
YOLOv2 darkflow on python(3)
환경 설정 및 darkflow 설치 : YOLOv2 darkflow on python(1)
다중 객체 탐지 테스트 코드 작성 및 실행: YOLOv2 darkflow on python(2)
Make own Dataset
이제 자가 데이터를 확보하여 커스텀 학습을 진행해보려고합니다.
탐지하고자 하는 객체의 사진들을 객체별로 여러 각도, 여러 환경에서 여러장 찍습니다. 데이터가 많을 수록 물론 성능이 좋아지겠지요.
이후에 리사이징과 어노테이션을 해줘야하는데, 어노테이션 툴은 labelImg나 YOLO-marker 등이 있습니다. 편하신 걸로 사용하시면 됩니다.
labelImg를 사용하여 학습데이터의 전처리를 하는 과정은 여기에서 다운로드 받아 사용하시면 됩니다.
YOLO-Marker를 사용하여 학습데이터의 전처리를 하는 과정은 여기에서 다운로드 받아 사용하시면 됩니다.
제 프로젝트의 경우 총 1,395장의 데이터가 있지만 31개의 클래스가 존재하며 각 클래스별 45장의 원본데이터가 있습니다. 적은 편이지요..
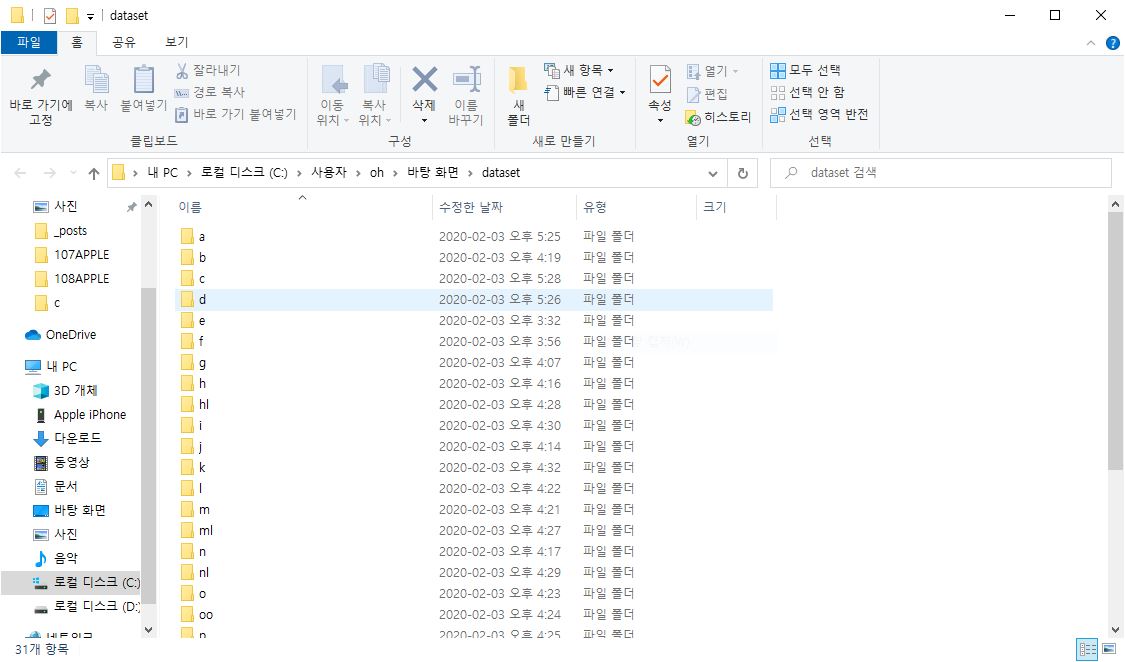
그래서 성능을 더 좋게 하기 위해 keras에서 제공하는 어파인변환(회전, 확대, 이동) 함수를 통해 데이터를 불려줍니다.
https://ohjinjin.github.io/machinelearning/augmentation/
y축 대칭이동 같은 경우는 특히나 필요하겠다고 판단한 이유가 왼손잡이와 오른손잡이에 있었습니다.
Training on your own dataset
그 다음은 미리 만들어져있는 욜로의 네트워크를 이용하여 모델을 학습시키는 단계입니다.
저는 LabelImg를 이용하여 Annotation 작업을 완료하였습니다.
https://ohjinjin.github.io/machinelearning/darkflow-5/
(콘솔에서 미리 다운 받아놓은 darkflow 폴더로 이동한 후 setup.py를 빌드해줍니다.
python setup.py build_ext --inplace
) (여기 삭제할지 고민중)
여러분의 프로젝트에 맞게 클래스를 분류하면서 .cfg 파일의 내용을 수정해줍니다.
예를 들어 저는 수화 지문자를 번역하는 용도의 프로젝트를 진행 중이기 때문에 ㄱ~ㅟ까지 총 31가지(쌍자음의 경우 같은 단자음을 두번 연속으로 동작하여 표현)의 지문자 클래스를 가지도록 설계합니다.
컨볼루셔널 레이어의 파라미터들도 원하는 대로 변경해줍니다.
기존에 있던 레이블을 모두 삭제하고 labels.txt에는 학습하려는 정답 레이블들을 모두 기재합니다. 제 경우 31가지의 레이블을 모두 작성하였습니다.
다음으로는 darkflow/cfg 폴더 내의 cfg 중 사용할 모델의 cfg를 자신의 문제에 맞춰 수정해줍니다.
