
Ensemble_Machine Learning(11)
Intro
학교 수강과목에서 학습한 내용을 복습하는 용도의 포스트입니다.
그래서 이 글은 순천향대학교 빅데이터공학과 소속 정영섭 교수님의 “머신러닝” 과목 강의를 기반으로 포스팅합니다.
기존에 수강했던 인공지능과목을 통해서나 혼자 공부했던 내용이 있지만 거기에 머신러닝 수업을 들어서 보충하고 싶어서 수강하게 되었습니다.
gitlab과 putty를 이용하여 교내 서버 호스트에 접속하여 실습하는 내용도 함께 기록하려고 합니다.
이번 시간에는 앙상블을 배웁니다.
Ensemble
기계학습에서의 앙상블의 기본 motivation은 바로 “다구리엔 장사 없다”입니다.
앙상블(Ensemble)이란 여러 분류기들의 집합체이며 이들의 결과들을 합쳐서 최종 결정을 짓는 기법으로 정확도가 크게 향상될 수 있습니다.
이러한 앙상블에는 여러 메소드들이 존재합니다.
bagging, boosting, stacking 등이 있습니다.
Bagging과 boosting이 많이 쓰이고 있습니다.
하나의 선형만 표현하는 선이 3개가 모여 decision boundary를 생성합니다.
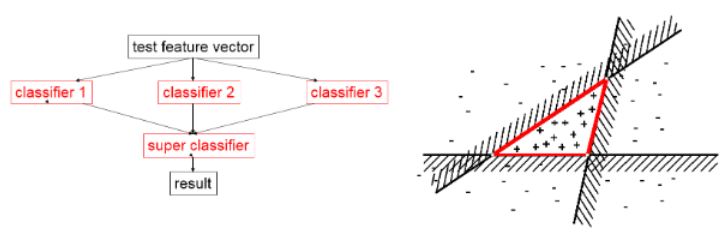
앙상블은 여러모델을 함께 사용해서 상위패턴을 인식할 수있다는 점에서 ANN과 비슷해보일 수 있는 모델입니다.
어쩌면 Perceptron을 여러개 함께 써서 아주 복잡한 비선형 패턴을 인식할 수 있다는 점에서 ANN도 일종의 앙상블 기법을 사용한 모델일 수 있습니다.
Boosting
N개의 데이터개수와 M개의 모델개수가 있다고 가정합시다.
대부분 N > M인데 모델이 일정데이터씩 완벽히 담당해주면 결국모든 데이터들을 다 커버할 수 있지 않을까? 하는 취지에서 만들어진 모델이지요.
이를테면 데이터 100개고 모델 10개면 모델 1개당 데이터10개씩 맡는다던지요.
모델마다 어떤 데이터를 담당할지 여부를 데이터에 대한 weight로 관리합니다.
초기 버전에서는 각 weak learner(성능이 그저그런 모델)가 서로 다른 샘플된 데이터를 사용하여 학습됩니다.
학습이 완료된 모델에서 어려웠던 데이터(오분류된 데이터)들에 집중하기 위해 weight를 높여준 후, 다음 round의 learner에서 그 데이터들과 같은 양의 데이터로 샘플링하여 학습 데이터로 사용합니다.
결국은 weak learner들이 모여 학습에 집중할 수 있도록 해주며, 통째로는 강력한 성능의 분류기로 역할을 할 수 있게 해주는 기법이라 할 수 있습니다.
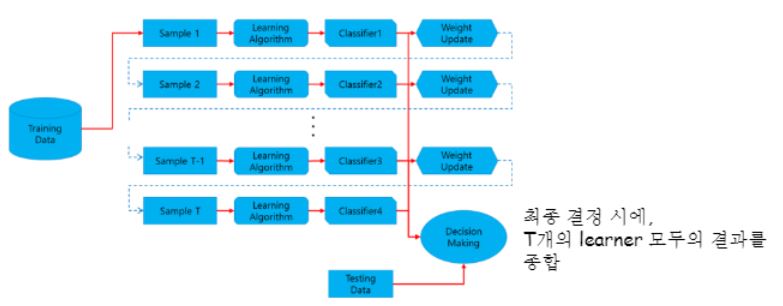
원본에서 샘플링되어서 나온 dataset 으로부터 learner(classifier)에 할당합니다.
