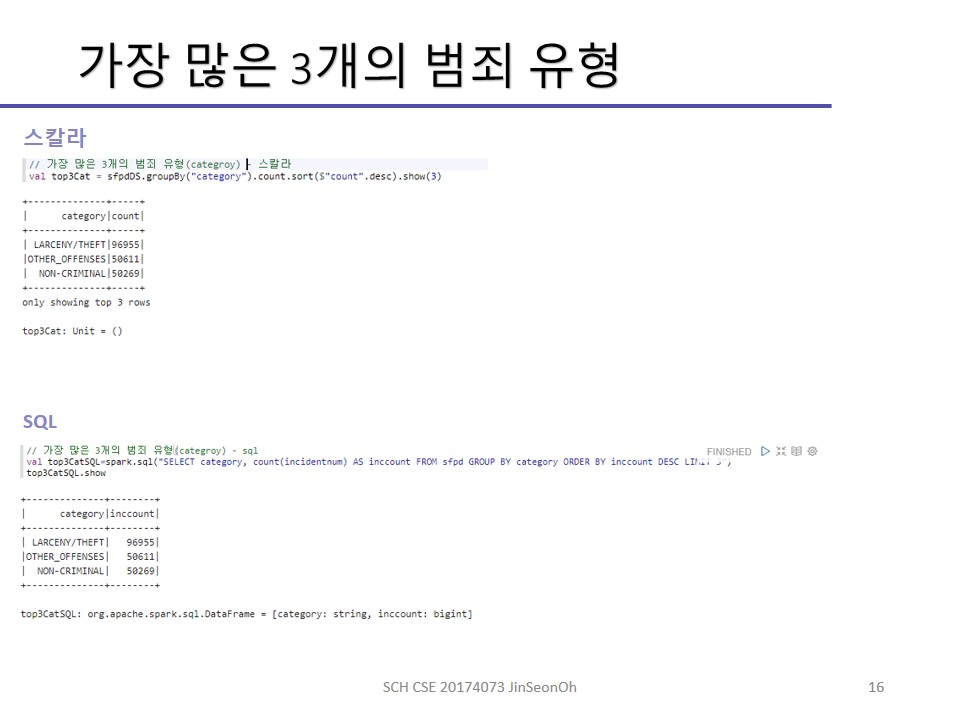
지난 시간 다뤘던 SFPD 데이터를 가지고 기본적인 데이터세트 연산을 실습해볼 것입니다.
그 전에 앞서서 연산들이 무엇이 있는지 에 대해 먼저 소개하도록 하겠습니다.
데이터세트 상에는 변환(transformation)과 액션(action) 두 가지 연산이 존재합니다.
변환의 결과로 데이터세트를 리턴하는데, 데이터세트는 수정이 불가능하다는 특징을 가지므로 새로운 데이터세트를 리턴합니다.
우리가 만든 결과를 보기 위한 액션연산을 하면 수행된 결과값을 리턴해주는 것입니다.
데이터세트는 지연 연산(delayed operation)을 제공하므로 변환은 즉시 수행되지 않고 액션이 호출될 때 수행되어 새로운 데이터세트를 생성합니다.
주요 변환 연산
-
map() : 각 요소에 대해 함수가 적용된 새로운 데이터세트를 반환
-
filter() : 주어진 조건에 맞는 요소들의 새로운 데이터세트를 반환
-
groupBy() : 주어진 key 함수에 의해 관계형(relational)식의 그룹화된 데이터(key, value)를 반환
-
reduce() : 인수로 지정된 함수를 수행하여 최종 결과값을 산출하여 반환
-
flatMap() : map()과 매우 비슷하지만, 시퀀스를 반환
-
distinct() : 중복되지 않은 고유의 요소만을 데이터세트로 반환
-
cache() : 데이터세트를 메모리에 캐싱
-
persist() : 데이터프레임(실행시 오류체크하는 것이 데이터세트와 다름)을 지속적으로 하둡파일시스템에 저장
-
createTempView(viewName) : 테이블 뷰로서 참조하기 위해 주어진 데이터세트를 뷰에 등록
-
describe() : 수치화된 column을 위한 count나 mean, sttdev, min, max 등을 계산
-
count() : 요소의 수를 반환
-
reduce(func) : 데이터세트의 집계된 값을 반환
-
collect() : 데이터세트의 모든 레코드들을 array형식으로 driver에 전달하므로 네트워크 부하가 심함
-
take(n) : 처음 n개의 요소들을 반환
-
show() : 테이블 형식의 데이터프레임의 처음 20개의 행을 출력
-
first() : 데이터세트의 첫행을 반환
-
head() : 데이터세트의첫행을 반환
-
takeAsList(n) : 처음 n개의 레코드들을 list형식으로 반환
이외의 연산들을 보시려면 스파크의 docs 링크를 참조하세요.
