
Support Vector Machine_Machine Learning(10)
Intro
학교 수강과목에서 학습한 내용을 복습하는 용도의 포스트입니다.
그래서 이 글은 순천향대학교 빅데이터공학과 소속 정영섭 교수님의 “머신러닝” 과목 강의를 기반으로 포스팅합니다.
기존에 수강했던 인공지능과목을 통해서나 혼자 공부했던 내용이 있지만 거기에 머신러닝 수업을 들어서 보충하고 싶어서 수강하게 되었습니다.
gitlab과 putty를 이용하여 교내 서버 호스트에 접속하여 실습하는 내용도 함께 기록하려고 합니다.
이번 시간에는 SVM을 배웁니다.
머신러닝하는데 SVM 모르면 안됩니다.
SVM(Support Vector Machine)
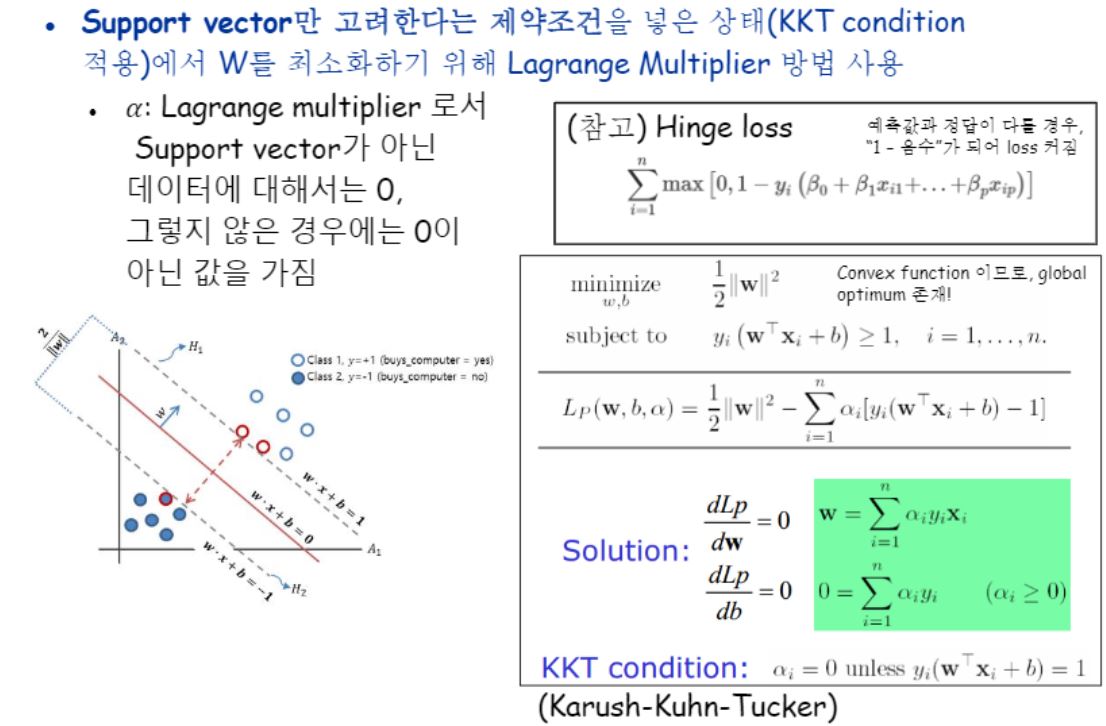
SVM의 motivation을 보겠습니다.
SVM은 Supervised learning 의 classification 문제 해결모델입니다.
그래서 데이터를 잘 나누는 Decision boundary를 찾아주는 것이 목적인데요,
SVM에서 찾고자 하는 decision boundary는
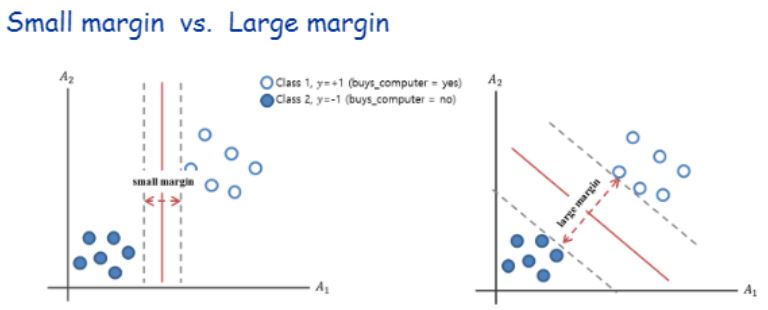
서로 다른 클래스 간의 거리가 최대가 되게 하는 것입니다.
그래서 Max-margin이라고도 부릅니다.
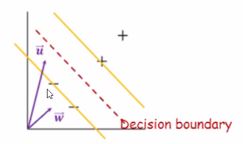
이 boundary는 두 개의 경계(노란선)의 중간선이 되며, ‘유일한’ 두개의 경계선을 만족하기 위해서는 데이터의 feature 개수와 상관없이 최소 2개의 데이터가 노란 선에 위치해야합니다.
이 예제에서는 세개가 존재하네요.
점 두개간의 거리를 구할 때 직선으로 잇는 거리를 구하는 것과 같은 방식입니다. 어렵지 않아요.
어쨌든 이 데이터(벡터)들을 Support Vector라고 부릅니다.
Decision boundary를 표현하는 수식은 아래와 같습니다.
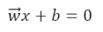
Decision boundary에 정확히 위치한 데이터를 위 수식에 대입했을 때만이 =0을 만족합니다.
위 수식을 이해하기 위한 선형대수학 기초지식을 아래에 실어드립니다.
SVM의 분류방법
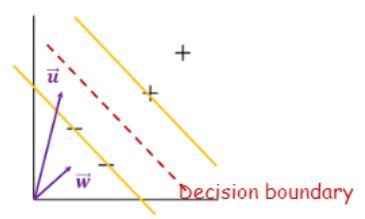
Decision boundary에 데이터를 적용한 ‘부호’로 판별합니다. 임의의 데이터 (벡터)u를 decision boundary 수식에 적용하면, 벡터w*벡터u+b <0이 되므로 ‘-’ 클래스로 분류가 됩니다.(이 때 *는 곱하기가 아닌 다트연산을 의미합니다.)
더 정확히 표현하자면 boundary 까지의 ‘거리’ 개념을 도입하여 설명합니다.
벡터u를 벡터w에 projection 하고 나서, 그 길이가 boundary까지 닿는가 안닿는가를 보는 것입니다.
좀더 formal 하게 정리하면, boundary와 노란색 선까지의 거리를 1이라고 가정하여 아래와 같이 수식을 세울 수 있겠습니다.
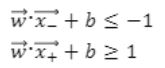
전자에 해당하면 -, 후자에 해당하면 + 클래스로 분류되겠지요.
잘 분류해낼 수 있는 SVM을 얻기 위해서는 데이터를 기반으로 학습과정을 거쳐 w와 b를 계산해야합니다.
