
Decision Tree LAB_Machine Learning(5)
Intro
학교 수강과목에서 학습한 내용을 복습하는 용도의 포스트입니다.
기존에 수강했던 인공지능과목을 통해서나 혼자 공부했던 내용이 있지만 거기에 머신러닝 수업을 들어서 보충하고 싶어서 수강하게 되었습니다.
gitlab과 putty를 이용하여 교내 서버 호스트에 접속하여 실습하는 내용도 함께 기록하려고 합니다.
Decision Tree LAB1
실습을 하기 위해 데이터를 다운받아주세요.
데이터 디스크립션 읽어보고 data folder에 들어가서 diagnosis.data를 다운받아주세요!
- 데이터를 로컬의 data/에 담고 git add/commit/push 실습
데이터를 먼저 다운로드 받습니다.
저는 아래 캡처화면과 같이 리눅스의 wget 명령어를 통해 url로부터 호스팅되어있는 diagnosis 데이터를 다운로드 받았습니다.
wget https://archive.ics.uci.edu/ml/machine-learning-databases/acute/diagnosis.data
url 알아내는 것은 어렵지 않습니다. 브라우저에서 데이터 다운로드 링크가 있을텐데 우클릭해서 링크복사 누르면 됩니다.
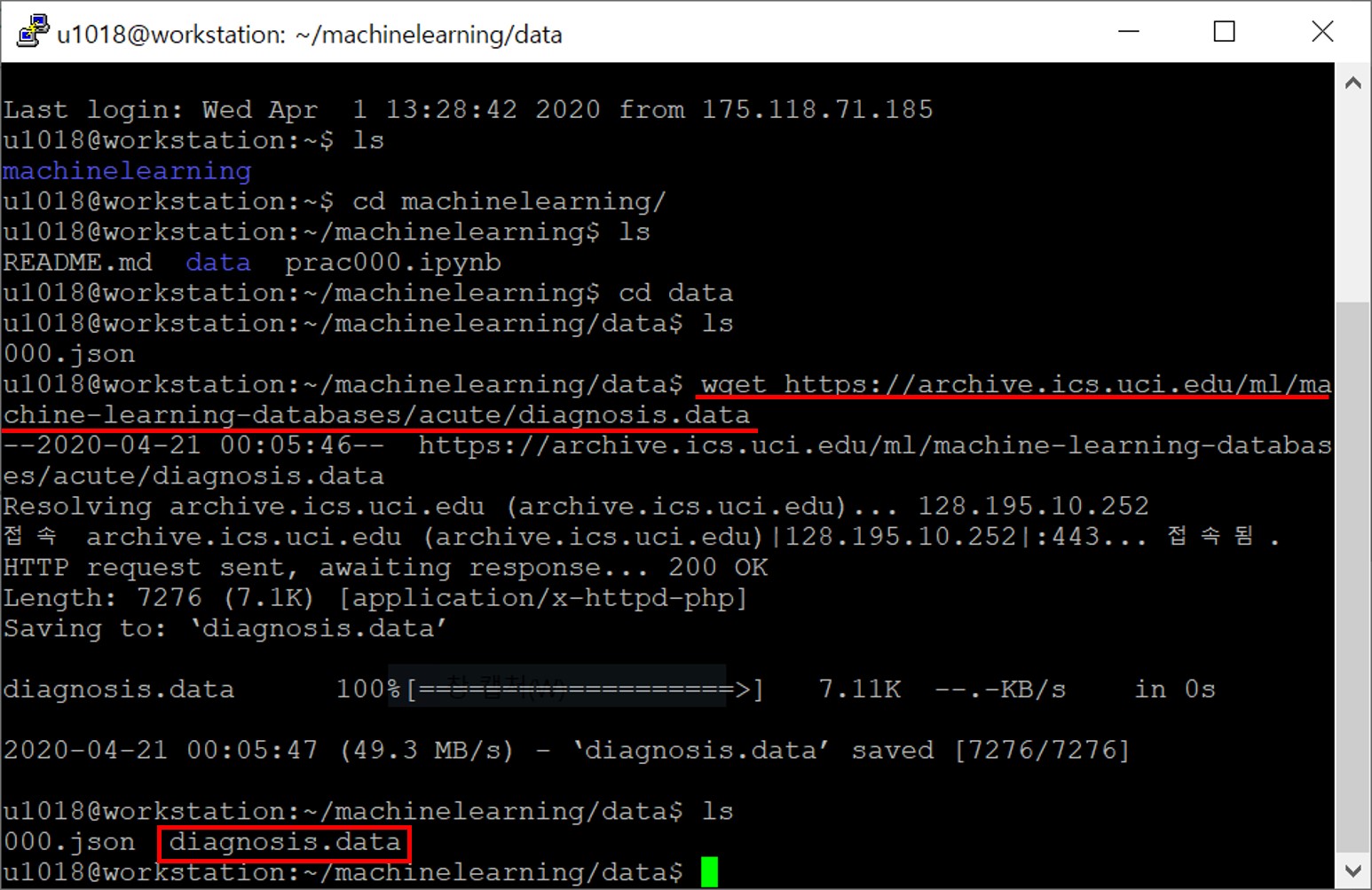
ls 명령어를 통해 데이터셋이 잘 다운로드 되었음을 확인하였습니다.