데이터셋에 대한 닥스는 아래 링크로 찾아들어가시면 됩니다.
https://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.sql.Dataset/
열의 이름을 명시하는 방법은 Dataset 메소드들 중에서 column()이나, apply()메소드입니다. apply()메소드는 이름을 직접적으로 호출하지 않아도 되는 메소드였죠.
sfpdDS.apply(“pddistrict”) 이렇게 할 수도 있지만, sfpdDS(“pddistrict”) 이렇게 호출할 수도 있습니다.
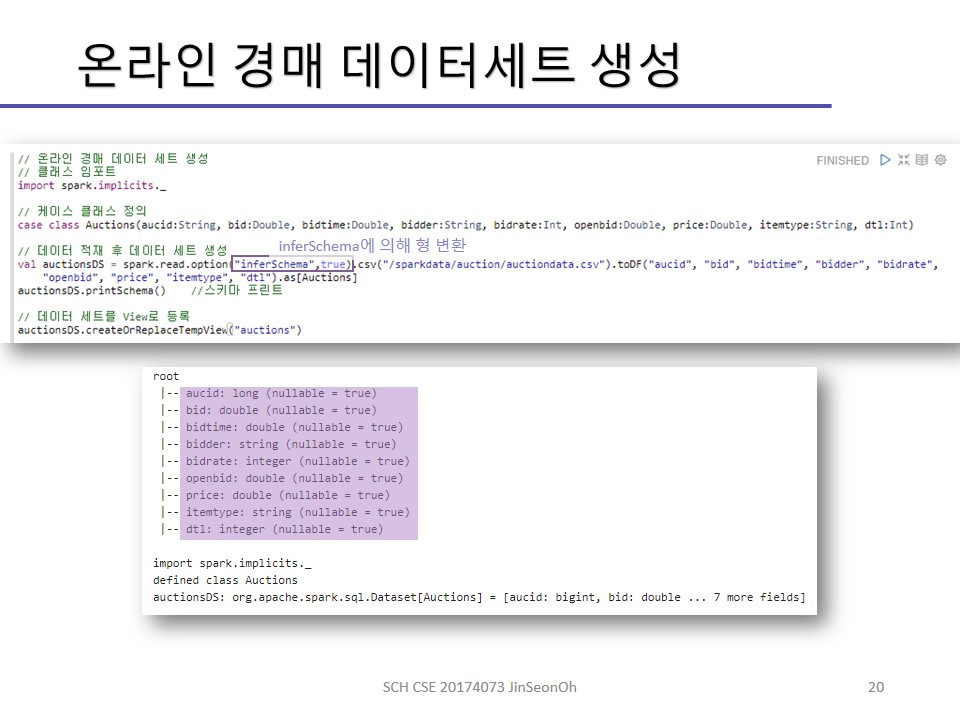
데이터세트 연산 절차를 정리하면 아래 순서로 이루어집니다.