SVM의 학습
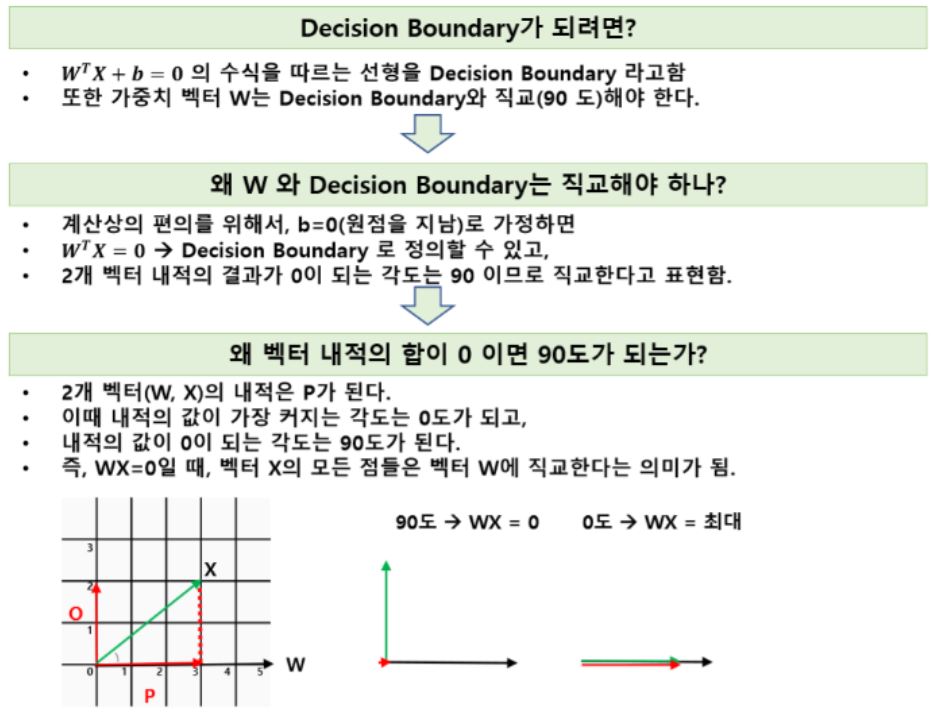
본격적으로 수식을 이해하기 이전에 앞서서 선형대수학의 기본 개념을 먼저 다지겠습니다.
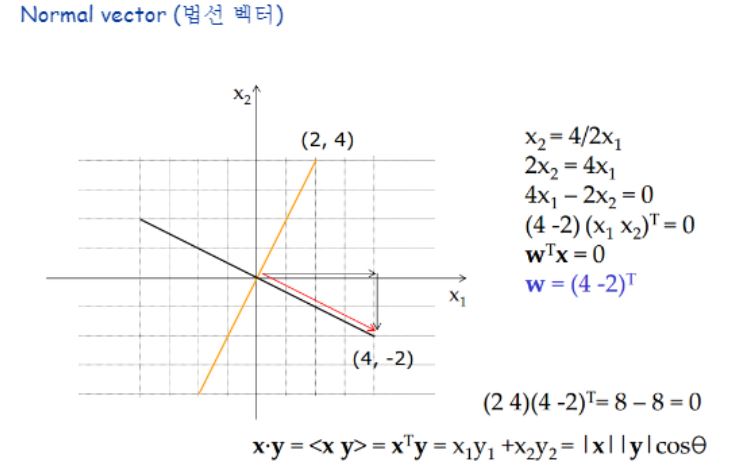
노란벡터에 대한 법선벡터 검정벡터를 구하는 과정을 보이고 있습니다.
내적 공식에 의하면 x의 norm * y의 norm * cos세타인데, cos세타는 사이각이 90일 때 0이고, 0도를 이룰때 1이 되지요. (이 때 *는 곱하기를 의미합니다)
법선벡터와 원벡터는 사이각이 90도 이므로 0을 갖게하는 법선벡터를 찾을 수 있게되는 것입니다.
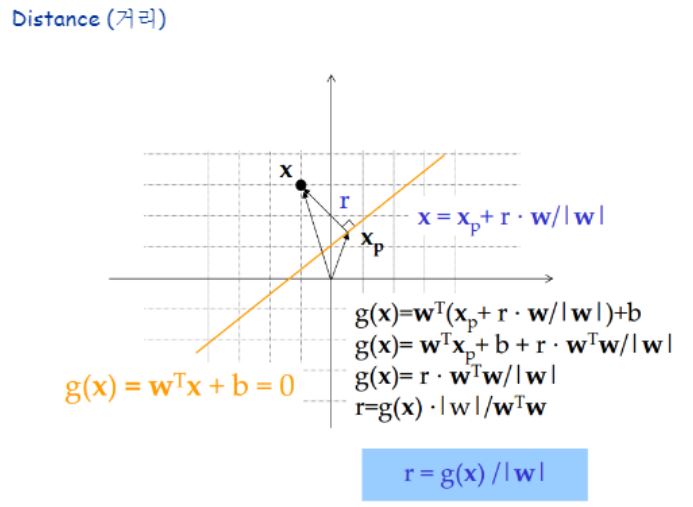
이번엔 거리를 구하기 위한 과정을 보이고 있습니다.
벡터의 삼각공식이라고 하던가요?
한 벡터a의 종점이 다른 벡터b의 시점이 되는 경우 두 벡터의 합 연산의 해는 a의 시점을 시점으로 갖고 b의 종점을 종점으로 갖는 벡터 c가 되었었죠?
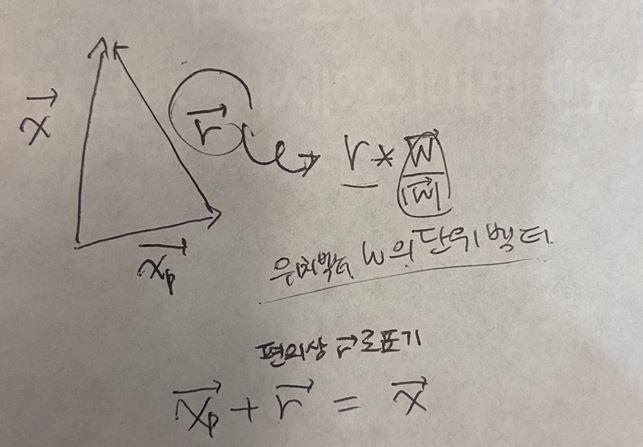
이러한 위치벡터 w로 부터 그의 법선벡터인 g(x)를 구하는 것입니다.
Decision boundary에 정확히 위치한 데이터를 위 수식에 대입했을 때만이 =0을 만족하기 때문에
g(x)=r*w^t*w/|w|
가 되며 이 식을 r에 대해 정리하면
r=g(x)*|w|
로 정리되는 것입니다.
이를 통해 두 데이터(벡터) x와 xp사이의 거리를 구할 수 있습니다.
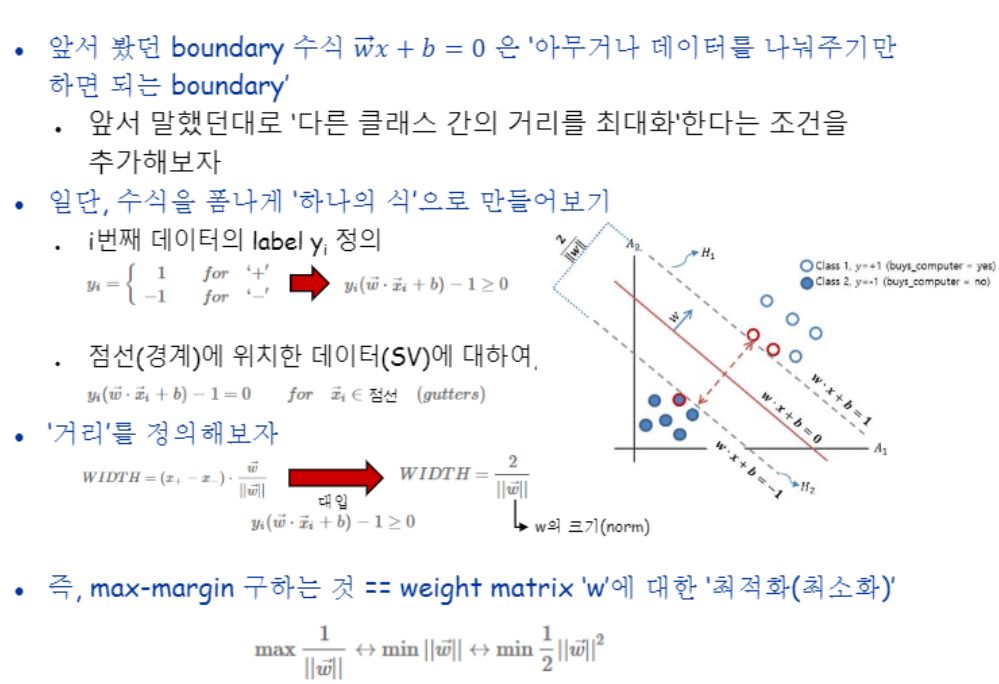
거리를 정의하는 곳을 보면 w 벡터에 사영시켜서 w축만을 기준으로 좌표값을 구해 차이를 구하고 있네요.