오분류된 데이터에 대해서 weight를 높게 업데이트시켜주면서 weight가 더 큰 데이터일수록 “얘가 더 중요해”가됩니다.
그림 보시면 아시겠지만 각각마다 classifier가 있는 거에요.
그럼 뒤에있는 모델이 가장 훌륭한 모델이 되지 않을까요?
새로운 데이터가 들어오게되면 t개의 classifier가 한번씩 다 예측을 하는거죠.
그리고 그 의견들을 모아서 최종 결과를 내는겁니다.
AdaBoost
Boosting의 대표자는 AdaBoost (Adaptive boosting) 알고리즘입니다.
Adaboost는 기본 boosting 아이디어와는 조금 다르게, 각 weak learner들이 모두 같은 데이터를 사용합니다.
학습 시작 시 각 인스턴스에 동일한 weight가 부여되지만, 학습 과정에서 각 데이터에 대한 개별 weight를 조정하게 됩니다.
그렇다고 하더라도 여러개의 모델이 모여서 하나의 결과를 도출하는 것으로 하나의 모델을 사용하는 것보다 성능이 좋습니다.
최종 결정시에도 learner들의 weight를 고려한다는 특징이 있습니다.
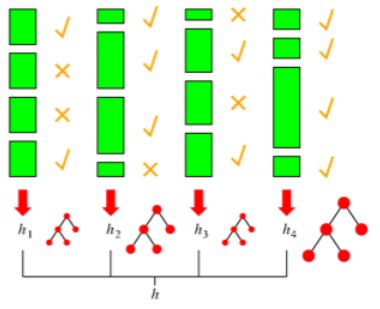
네 개의 weak learner 모델(hypothesis) h1 ~ h4까지 있다고 합시다.
통합 모델을 h라고 하겠습니다.
녹색 막대들은 개별 데이터입니다.
각 데이터들의 길이가 다른 것을 보실 수 있을 겁니다.
길이는 그 데이터에 대한 weight를 의미하는 것입니다.
1 round에서의 모델이 틀렸던 어려웠던 데이터들은 x표시를 해두고 가중치를 높였네요.
모델별 weight 크기에 따라 트리를 크게 그렸네요.
AdaBoost의 알고리즘은 아래와 같습니다.
- 모든 데이터의 weight를 1로 초기화합니다.
- 각 h1~h4에 대하여 순서대로 hi번째 모델을 학습중이라면 hi-1번째 모델이 틀리게 예측한 데이터의 weigth를 증가시킵니다.
- 새로운 데이터 x에 대해 테스트할 때는, 모든 h1~h4를 대상으로 ‘weighted majority’를 계산하여 최종 결과를 도출합니다.
예를 들어 h4는 다 맞췄으니 weight가 가장 큽니다.
이론적으로 AdaBoost는 Original learning algorithm A가 있을 때, A의 accuracy가 50보다 약간이라도 높다면, 충분히 많은 수의 A를 합치게 되면, 학습 데이터에 대해서 완벽하게 동작하는 통합모델을 만들수 있다고 말합니다.
실제로 성능도 꽤 높아요
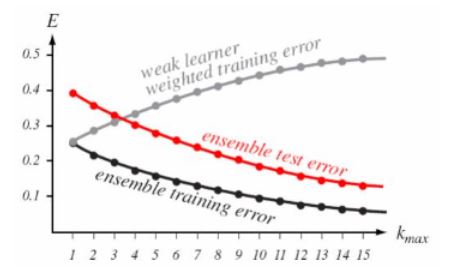
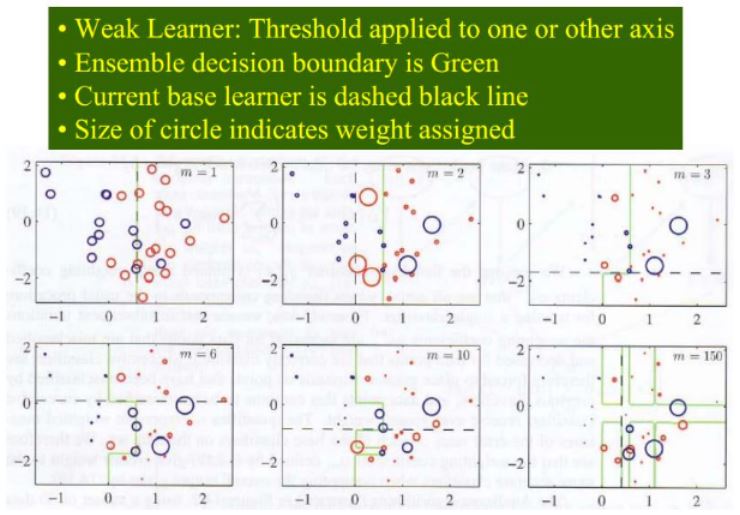
바이너리 분류기 예제를 보여주네요.