- 데이터세트 정의
- 변환 정의
- 액션 적용
- 값을 리턴
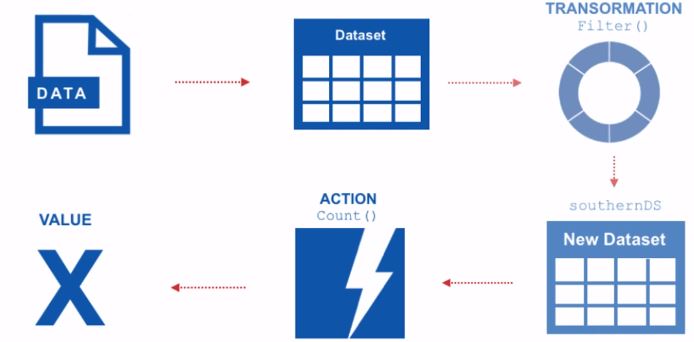
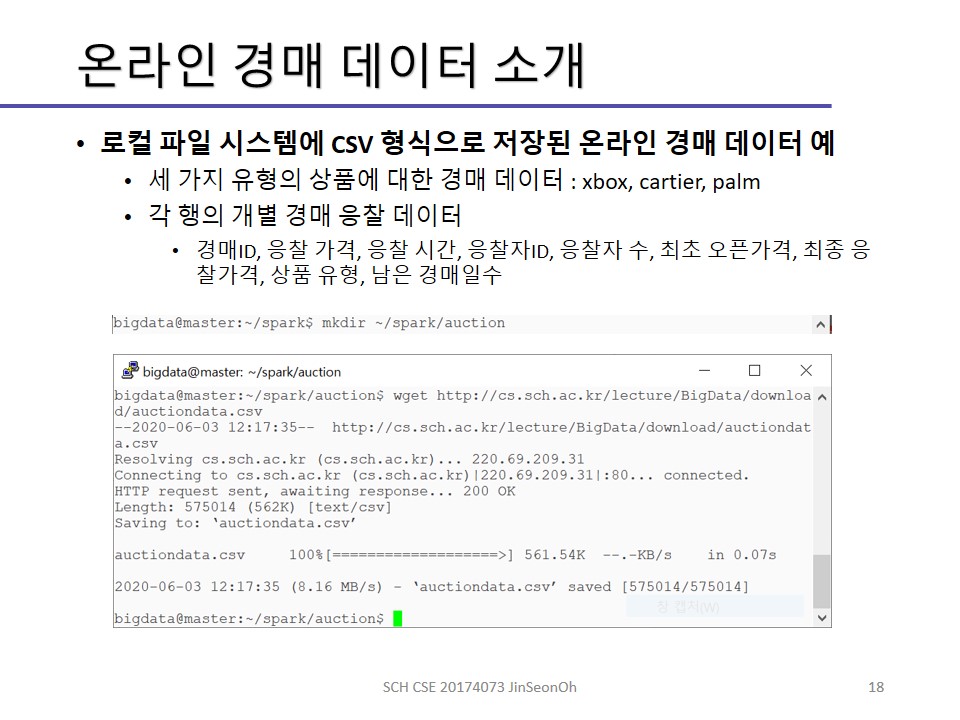
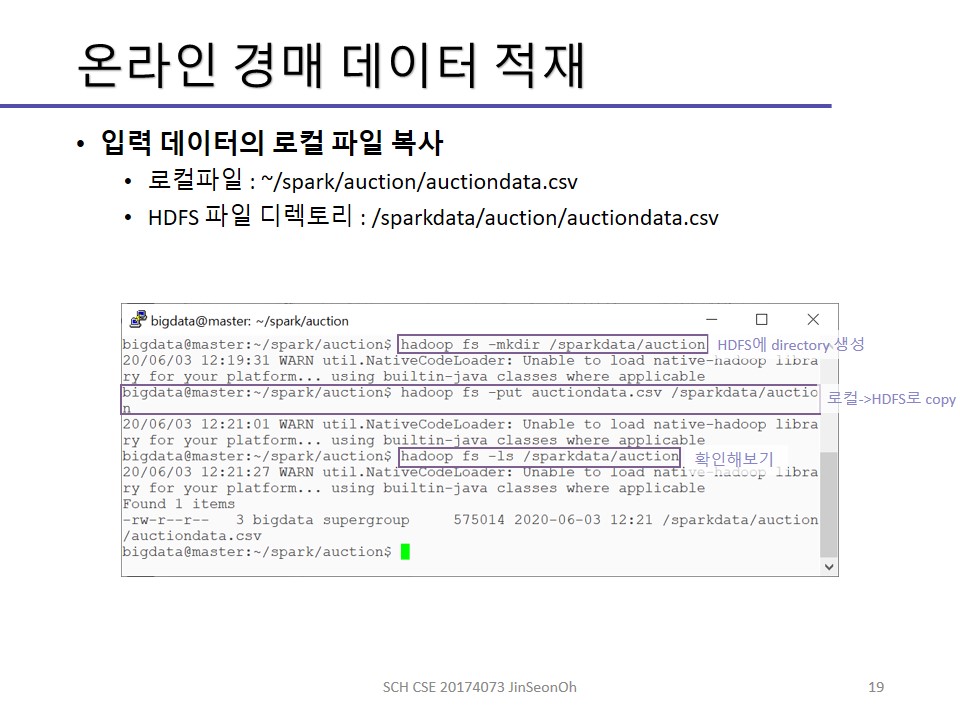
실습한 내용에 대한 이미지를 실어놓겠습니다.