그리고 w 벡터의 크기로 나눕니다.
그림에서 보면 각 support vector로부터 decision boundary까지의 거리는 1이었으니 직선거리 2가 나왔을 것이구요.
max margin을 구하기 위해서는 직선거리(위 예제에서는 2)를 벡터w의 크기로 나눴을 때가 최대가 되려면 w의 norm은 최소값을 가져야한다는 말을 하고 있습니다.
최적화를 시키는 계산을 위해서 convex형태로 만들기 위해 제곱해주고 미분시 편의를 고려해 1/2를 곱해주었네요.
아직 완전히 이해하지 못해서 더 공부하고 이 포스팅을 갱신해두려고합니다.
SVM에서는 Support Vector과 Decision Boundary까지의 거리를 1이라고 가정하고 문제를 살펴보았는데, 어떤 데이터였든 그렇게 거리는 1이라고 가정을 하고 풀게되는지?
그렇다면 support vector가 어디에 있을지 모르는데 어떻게 1로 가정할 수 있는걸까요?
도대체 support vector가 어떻게 결정되게 되는 걸까요?
제 생각을 차례로 정리해보았습니다.
강의자료에 의하면 구분선이 될 수 있는 후보는 무수히 많이 존재하지만 max-marginal 선을 찾기 위해 support vector를 두 개 이상 선정할 필요가 있다고 했습니다.
따라서
support vector를 누구로 할 지 결정해야 decision boundary를 찾을 수 있다
가 제 머릿속에서의 순서인데,
“support vector라는 애들은 decision boundary로 부터 양옆으로 1만큼 떨어진 애들일거야” 라는 hypothesis에서 출발하면 순서가 맞을까요?
직관적으로는 데이터(vector) 하나하나마다 support vector라고 가정하며 그때마다의 margin이 얼마나 되는지를 구해야하는 건데, margin이 최대가 되도록 하는 w와 b를 찾되, 모든 데이터(vector)에 대해 다 보는 것이 아니라 대적(?)하고 있는 support vector인 애들에 대해서만 max margin인 선을 구할 것이다!
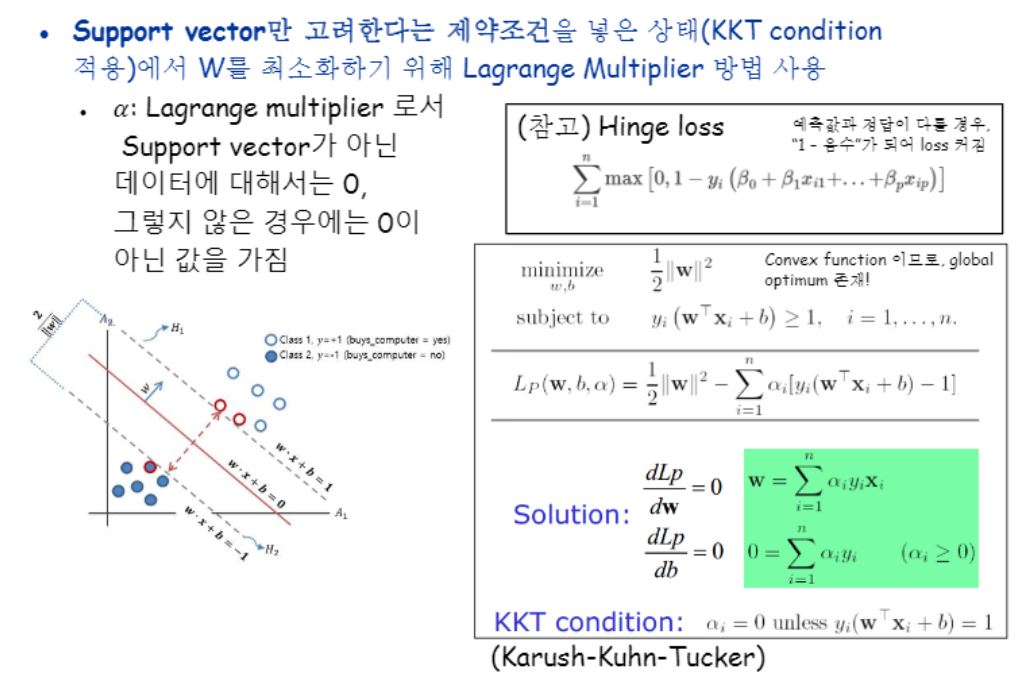
라는 것이 바로 라그랑지(등식에만 적용 가능)이고, 여기서 등식에만 적용 가능하다는 말은 only Support Vector일 때만을 고려해주는 것을 말하는 것입니다.
그런데 우리가 풀어야 할 문제는 딱 그 support vector들만 고려할 것이 아니라 분류기 구현이므로 그 위쪽과 아래쪽까지 고려해주려고 부등식에서도 사용할 수 있도록 변형된 KKT컨디션 하에서 최적화하겠다는 말을 하고 있습니다.
이렇게 최적화 시키게 되면 그야말로 우리가 원하던 결과일 것이라고요.
(근데 데이터가 많아지면 속도가 매우 느려질 것이다라는 설명을 읽다 보면 입력 데이터들의 선형합으로부터 구하니까.. 모든 데이터들에 대해 max margin을 살펴보는 과정이 식에 녹아있는 것 같기도하고..)
어쨌든 여기서부터 제 궁금즘이 시작되었었습니다.
KKT 컨디션은 αi = 0 unless Yi(W^Txi + b) = 1 인데, 이것도 결국은 support vector에서부터 Decision boundary 까지의 거리가 1씩이라고 가정을 했기 때문에 가능한 식 아닐까요??
그렇다고 하면.. 제 생각은 다시 원점으로 돌아가게 되었습니다.ㅎ ㅎ
SVM에서는 Support Vector과 Decision Boundary까지의 거리를 1이라고 가정하고 문제를 살펴보았는데, 어떤 데이터였든 그렇게 거리는 1이라고 가정을 하고 풀게되는지?
그렇다면 support vector가 어디에 있을지 모르는데 어떻게 1로 가정할 수 있는걸까요?
도대체 support vector가 어떻게 결정되게 되는 걸까요?
지금 우리는 데이터 두개 클래스를 분류를 하는 예제를 보고 있습니다.
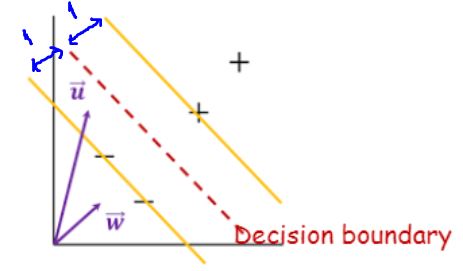
분류는 supervised learning이라고 배웠구요.
이 분류기에서 분류할 대상으로 +클래스와 –클래스가 있다고 가정합니다.
+는 +1, -는 -1로 표기하기로 합니다.
우리가 구하고자하는 이상적인 decision boundary를 빨간선이라 했을때 이 선이 유일하려면 support vector가 양쪽 두개가 있어야 가능해집니다.
두 점을 잇는 직선이 유일하다는 이론을 생각하시면 간단해집니다.
그렇게 이해하게 되면 decision boundary를 찾는 문제는 두 벡터를 있는 선에 대해 직교하는 선을 구하는 문제가 되는 것이죠!