이후에는 git과 친해지기 위한 실습으로, 수정사항을 커밋하고 내역을 깃랩 원격 레포지토리로 푸시해보는 것입니다.
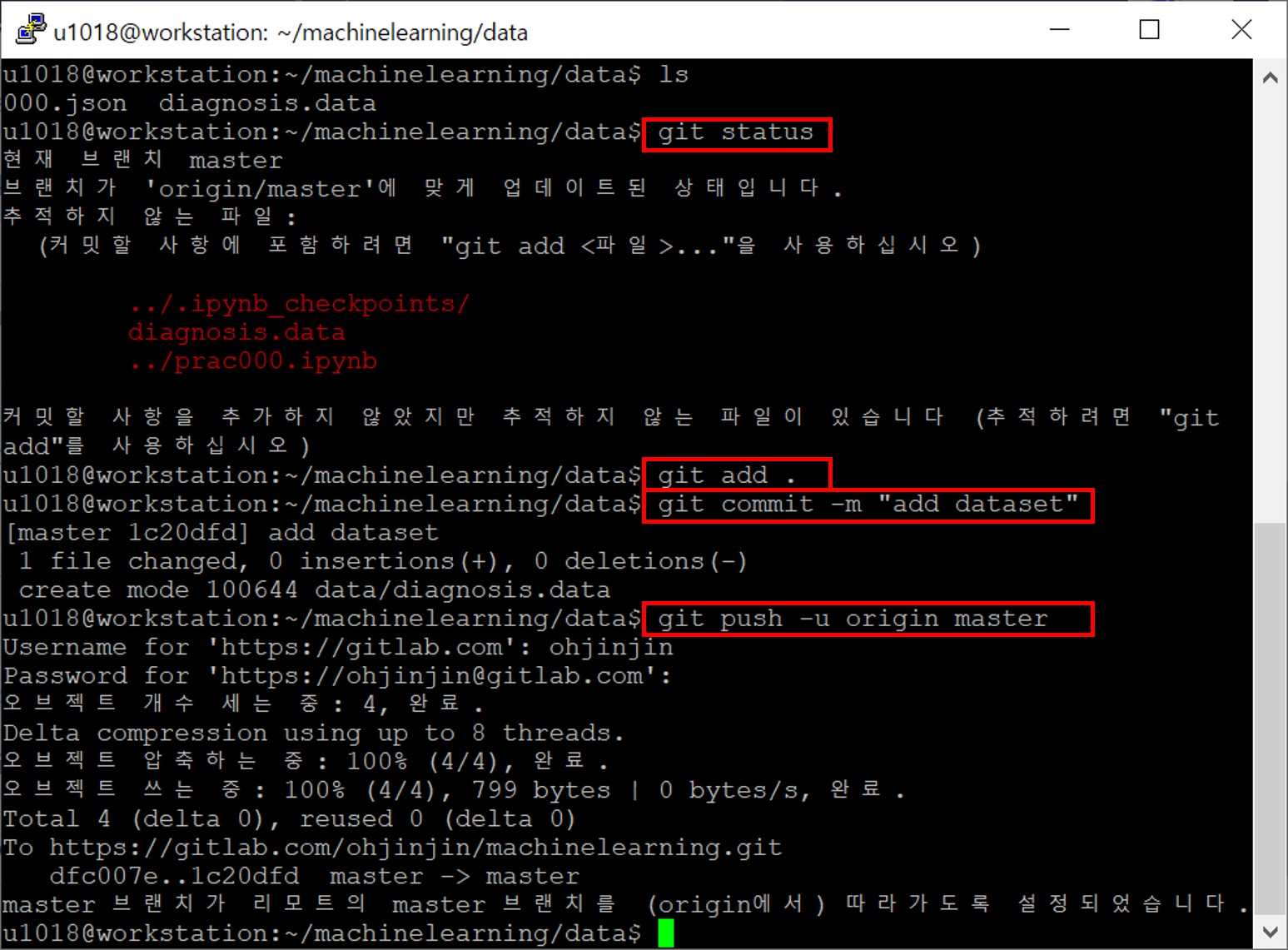
잘 되었네요!