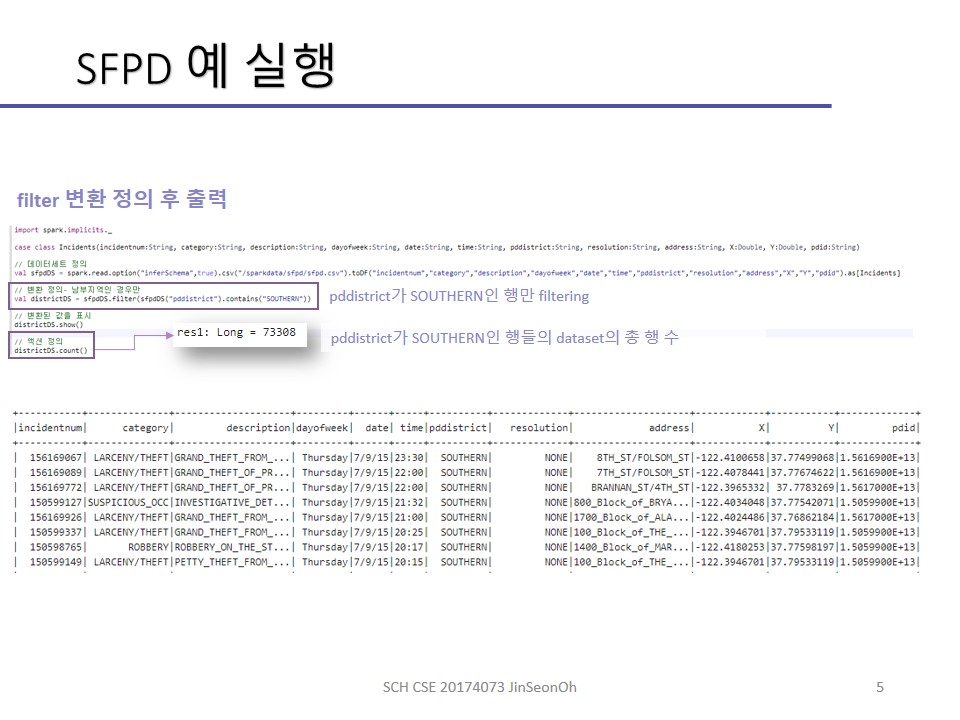
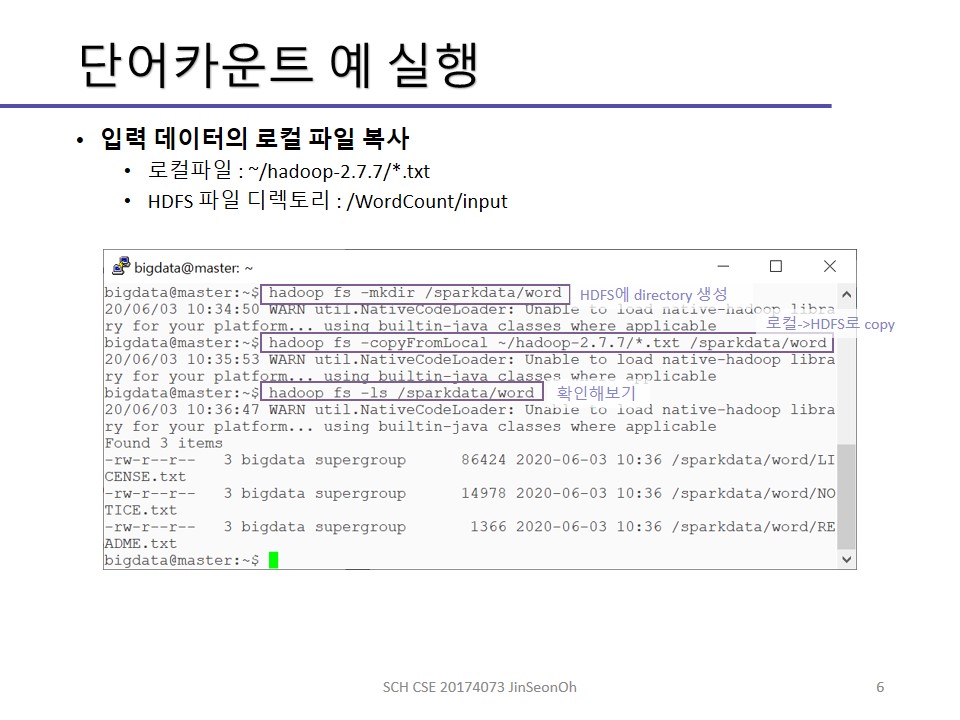