노란선과 빨간선까지의 거리를 1이라고 가정하고 문제를 살펴봅니다.
+인 애들을 테스트데이터로 넣어보면 +1만큼의 거리보다 클 것이라는 것, -인 애들을 테스트데이터로 넣어보면-1만큼의 거리보다 작을 것이라는 가정이있는거에요.
이걸 만족해야한다라고 조건을 거는거에요.
이걸 하나의 수식으로 바꾸는 과정이 바로 아래 그림에 나와있습니다.

SVM의 학습_Lagrange Multiplier
위에서 조건을 건다라고 설명했습니다, 이는 라그랑지 멀티플라이어라는 기법을 말하는 것인데요, 라그랑지 멀티플라이어에 대해 잘 이해해보자!는 취지로 몇장 추가해주셨어요.

위 캡처에서 처럼 최적값을 구할 때 어떤 조건을 걸 수 있습니다.
특정 조건을 만족하면서 최적값을 구하도록 수식을 합칠 수 있다는 거에요.
그들을 만족하는 극값을 구하면 라그랑지의 조건도 함께 만족하는 것이 되지요.
그런데 우리가 방금 푼 문제들은 다 등식들이에요.
근데 우리가 분류기를 구현할 때 풀어야할 문제들을 보면 부등식이에요.
그래서 등식에만 써먹을 수 있는 라그랑지를 바로 쓸수가 없어서 KKT 컨디션을 적용해서 우리의 문제들을 풀게 됩니다.
일단 거기까지 가기 전에 이 부분을 먼저봅시다.

X^2+2y의 최적을 구해보자! 인데, 조건을 추가했네요.
이 문제는 우리가 고등학교 때 보던 아래와 같은 함수의 최대를 찾는 문제와 다릅니다.
x라는 변수 하나짜리 1차원 문제가 아니라 두 개의 변수에 대해 문제를 풀어야한다는 점을 기억해주세요.
우리가 지금 풀 문제는 min{f(x,y)} = x^2+2y입니다.
직관적으로 그래프를 보며 이해하기 위해 아래 링크를 이용해 그래프를 그려보았습니다.
https://www.geogebra.org/3d
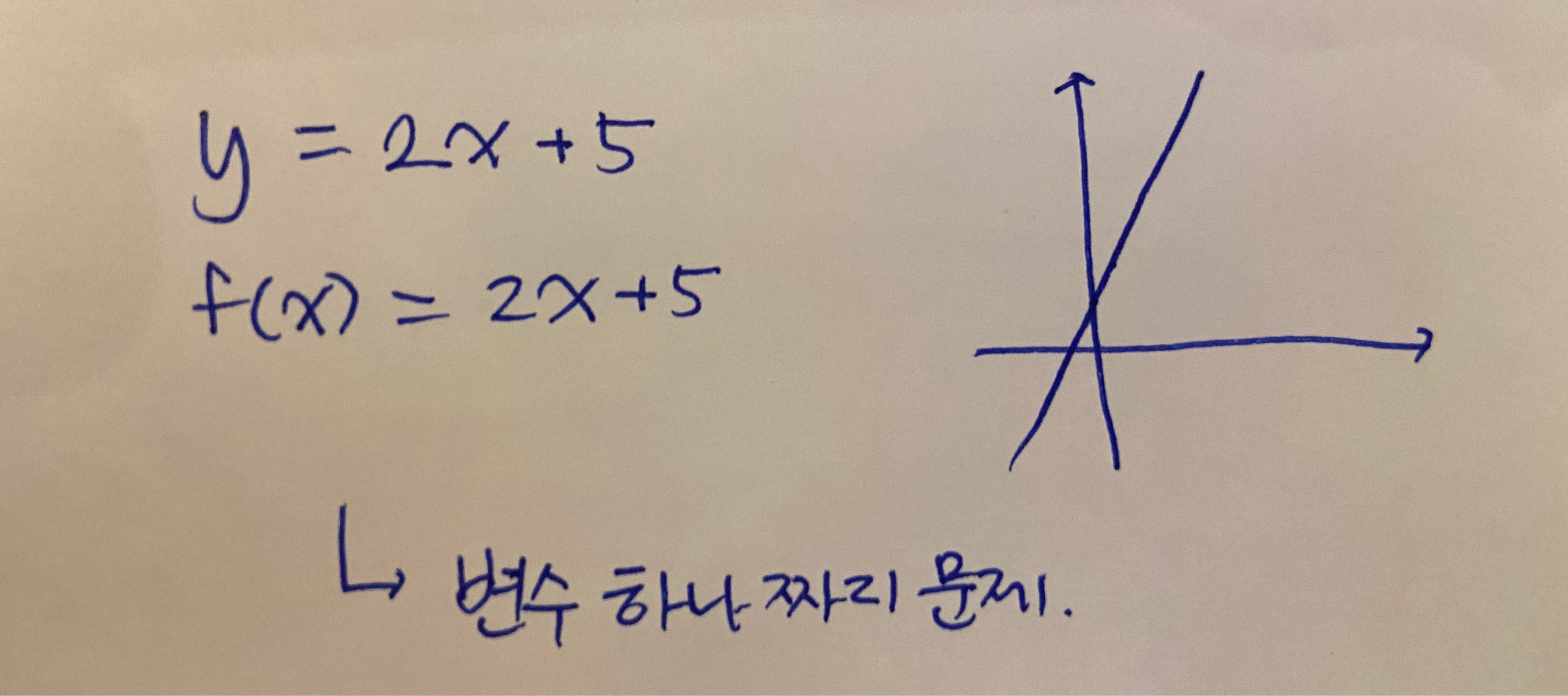
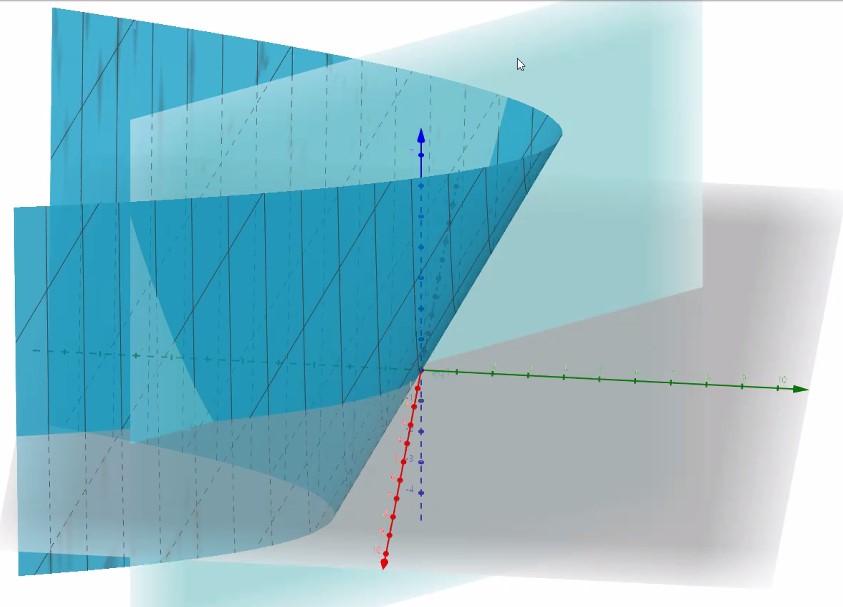
초록색이 x축 빨간색이 y축 파란색이 z축으로, 여기까지는 x^2+2y를 그린 것입니다.
여기서
3x+2y+1 조건을 단다는 것은 바로 저 면을 만족하면서 최소인거를 찾는 것입니다.
