
Analyzing kNN model with titanic data of kaggle
#DSC활동 #ML
캐글 데이터 타이타닉를 응용하여 EDA(Exploratory Data Analysis)를 포함한 데이터 마이닝부터 모델링까지 정말 잘 되어있는 실습 레퍼런스를 얻게 되었습니다. 그래서 저는 그 자료에서 적용된 모델링 기법 중 하나였던 k-NN을 사용된 데이터에 맞춰 자세히 뜯어보려고 합니다.
(출처 : https://github.com/minsuk-heo/kaggle-titanic/blob/master/titanic-solution.ipynb)
그 전에 앞서 k-NN에 대하여 간단히 설명하고 정리하고 시작하겠습니다.
k-NN(k-Nearest Naighbors)란?
k-NN(k-Nearest Naighbors) 알고리즘은 아주 간단한 머신러닝 알고리즘입니다. 훈련용 데이터셋을 그저 저장하는 것이 모델을 만드는 과정의 전부입니다. 새로운 데이터에 대해 어느 클래스인지를 예측할 땐 k-NN 알고리즘에 의해 특징 공간 내에서 새로운 데이터의 좌표로부터 훈련 데이터 셋들이 자리매김한 각각의 좌표까지의 거리 차 중 가장 가까운 k개의 이웃 데이터들의 클래스를 보고 다수결로 해당 데이터의 클래스를 예측하게 되는 것입니다.
아래 그림에서 예를 들어보겠습니다.
만약 k가 3으로 주어진다면
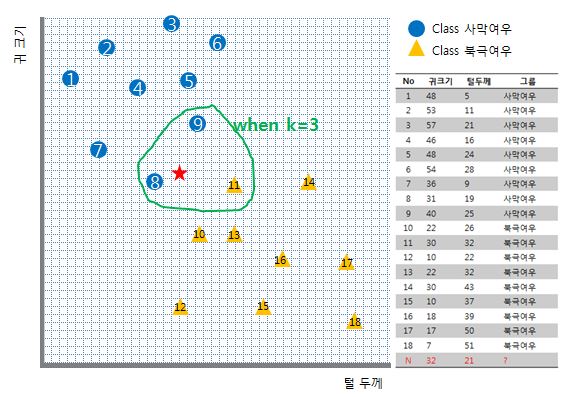
새로운 데이터인 빨간 별은 사막여우로 투표될 것 입니다.
하지만 만약 k가 5로 주어진다면
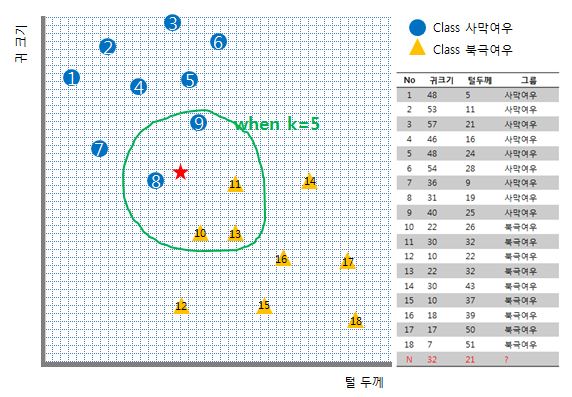
새로운 데이터인 빨간 별은 북극여우로 투표될 것 입니다.
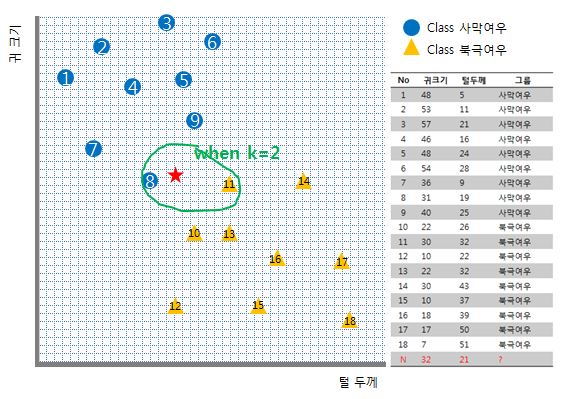
그러다보니 제 예제처럼 두 개의 클래스만이 있는 바이너리 분류기에선 k를 짝수로 두게 되면 혼란스러운 상황이 유발됩니다. k가 2일 경우 가장 가까운 이웃 데이터 하나는 클래스 사막여우, 또 다른 하나는 클래스 북극여우라면 말이죠! 이는 k를 결정할 때 고려해줘야 할 사항입니다.
k-NN의 특징
간단하죠? 하지만 k-NN 모델은 치명적인 장/단점이 존재합니다. 학습 시간 소모는 제로인 반면, 테스트 수행 시간 소모가 아주 크다는 점입니다.
인간은 보통의 경우 잠깐만 그림을 보고서도 가장 가까운 데이터를 금방 골라낼 수 있지만 컴퓨터는 그렇지 않습니다. 컴퓨터는 새 데이터와 모든 데이터 사이의 거리를 측정하고나서야만 가장 가까운 k개의 이웃을 결정할 수 있기 때문입니다.