최종적인 decision boundary가 모델이 조합되면서 점차 고차원으로 그려진다는 것을 알 수 있습니다.
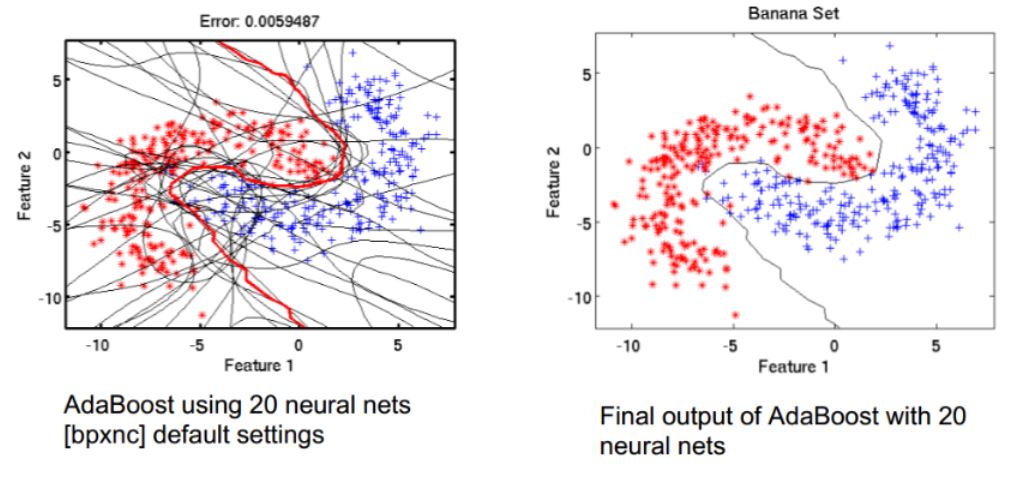
또 다른 예시인데 뉴럴네트워크를 스무개 만들어서 쓴거고, 오른쪽은 디시젼트리를 20개 모아 만든 것으로 앙상블기법으로도 성능이 꽤 높게 나온다는 것을 보여주는 그림인 듯합니다.
참고로 Decision tree를 가지고 만든게 Random Forest입니다.
Bagging
Bagging은 Bootstrap AGGregation 이라는 데서 이름을 따왔습니다.
만약에 우리에게 엄청나게 많은 당구공들이 있다고 합시다.
근데 그 중에서 내 가방에 들어갈 수 있는 당구공 개수는 10개밖에 안된다고하면 전체 당구공에서 10개를 뽑아넣겠지요?(=샘플링)
그렇게 열개씩 찬 가방이 n개 있습니다.
원래 바닥에 있던 당구공을 집어서 가방에 넣었으니까 원래같으면 그 당구공은 바닥에 더 이상 없어야하는건데 그대로 있어요. 이를 복원 샘플링이라고 합니다.
왜 이런게 나왔냐하면 복원되지 않으면 한쪽에 들어간 데이터가 다른 쪽 가방에도 들어갈 수 있는거죠.
그것이야 말로 전혀 서로 영향을 받지 않는 것일테니까요, 이러한 특징은 각 learner들이 독립적으로 학습된다라는 의미입니다.
아주 중요한 특징입니다.
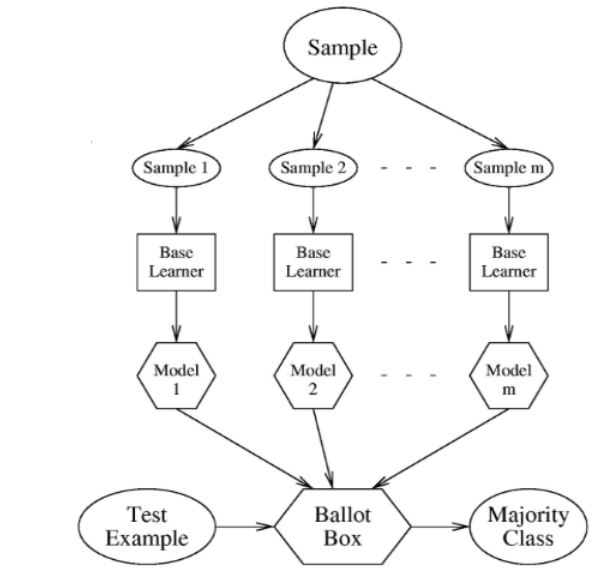
이렇게 학습이 되었고 최종결과를 산출할 때 모델별로 나온 결과들에 대해 uniform voting(aggregation)을 시행하곤 합니다.