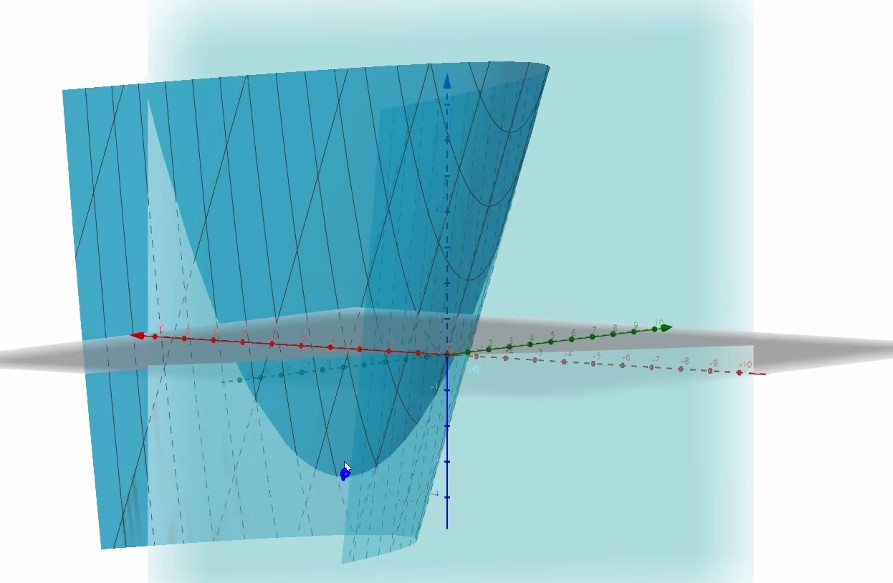
저 파란점을 구해야한다는 거죠!!
라그랑지 식으로 두 식을 합쳐서 표현하면 아래와 같은 수식이 나오게 됩니다.
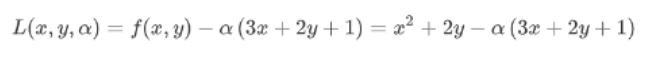
그리고 이 수식을 3d로 그려보면
저 보라색? 쭉 이어붙인게 라그랑지 수식이의 그래프입니다.
수식으로 풀어내면 아래와 같습니다.
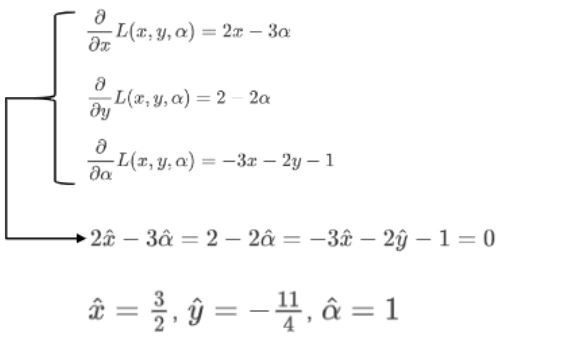
SVM의 학습_KKT condition
자, 어쨌든 우리는 지금 저 문제처럼 접선에 존재하는애들만(sv)을 고려할 것이 아니라 그 바깥 쪽에 있는 애들도 다 고려해줘야해요.
왜냐면 분류기 구현이니까요.
sv보다 다른애들은 다 뒤에 있어야 하거든요.
그래서 우선 간격을 1로 정해주는 거에요.
즉 식에서 등호는 Support Vector들을 위해 붙여놓는 거지요.
Support Vector 더 뒤에있는애들을 고려하기위해 부등호를 붙인 것이구요.
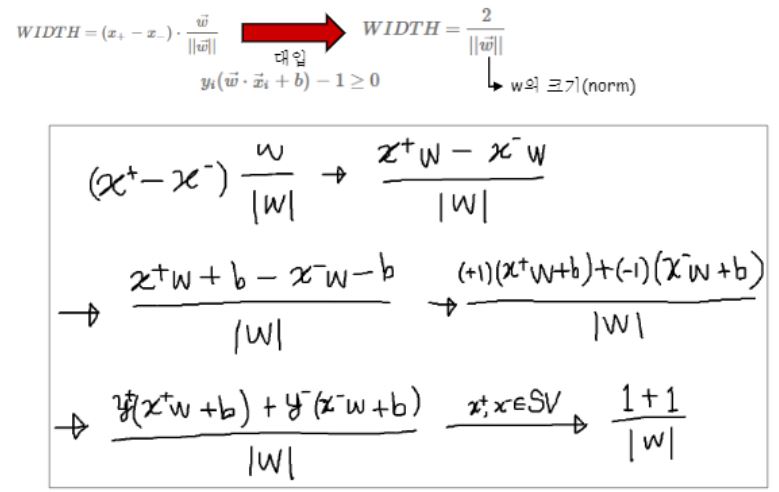
거리를 수식으로 표시를 할 수 있어야 분류를 하겠지요?
(x^+ - x^-)곱하기 W의 unit벡터는 에 사영을 시킨거니까 그만큼의 거리가 아니겠어요?
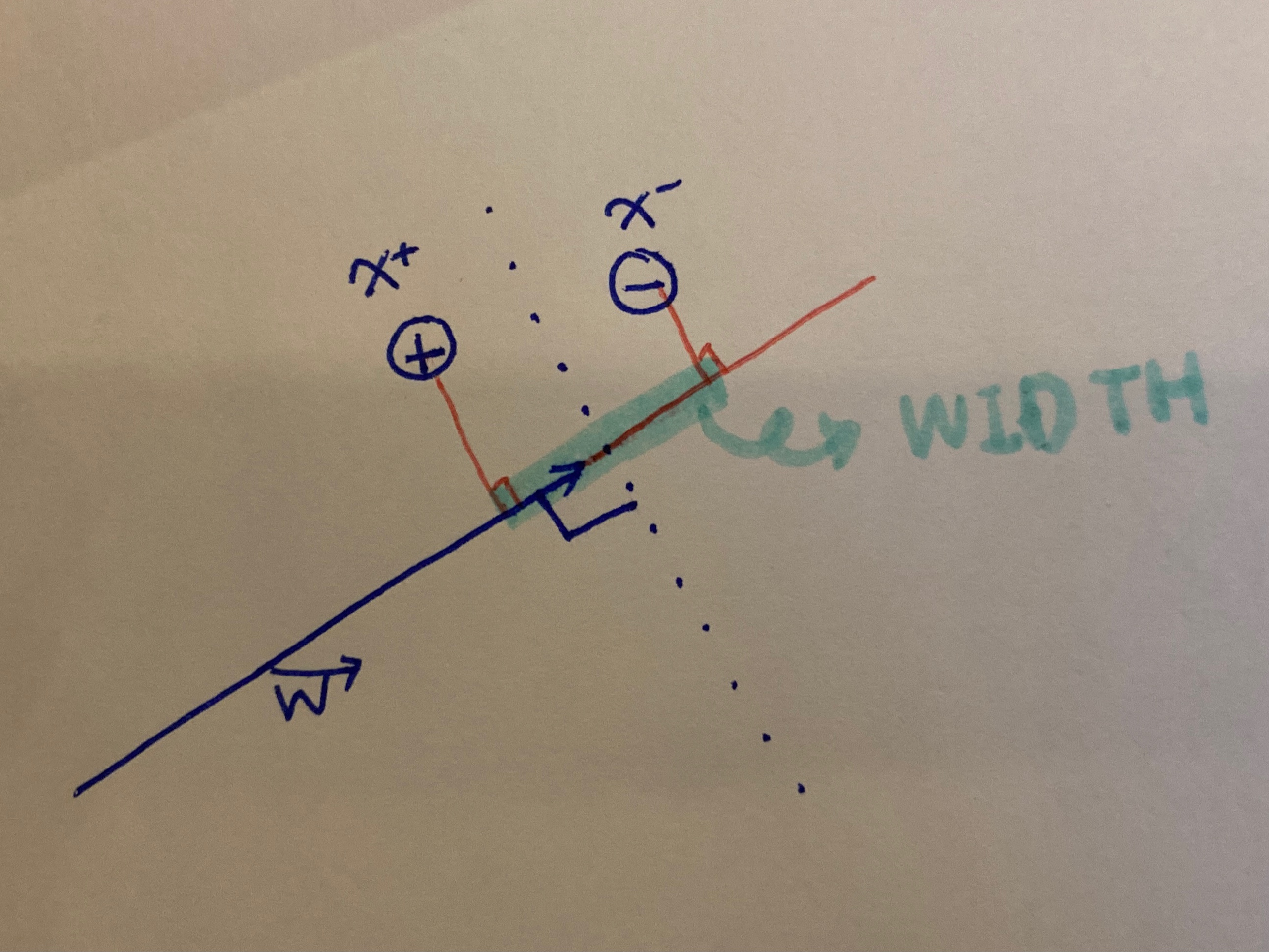
그래서 그 거리가 2/단위벡터라고 나온거에요 양쪽 1씩있었으니까요.