저는 이렇게 복사본을 만들어서 이름을 my-tiny-yolo.cfg로 수정한 뒤 메모장으로 열어서 변경하여 사용하였습니다.
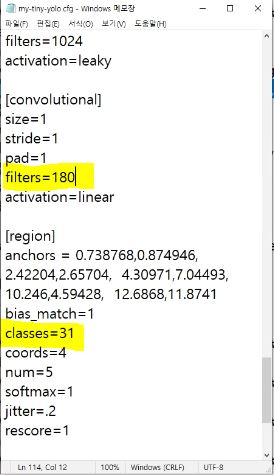
[region]의 classes를 총 분류하고자하는 클래스의 수로 변경하고, 가장 마지막 [convolutional]의 filters 속성을 (5+classes)*9의 결과값으로 변경해주세요.
(darknet에서는 filters를 (5+classes)*5로 설정했었는데 필터크기를 원하는대로 홀수 정방행렬중에서는 골라 사용이 가능한건지?_?)
filters 관련 참고자료 : https://www.youtube.com/watch?v=9s_FpMpdYW8
그 다음, 학습시킬 데이터를 아래와 같이 두 개의 폴더를 이용하여 이미지 데이터를 위한 폴더와 annotation 작업을 위한 폴더로 나눠서 주세요.

여기까지 학습을 위한 준비가 완료되었다면, darkflow 폴더에서 아래 명령어를 통해 학습을 시작하시면 됩니다.
데이터셋의 경로는 여러분의 환경에 맞도록 수정해주세요!
python flow --model ./cfg/my-tiny-yolo.cfg --labels ./labels.txt --trainer adam --dataset d:/data/dataset/ --annotation d:/data/annotations/ --train --summary ./logs --batch 5 --epoch 100 --save 50 --keep 5 --lr 1e-04 --gpu 0.5
참고로 위 명령어는 처음 가중치 학습의 경우 사용하는 명령어고, 이전에 학습된 가중치를 이어서 학습할 경우에는
python flow --model ./cfg/my-tiny-yolo.cfg --labels ./labels.txt --trainer adam --dataset ../data/dataset/ --annotation ../data/annotations/ --train --summary ./logs --batch 5 --epoch 100 --save 50 --keep 5 --lr 1e-04 --gpu 0.5 --load -1
이렇게 된다고 합니다.
캡처는 8번 epoch 후의 로그입니다!
보통 일정 loss값에 수렴한듯 보이더라도 15000번정도 학습을 거치는 것이 좋은 성능을 내는가봅니다.
혹시 학습 시도 시 아래와 같은 에러를 만나게 된다면 그 에러는 아까 언급한 cfg 파일에서 마지막 층의 classes 수와 filter수가 맞지 않아서 생기는 오류로 이 글의 본문에서대로라면 my-tiny-yolo.cfg 파일을 다시 맞게 수정해주셔야합니다!
tensorflow.python.framework.errors_impl.InvalidArgumentError: 2 root error(s) found.
우리는 학습 중 TensorBoard로 도식화된 epoch 별 loss 변화를 확인하실 수 있습니다.
tensorboard에서는 학습이 경과됨에 따라 loss함수값을 그래프로 그려줍니다.
log파일의 위치만 기재해주면 아래와 같이 확인하실 수 있습니다.
log 파일은 darkflow/logstrain 디렉토리에 위치하게됩니다.
conda prompt를 하나 더 열어서 darkflow가 설치되어있는 가상환경이 활성화되어있으며, darkflow에 위치해있다는 전제에서 아래 명령어를 입력해주시면 됩니다.
tensorboard --logdir=./logstrain/
그러면 6006 포트에서 텐서보드를 확인할 수 있을 거라고 로그가 뜰겁니다!
브라우저를 실행시키고 localhost:6006으로 접속하면 아래와 같은 화면을 만나보실 수 있습니다.

차트로 보이다시피 ..
14000 epoch 가까이 학습시켜보았는데, 13200epoch쯤 학습을 일시 중단하고 validation set으로 테스트해보았을 때, 성능이 크게 좋지 않아서 데이터셋에 대해 다시 전처리부터 학습까지 갈아엎을 예정입니다.
ㅠㅠ
(수정중)
지문자를 바꿔 동작하는 순간을 어떻게 알고 캡처할지?
비슷한 프로젝트한 분들 것 참고해보면 삼초에 한번씩 감지한것 같은데
=>디바운스 & 스로틀 알고리즘 알아보기
(지문자 캡처 이후 텍스트를 완성시키고 NLP?regression model 확인 )
강화학습 데이터가 적은 경우 합당할까에 대해 공부도 해보려고합니다.
(수정중)
SignLanguageTranslator
anaconda navigator를 켭니다.
그리고 미리 생성해두었던 가상환경을 활성화시킵니다.
해당 가상환경 안쪽에서 jupyter notebook을 실행시키고 새로운 python 프로그램을 만들어줍니다.
conda activate singLanguageTranslator
cd C:\Users\oh\AppData\Local\Continuum\anaconda3\envs\signLanguageTranslator\darkflow
jupyter notebook
여기까지 혹시 잘 따라오지 못하신다면 이 글의 상단에 걸어둔 앞서 작성한 포스트들의 링크를 따라 선행단계를 마친 후 아래를 읽어주세요!
자세한 코드는 여기에 업로드해두었습니다. 참고해주세요!