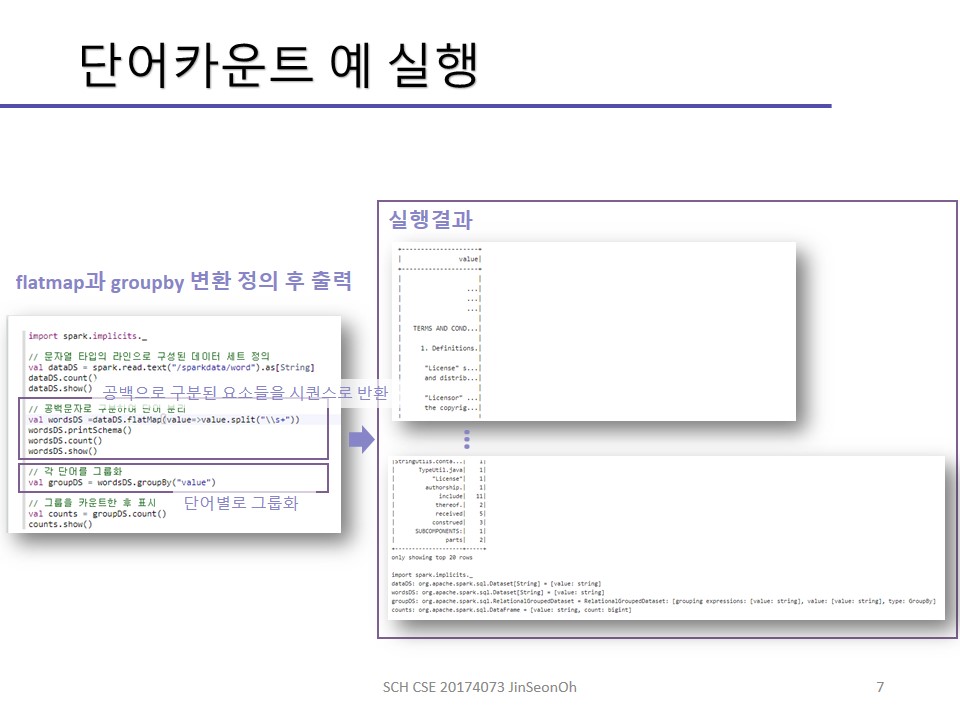


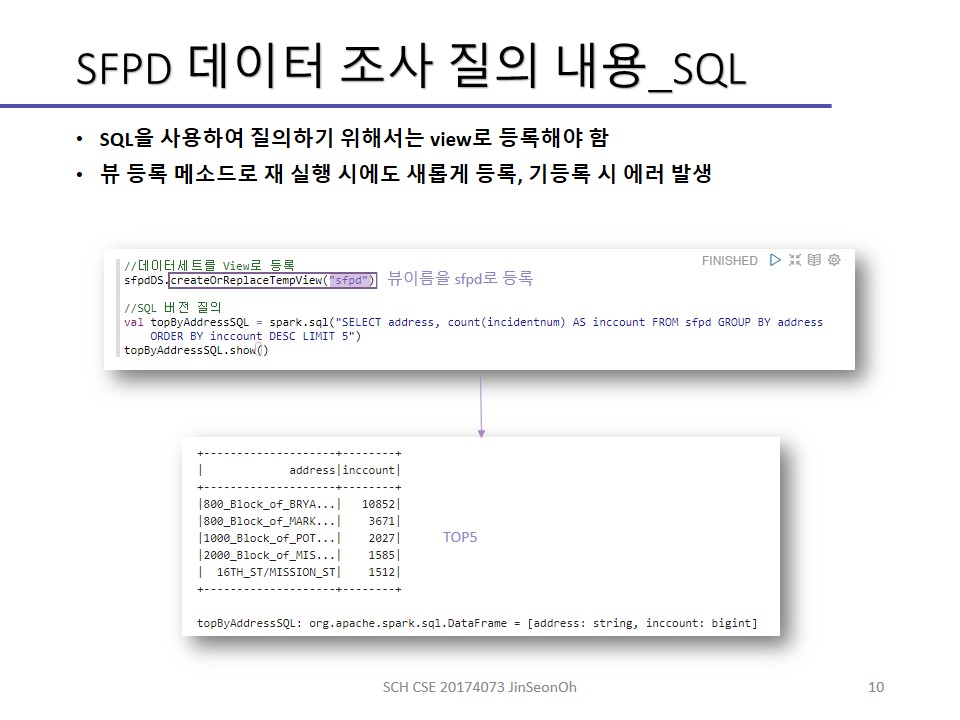