가운데 있는 점선이 바로 decision boundary가 되겠지요.
분모가 작아야 전체 값은 커지겠지요? 즉, w의 크기를 최소화하는 문제를 푸는 것이 되었습니다.
그리고 수식상의 편의를 위하여 convex형태로 만들면서 1/2이라는 상수를 곱해준 것 뿐입니다.

이렇게 식을 만들고 끝이 아닙니다.
support vector만을 고려하도록 조건을 걸어줘야겠죠?
n개의 데이터가 있을 때 모든 데이터가 yi(WtWi+b) >= 1의 조건을 만족해야한다고요.
부등식에 대해서도 라그랑지를 적용할 수 있도록 kkt 조건을 정의해놨어요.

알파가 0이 아닌 모든 경우에는 뒤에 항 y(w^tx+b)이 1이어야 해요.
그 말은 다시 말하자면 SupportVector만을 고려한다는 것이 됩니다.
KKT에서는 알파에 대해서는 0보다 크거나 같아야 하며 미분하지 않도록 정의하였습니다.
그럼 알파값이 0인 경우와 0이 아닌 정수 중 양수인 경우 둘로 나뉘겠죠?
알파값이 0인 경우는 바로 우리가 걸어놓은 조건 라그랑지 수식부분이 0이 아니면 알파가 0이 되어야 등식을 만족하며,
알파값이 0이 아닌경우는 우리라 걸어놓은 조건쪽이 0이 되어야만 등식을 만족합니다.
이게 어떤 의미를 갖느냐하면
알파가 0이 아니다 => 라그랑지수식이 0 => yi(wtxi+b)는 1 => xi는 서포트 벡터
입니다.
나머지 경우엔 알파가 0이어야 하구요.
결국은 알파값에 의해서 서포트 벡터인 경우에만 고려하게되는 것이죠.
SVM의 학습_Hinge Loss
SVM에서 사용하는 loss는 hinge loss입니다.
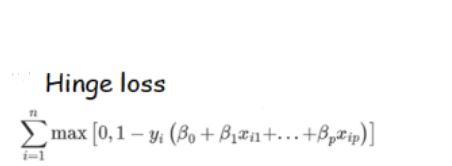
hingeloss 수식을 보면 1-음수가 되서 loss가 커집니다.
그 이외에 잘 맞는경우에는 그냥 0으로 취급하는거에요.
SVM 이론 중 어디에서 쓰인 것일까요?
그리고 SVM의 loss부분은 어디일까요?
방금 배운 이 부분이 바로 Hinge Loss가 쓰인 부분입니다.
원래 순서대로 생각하면 우리가 건 조건쪽이 0이 아니었기 때문에 알파가 0이되는 거잖아요?
알파*0=0이 되거나 알파*yi(W^txi+b)-1=0 이 되거나 니까요.
SVM의 학습_최적화
어쨌든 이렇게 조건을 고려하도록 식을 합치면 Lp가 나옵니다.
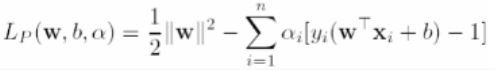
여느 때처럼 우리가 구하고자 하는 파라메터 w,b 값을 최적화시키기 위해 식 Lp를 w,b 차례로 편미분해줍니다.

최적화 식 전개부분을 봅시다.
원래의 수식은 w,b,a가 있었는데 쭉 전개를 해나가다보면 w,b가 사라져버렸습니다.

자세한 전개과정은 아래 캡처에 있습니다.

X와 y는 데이터로부터 얻을수 있는 애들이고 결과적으로는 a만 남는거에요.
그래서 a에 대한 함수로 남는것이죠.
maxmargin이라는 조건을 만족하면서도 sv만 고려하도록 조건달아서 다 전개했더니 a만 남았어요.
결국 위로 볼록한 쿼드라틱 함수가된거에요. 그래서 최대점을 구하는 문제가 되지요.
svm을 이용해 구해야할 대상으로 파고파고 왔더니 위로 봉긋한 형태라는거에요.
최적값이 존재합니다.
우연의 일치일까요 과연?
직관적으로 생각해봅시다.
서포트 벡터가 두 개 이상일 때 이들을 잇는 최대가 되게하는 선은 결국 유일합니다.
원래부터 유일했던 문제에요. 하지만 수식으로 풀어내려고 애쓰다보니 정말로 위로 볼록하게 나오는걸 확인할 수 있던것이지요.
이후 이 문제는 쿼드라틱 프로그래밍이라는 알고리즘으로 풀 수 있습니다.

최적알파를 구하면 그로부터 w를 구하고 b도 구해낼수 있습니다.
데이터 개수 n에 의존적이며 수식을 보면 nxn이라 데이터가 많아지면 굉장히 오래걸립니다.
어떻게 Support Vector를 구할 수 있었는가?
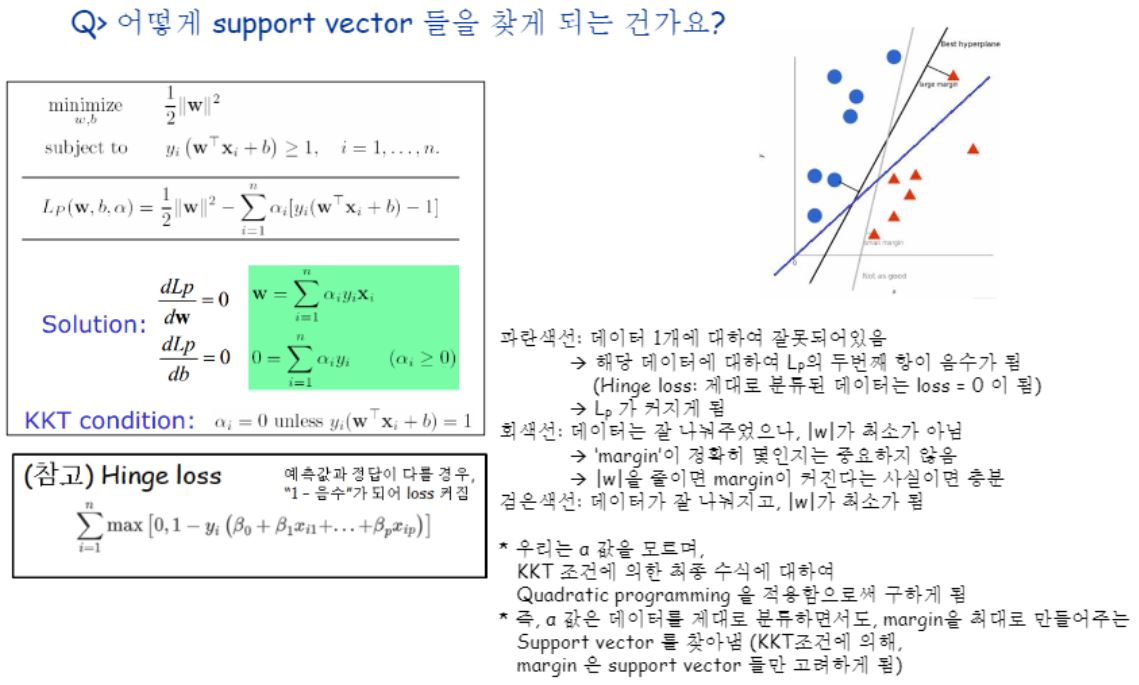
최적화 수식이라는 것은 어떤 모델(=가설, hypothesis)을 나타내는 수식과는 별개의 문제입니다.