한표씩이라고 생각해서 uniform이요!
그럼 한표씩이 아닌 것도 있나요?
네
서로 다른 weight에 의해서 더 강하고 덜 강한 투표권을 가질 수 있습니다.
그래서 앙상블을 연구하는 사람들은 어느 모델들끼리의 조합을 하는 것이 좋을까도 연구를 많이 하겠지만 voting 방식에 대해서도 많은 연구를 하고 있습니다.
Sampling
샘플링 시 사용되는 용어 중에 down sampling이 있고 upsampling이 있습니다.
샘플링이 다운이고 업이라는 것은 뭘 말하는 걸까요?
하마가 100마리 기린이 10마리 있다고 하면 데이터 불균형이죠?
이 데이터들에 대해서 모델을 생성하게되면 눈감고 걍 하마야! 해도 성능이 90퍼 이상이 나올 수 있거든요.
그래서 이런 이슈를 해결하는 방법중 하나가 다운샘플링과 업샘플링인 것입니다.
다운 샘플링은 하마 100마리 중에서 기린하고 마리수를 맞추기위해서 딱 10마리만 데리고 오는 것입니다.
그럼 밸런스가 맞잖아요?
100에서 10로 갔으니까 다운샘플링입니다.
반대로 업샘플링의 경우는 원래 10마리밖에 없던 기린을 100마리로 늘려주는거에요.
어떻게 가능할까요? 여러 방법론이 있긴 합니다. 나머지 90개의 데이터는 fake data라는거에요.
가짜데이터로 늘려서 up sampling해주는게 down sampling 보다 일반적으로 더 좋긴해요.
하지만 얼마나 진짜 데이터처럼 만들 수 있는가가 관건이겠지요.
이러한 기술을 GAN 이라고 부릅니다.
사실 GAN은 뉴럴넷을 통해서만 나올수 있는 모델은아니지만 대부분 nueralnetwork 를 응용해서 구현하곤 하지요.
이렇게 upsampling이나 downsampling 또는 cost sensitive learning 따위를 통해서 데이터 불균형을 해소하곤 합니다.
cost sensitive learning은 뒤 포스트에서 소개됩니다.
데이터를 일단 엄청 불려놓고 se-mi supervised learning을 통해서 데이터 불균형을 해결할 수도 있는데 이 방법이 가장 좋은 방법입니다.
Random forest
Decision tree 가 루트 노드부터 leaf node 방향으로 임의의 feature를 고려하면서, 데이터를 분류했던것을 기억해봅시다.
데이터가 다르면 생성되는 tree가 서로 다르게 나올거란말이죠.
왜냐하면 Information Gain이 젤 큰 feature를 선택하면서 트리를 만드는 거니까요.
매번 바뀔수도 있는건데 그러지말고 트리 모양에 대해서도 그럼 voting 해서 쓰면 어떨까하는 취지가 바로 random forest입니다.
총 n개의 학습데이터가 있다고합시다.
Bagging에 의해서 임의의 k개의 bag을 만들어봅시다.
각각의 bag들은 복원 샘플링이니까 물론 같은 데이터도 있긴 하겠지만 완전히 똑같긴 어렵겠죠..?
어쨌든 서로 다른 decision tree가 만들어질겁니다.
아래 그림에서는 서로 다른 세 개의 트리가 나왔습니다.
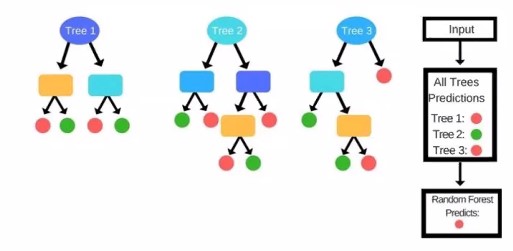
테스트 해야할 데이터가 들어온다면 트리 1,2,3이 서로다른 답을 낼 수도 있겠죠?