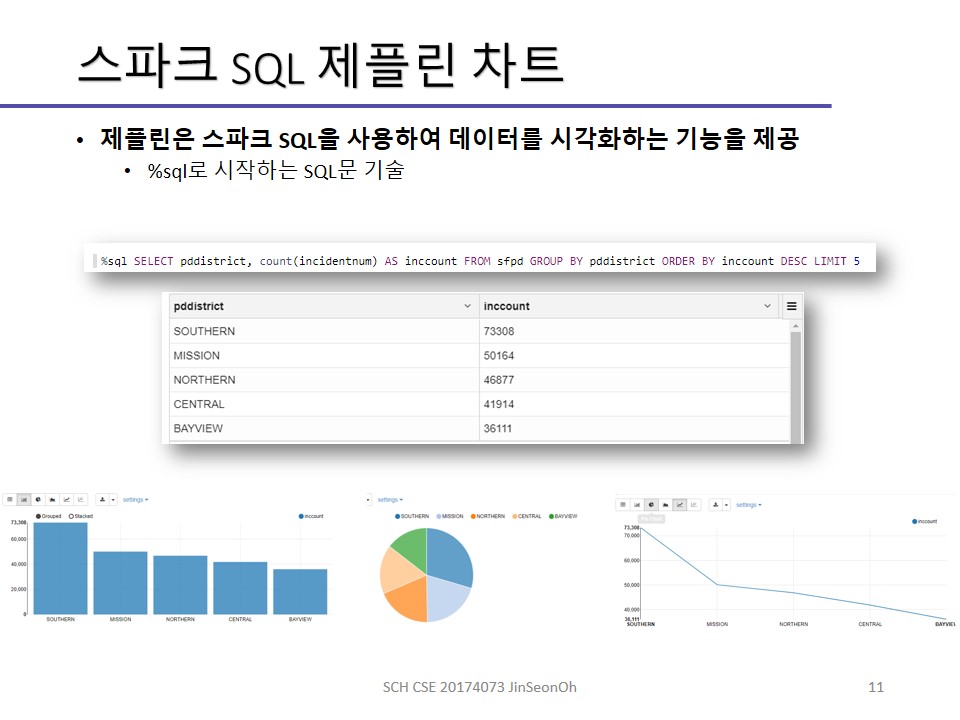
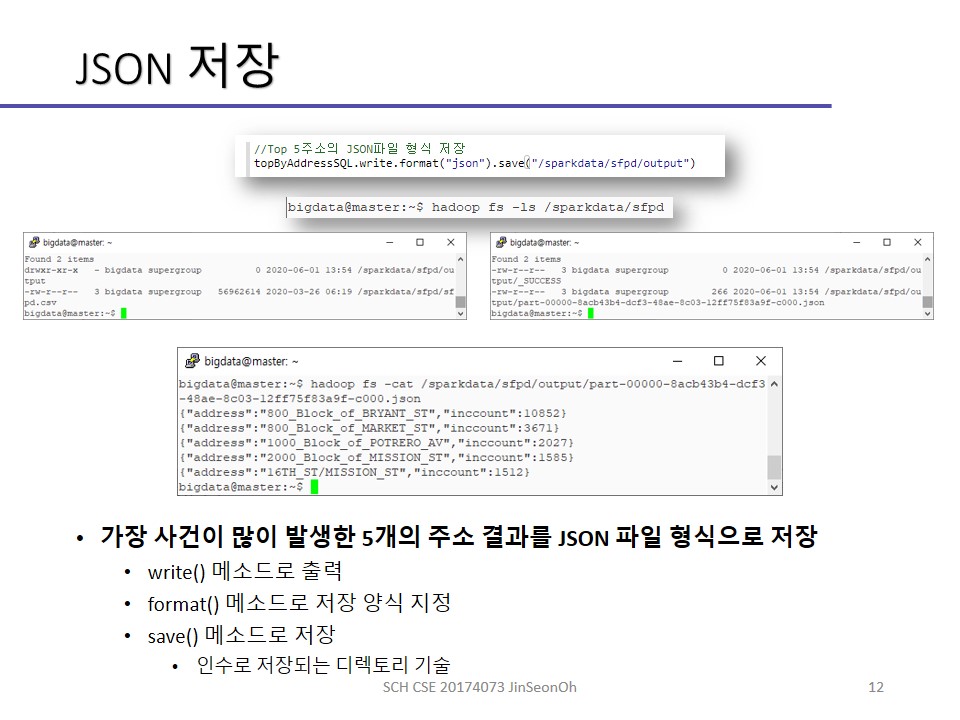