그저 어떤 방식으로 학습을 했으면 좋겠을 지에 대해 수학적으로 formlula 정의하는 것을 말합니다.
근데 SVM에서는 이 최적화 수식으로 알파에 대한 수식을 사용한 것 뿐입니다.
Lp(w,b,알파) 이 식이요..
알파를 구하면 w를 최소화하면서 SV만을 고려하는 것을 만족하는 것이지요. 이 알파라는 애를 구하고 나면 w와 b 역시 구할 수 있는 것이구요.
뭐가 어떻게 된건지는 잘 모르겠지만, -1/2atQa+at1 이 자연스레 나왔고, 나오고보니 그 모양이 쿼드라틱이고 그래서 알파값이 실제 뭔지는 모르더라도 최고점을 구할수 있어졌고, 누가 서포트 벡터가 누굴진모르더라도 1로 가정했기 때문에 1보다 커지게 되면 그쪽으로 분류되는 것 뿐이랍니다.
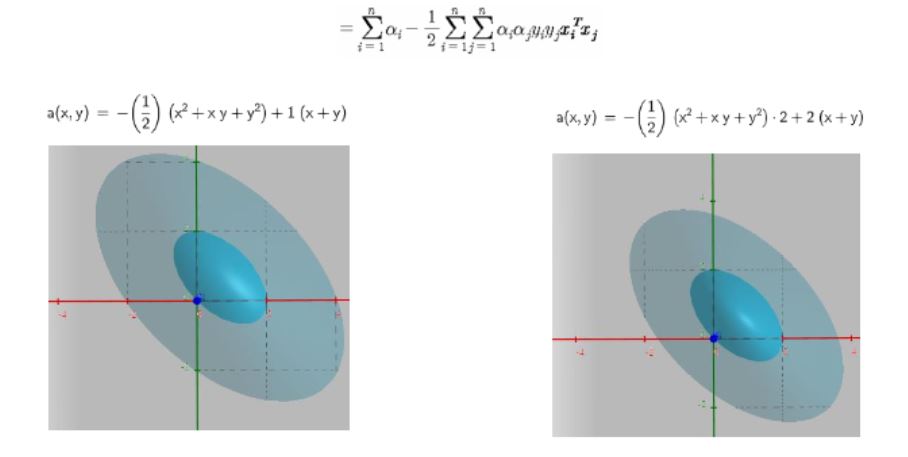
그럼 1이아니라 어떤 다른 상수였다해도 같은 결과가 나올까요?
네! 말그대로 상수였으니까 그래서 최적화시킬때 즉 그라디언트 구할때 크게 상관없어지는구나하고 이해하였습니다.
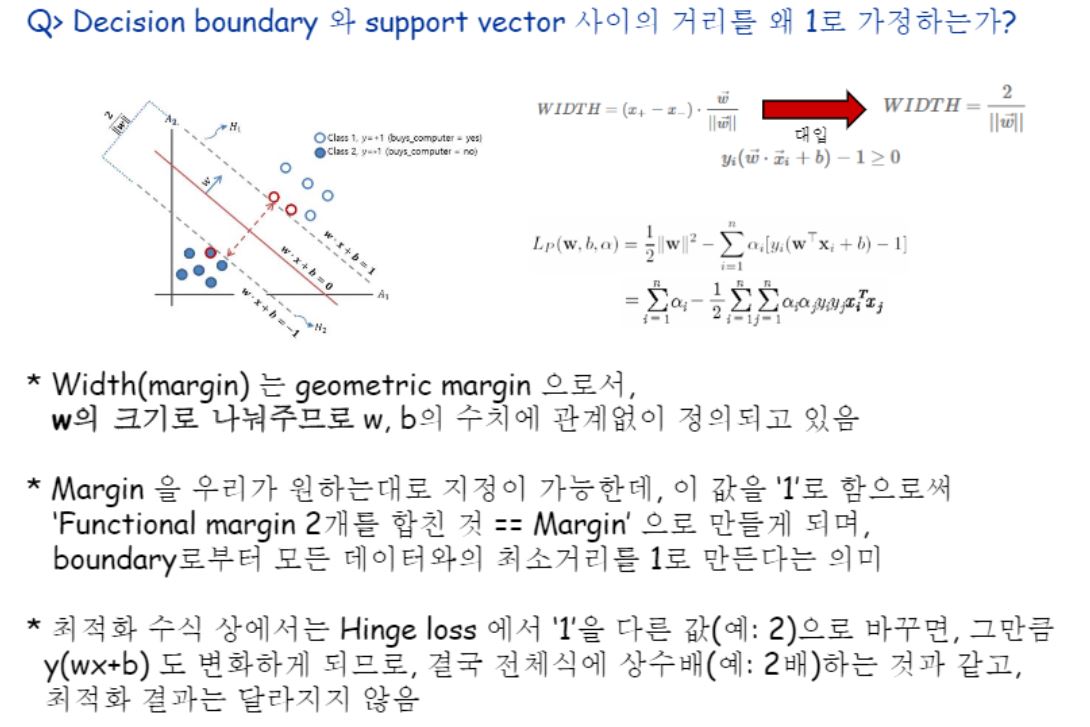
Margin에 대해 왜 하필 1로 가정하는가?
Lp 수식을 정리할 때 왼쪽 항은 마진을 크게하자! 를 위해 만든거고 두번째 항은 양 옆으로 클래스에 대해 나눠질수 있도록 하는 항이었어요. 그래서 오른쪽에 해당하는 term이 hinge loss에 해당하는 항이었구요!
Lp는 이렇게 두개의 항으로 이루어져있는거에요.
이 때 Width를 1로 가정한다는것은 무엇을 근거로 1이라고 할 수 있는걸까? 그래도 되는 걸까?가 미치도록 궁금했어요.
어느 선에의해 나눠질지는 사실 모르는거죠? 그래서 일단은 임의로 가정하고 시작하는거에요.
1이라고 가정하고 풀게 되지요.
이 이론은 어떤 만만한 임의의 상수 1을 하면 그 길이가 실제 무엇이었던지 간에 상관없이 최적으로 구해진다는 것을 보여줍니다.
Width(=margin)은 geometric margin으로서..(w가 크기거든요?) 그걸로 나눠준다는건 결국 기하학적인 측면으로 볼 때의 margin이다! 라고 할 수 있는거죠.
그래서 걍 우리가 원하는대로 설정해놓고 할 수 있어요.
이걸 1로 설정한다는 것은 양옆으로 Support Vector까지의 거리를 각각 1로 가정한다는 것이므로 이 말을 수식으로 표현하면 yi(wxi+b)-1 = 0가 되는거에요.
구체적으로 힌지로스에 해당하는 1이라는 수치가 결국 1이라고 거리를 가정했기 때문이잖아요?
거리를 1로 뒀기 때문에 저 수식이 만들어지는 것처럼, 2로 둘 수도 있어요.
이를테면, 2x+3y=1이라고하면 4x+6y=2와 동치잖아요. 걍 내가 정한 상수만큼으로거기에 맞춰서 되는거에요. 상수배되는 건 똑같은거죠.
그래서 최적화결과는 같아진다 라고 말할 수 있습니다.
알파값이 데이터(벡터)마다 존재하는 것이기 때문에 우리는 계수를 1이다 또는 2다라고 가정하는데, 최대값에 해당하는 알파의 위치는 똑같다는 거지요.
바로 이런 식으로요!