이 그림에서는 11 데이터와 새로운 데이터의 (귀 크기, 털 두께)를 각각 (x2, y2), (x1, y1) 튜플로 치환하였습니다. 그림에는 하나의 데이터하고의 거리만 측정했지만, 실제 k-NN 시행 시에는 저렇게 특정 한 데이터와의 거리만 조사하는 것이 아니라 누가 가까울지를 알 수가 없기 때문에 1~18까지 모든 데이터와의 거리를 계산해야한다는 것이죠.
저는 간단한 예제를 들고 있지만 만약 데이터량이 아주 많고 특징이 지금처럼 2차원 즉, 두 개(귀 크기,털 두께)가 아니라 아주 많아진다고 하면 그 계산량은 어마어마해질 것입니다.
이러한 특징을 가진 유명한 머신러닝 모델, k-NN을 가지고 이번엔 캐글의 타이타닉 데이터를 응용한 실습 레퍼런스 결과와 함께 분석해보겠습니다.
캐글 데이터 타이타닉 적용
훈련용 데이터는 892개, 테스트 데이터는 417개였습니다. k-NN은 기계학습 분야에서 지도학습의 대표적인 알고리즘입니다. 아래 사진은 훈련용 데이터셋인 train.csv를 엑셀로 열어 캡쳐한 것인데요, 저 열 중에서 저희는 survived를 0 또는 1로 예측하는 모델을 만드는 것입니다. 정답 레이블이 주어진 것이죠.
타이타닉호에서 죽느냐 사느냐의 문제에 있어서 다른 필드들이 영향요소로 작용했다고 가정하고, 영향을 줬다면 얼마나 줬는가를 분석해서 EDA과정을 통해 k-nn 학습시킨 것이라고 볼 수 있겠습니다.

원 글에서는 데이터를 생으로 다루지 않고 기계가 보다 쉽게 인식할 수 있도록 numeric 카테고리화해 줄 뿐 아니라 실수형 데이터들의 경우 해당 필드가 survived 필드에게 (비교적) 더 영향을 줬는가 혹은 덜 영향을 줬는가에 따라서 그 분포를 적절하게 변형시켜주는 것도 확인할 수 있습니다. 다시 말해 기계가 학습을 하고 알맞은 판단을 내기에 보다 적절하도록 바꿔주는 과정을 보였습니다. 또한 한 눈에 데이터들의 상호 연관 관계나 패턴 따위를 알아보기 쉽게 하기 위해 시각화를 보이기도 했습니다.
이후에 스스로 원 핫인코딩을 적용해 성능을 조금 더 좋게 하도록 추가적인 실습도 해보았지만, 이 포스트에서는 k-NN 분석만을 주제로 다루도록 하겠습니다!
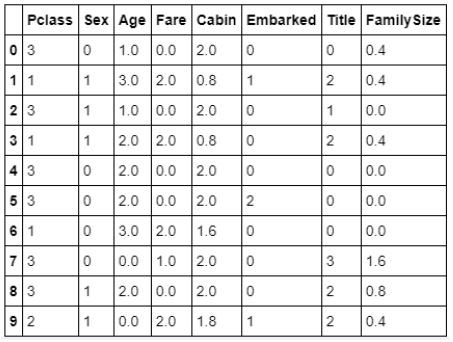
위 캡처는 EDA 과정 이후의 데이터 폼 일부분을 캡처한 것 입니다. k_NN 모델에 입력될 실질적인 값들이라고 할 수 있지요.
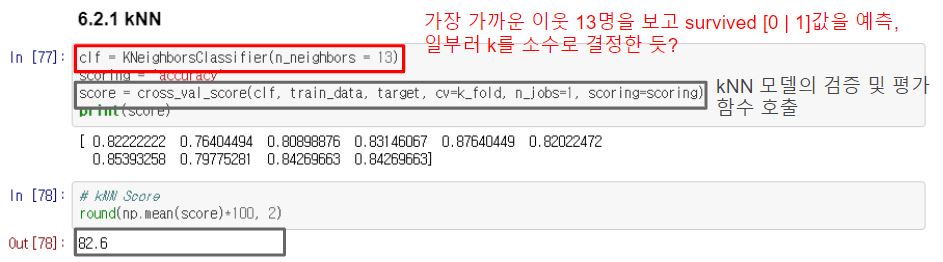
실습 레퍼런스의 원본 코드에서 발췌 캡처하였습니다. 13을 k값으로 갖는 k-NN 모델객체를 생성하여 해당 모델의 검증 및 평가함수까지 호출하였음을 확인할 수 있습니다. 성능평가 결과로 82.6의 score를 확인할 수 있습니다.
테스트 수행이 느린 모델이지만, 성능은 해당 레퍼런스 내에서 사용된 다른 모델과 비교하여 썩나쁘지 않은 것 같네요!
k-NN 특징공간에서 각 특징들은 각자 고유한 차원을 갖게되는데 이전 여우 분류 예제의 경우에는 2차원 특징공간을 구성하여 유클리드 좌표계 따위로 표현이 가능했지만, 실습 데이터의 경우 8차원 특징공간을 표현하기에 한계가 있어 표로만 표현해보았습니다.
| NO | pclass | sex | age | fare | cabin | embarked | title | familysize |
|---|---|---|---|---|---|---|---|---|
| 1 | 3 | 0 | 1.0 | 0.0 | 2.0 | 0 | 0 | 0.4 |
| 2 | 1 | 1 | 3.0 | 2.0 | 0.8 | 1 | 2 | 0.4 |
| … | bla | bla | bla | bla | bla | bla | bla | bla |
| 891 | bla | bla | bla | bla | bla | bla | bla | bla |
또한 위 문제에 대해서 k-NN 솔루션 수식에 대입하여 다시 한번 풀이하자면

이렇게 되겠습니다.
개인이 공부하고 포스팅하는 블로그입니다. 작성한 글 중 오류나 틀린 부분이 있을 경우 과감한 지적 환영합니다!