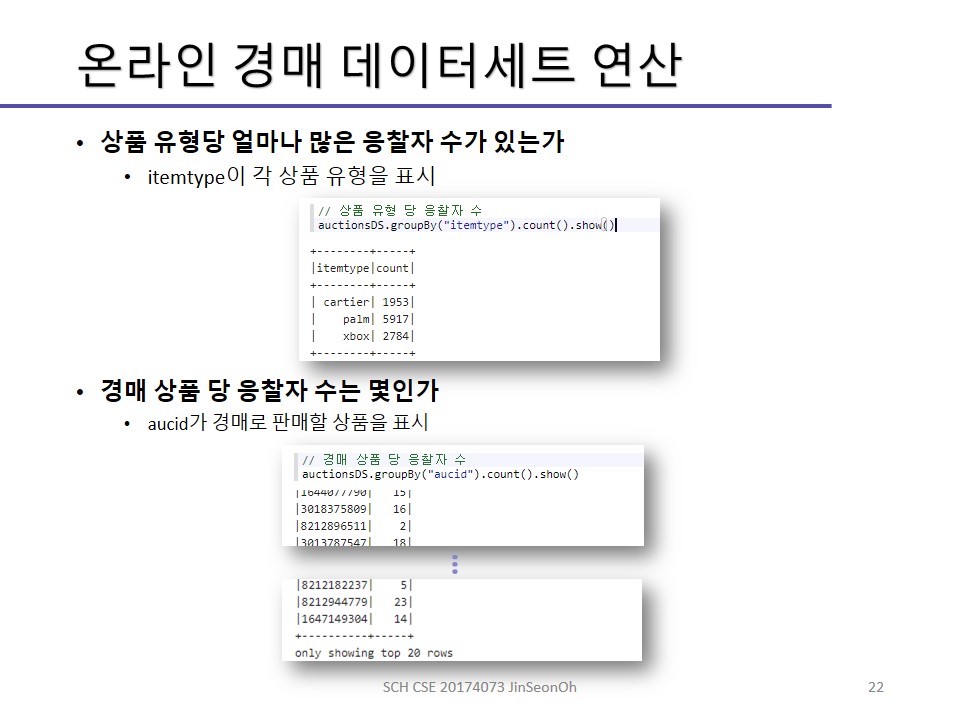
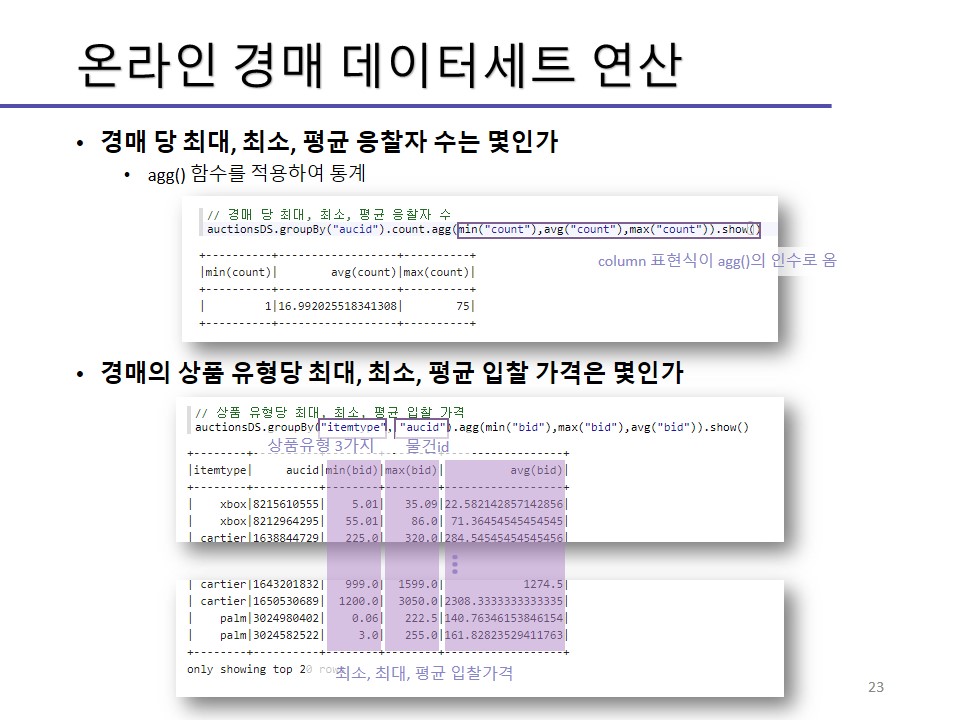