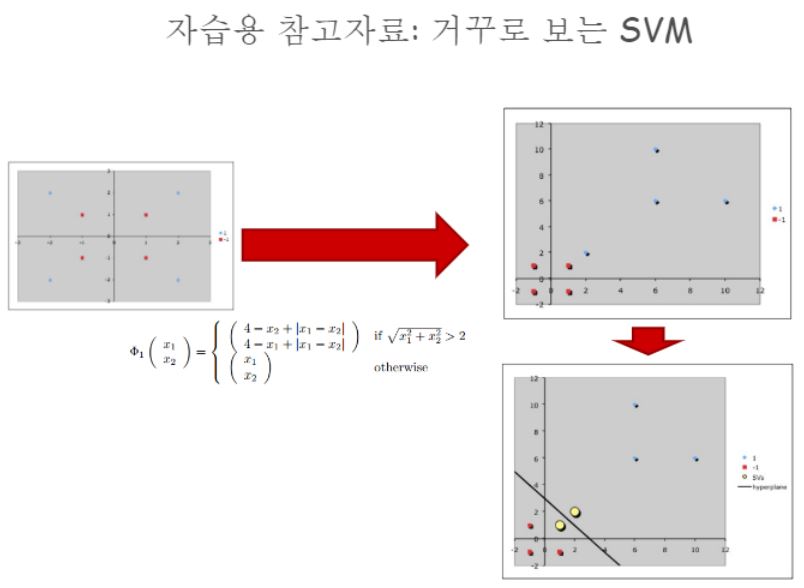
비선형패턴을 위한 SVM
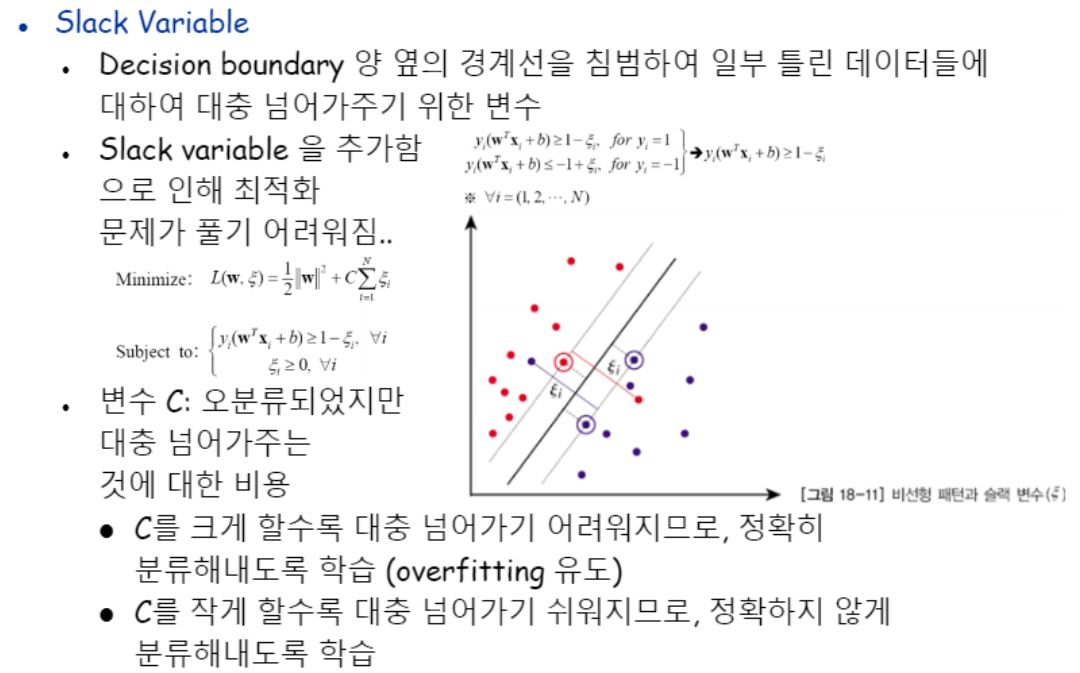
모델이 찾은 decision boundary가 완벽히 데이터들을 나눌 수 있다면 참 좋겠지만 그렇지 못하고 잘 찾지 못할 수도 있어요.
넘어간 애들을 적절히 버릴 줄 아는 것을 Slack variable이라고 합니다.
다시 말하자면, Slack Variable은 Decision boundary 양 옆 경계선을 침범해서 일부 틀린데이터들에 대해 대충 넘어가주기위한 변수입니다.
강의자료에서는 입실론 기호로 표현하고있습니다.
저 variance를 줌으로써 최적화 문제 풀기가 그만큼 어려워집니다.
얼마나 민감하게 반응할지에 대해 C로 결정해줍니다.
일종의 하이퍼파라미터에요.
C를 크게할수록 대충 넘어가기 어려워지므로 정확히 분류해내도록 학습하므로 오버피팅이 유도됩니다.
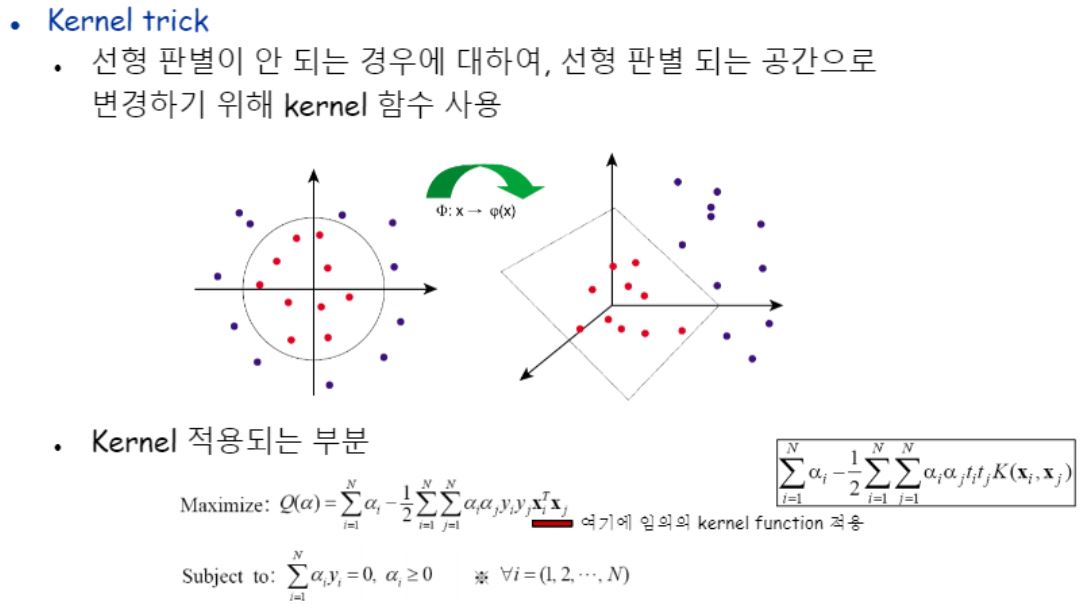
근데 이걸로 비선형패턴을 잡아내는 것이 잘 해결안되는 경우도 있어요.
그럴 때 Kernel trick이라는 기법을 사용합니다.
선형판별이 안되는 경우에 대해 선형판별되는 공간으로 공간을 바꿉니다.
다른 차원으로의 사상이라고 표현합니다.
커널도 역시 하이퍼파라미터입니다.

RBF(Radial Basis Function)가 가장 많이 사용됩니다.
저희가 배운 SVM(Regular SVM)은 이진분류, 회귀, (반드시 1개의 label만 갖는)Multi-class 분류 용도로 사용되고 Structured SVM은 Multi-label 분류와 다중뷴류에 사용된다고 합니다.


개인이 공부하고 포스팅하는 블로그입니다. 작성한 글 중 오류나 틀린 부분이 있을 경우 과감한 지적 환영합니다!