그렇다면 모두가 한표를 가지고 있다고 하고(uniform), 다수결에 의해서 최종결과는 만들어지게 될 겁니다.
이러한 random forest는 어마어마한 성능을 보여줍니다.
물론 데이터 양만 충분하다면 neural network를 사용하는게 훨씬 잘 나오겠지요.
RF는 여러분이 현업에서 어떤 문제를 해결하려할 때 꼭 시도해 볼 만한 모델이 될겁니다.
RF는 두가지 큰 장점이 있습니다.
첫번째는 빠르다입니다.
두번째는 explainable model이라는 것입니다.
DNN은 성능은 높은대신에 설명이 불가능하다는 단점이 있으니까요.
백짓장도 만들면낫지 물론 이런 말도 맞을 수 있으나 이건 아주 기본적인것만 이해해버린거에요 앙상블에 대해서.
예를 들어서 버스가 옆으로 쓰러지려해요.
이걸 다같이 합쳐서 밀어내자 하면서 한쪽에서 만 다닥다닥붙어서 밀고있다고 한다면 과연 잘 세울 수 있을까요?
바로 이런 고민들이 앙상블을 사용할 때 필요한 것입니다.
단순히 tree가 여러 개 생성되었기 때문에 성능이 높다고 하는 걸까요?
Decision tree는 단순하고 빠르지만 bias는 작고 variance는 큽니다.
즉 noise에 매우 민감합니다.
Decision Tree를 배울 때도 설명하긴 했었지만, 트리가 커지게 되면 overfitting 가능성이 큽니다.
샘플데이터를 취한다는 것은 쪼개버리게 되니까 tree의 bias는 유지하면서 variance는 작게 만드는 것입니다.
각 tree는 서로 독립적으로 학습되었으므로 통합된 의사 결정 시 noise에 의해 강해지게 됩니다.
Random Forest 생성을 위해 bagging이 이용되는 것을 봤는데, 이외에도 ‘임의노드 최적화 방법’이라는 것을 통해 random forest의 randomness를 강화하기도 한다고 합니다.
randomness를 강화한다는 것 = variance는 약해지고 noise에는 강해진다는 뜻
더 다양한 모델이 만들어지니까 앙상블 모형이 더욱 강력해질 것이다 라는 것이죠.
앙상블 심화
배깅과 부스팅의 가장 큰 차이점은 무엇일까요?
알고리즘 자체의 차이를 보자면 부스팅은 보다시피 샘플링을 하는 그다음번에 모델의 weight를 classifier에 기반해서 결과를 확정한다는거에요.
그러니까 그 이전 round에 영향을 받는다는 뜻이에요. 그 경험을 가지고서 학습한다는 말이지요!
정리하자면 부스팅의 가장 큰 특징은 다음단계의 weak classifier가 이전 단계의 weak classifier의 영향을 받는다는 점입니다.
반면에 배깅은 독립적으로 학습된다고 했었죠?
하지만 결국 부스팅이건 배깅이건 다 여러 개의 모델에서 만들어지는 결과를 합쳐서 하나의 최종결과를 만들어낸다는 점에서 공통적으로 앙상블 모형이라할 수 있는것이구요.
투표방식에서도 그 voting이 uniform voting이냐 weighted voting이냐에 나뉘게 됩니다.
자주 이용되는 최신 부스팅 기법으로는 XG boost가 있습니다.
앙상블 기법은 왜 overfitting에 강하다고 알려져 있을까요? Too strong learner를 만드는 것이 아닌 many weak learner를 만드는 것이고 여러 weak learner들(트레이닝 데이터에 대해 정확도가 높지 않았던 모델 포함)의 결과를 종합하기 때문
벽이 무너지는 것을 막을 때 모두가 넓게 서서 각 부분을 담당하는 셈이 됩니다.
지도학습 모델을 위주로 공부하다보니 분류 모델들을 많이 배우게 되었습니다.
여태까지 배운 내용을 기반으로 EDA부터 모델링까지 실습해보았습니다.
실습 링크 : https://gitlab.com/ohjinjin/machinelearning/-/blob/master/prac008.ipynb
개인이 공부하고 포스팅하는 블로그입니다. 작성한 글 중 오류나 틀린 부분이 있을 경우 과감한 지적 환영합니다!