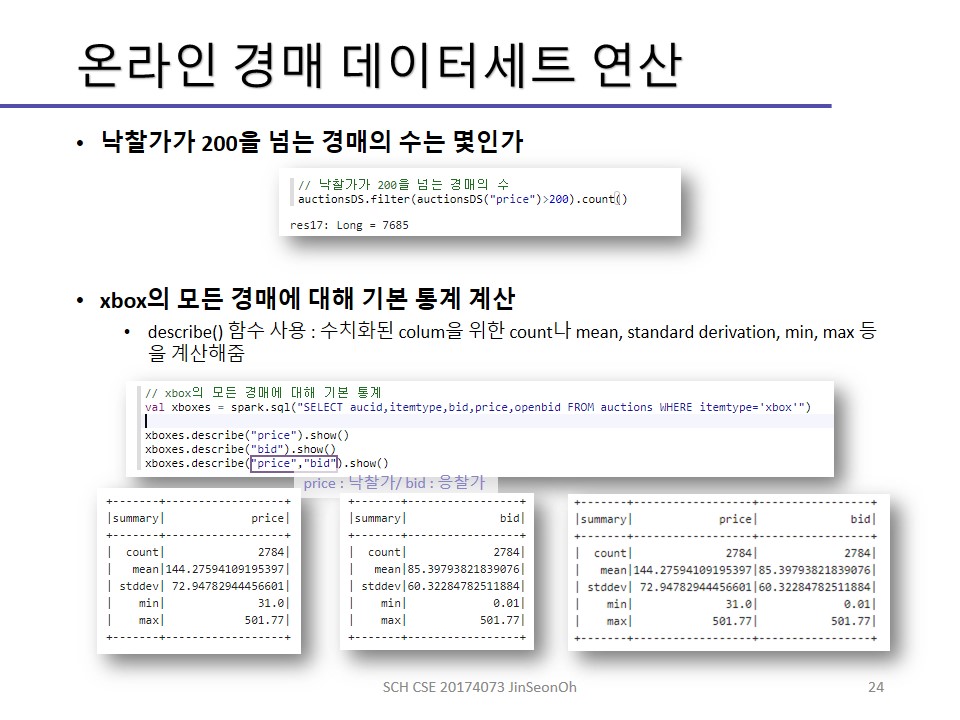
개인이 공부하고 포스팅하는 블로그입니다. 작성한 글 중 오류나 틀린 부분이 있을 경우 과감한 지적 환영합니다!