제 깃랩 레포지토리 링크를 여기에 걸어두겠습니다.
- jupyter notebook 켜서 python DT 예제코드 작성
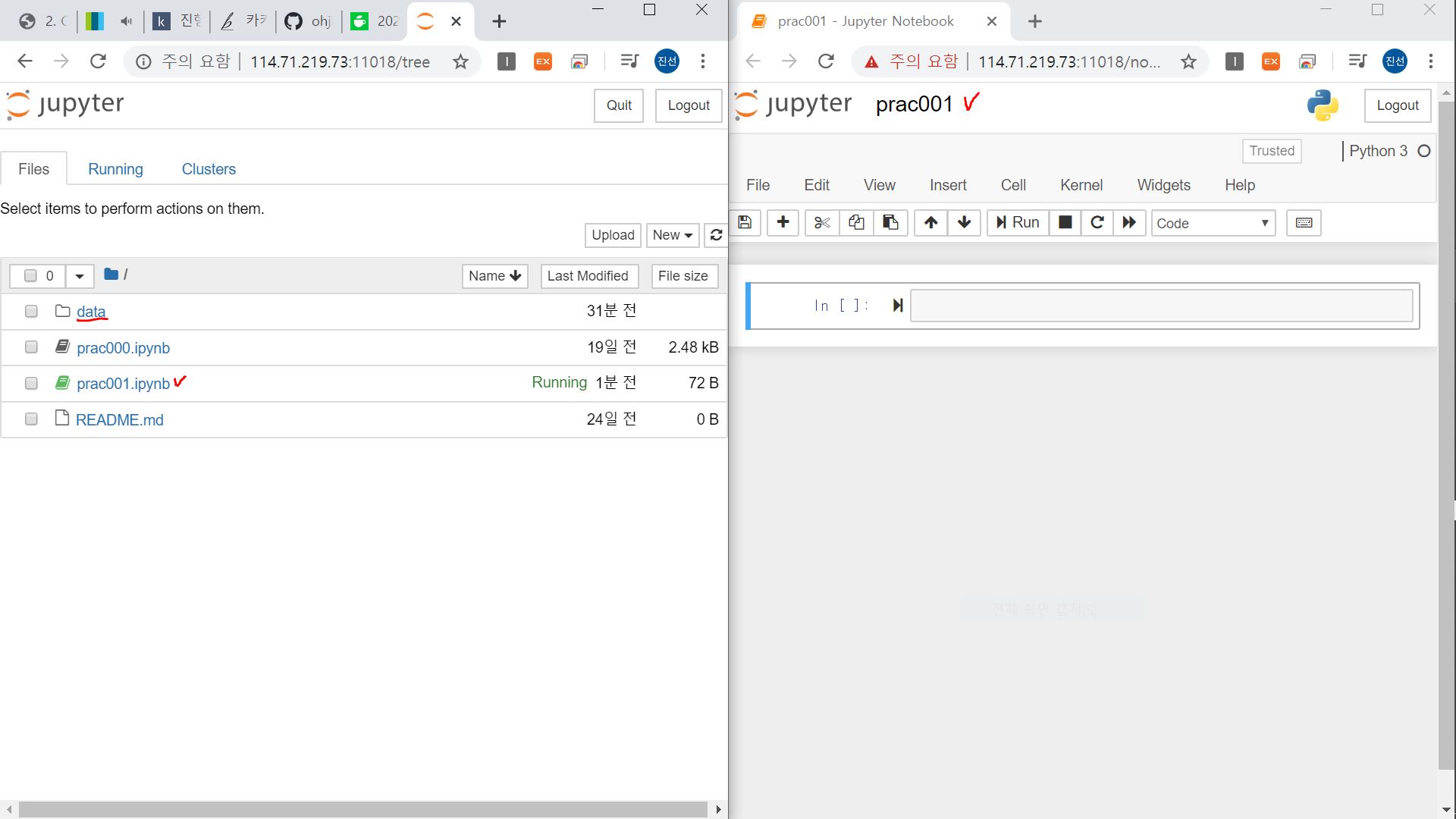
터미널에 jupyter notebook을 입력해주시고, 윈도우 호스트에서 웹브라우저를 통해 발행받은 토큰을 입력하여 새 python 코드를 생성합니다.
이 때 아래 캡처를 참고하여 소스코드와 데이터 리소스의 상대적 위치를 확인해주시기 바랍니다!
탭으로 구분되어있는 데이터파일을 판다스 라이브러리를 이용해 바로 읽어들이려하면 데이터파일과 파이선의 인/디코딩이 맞지 않아 오류를 맞이하게 됩니다.
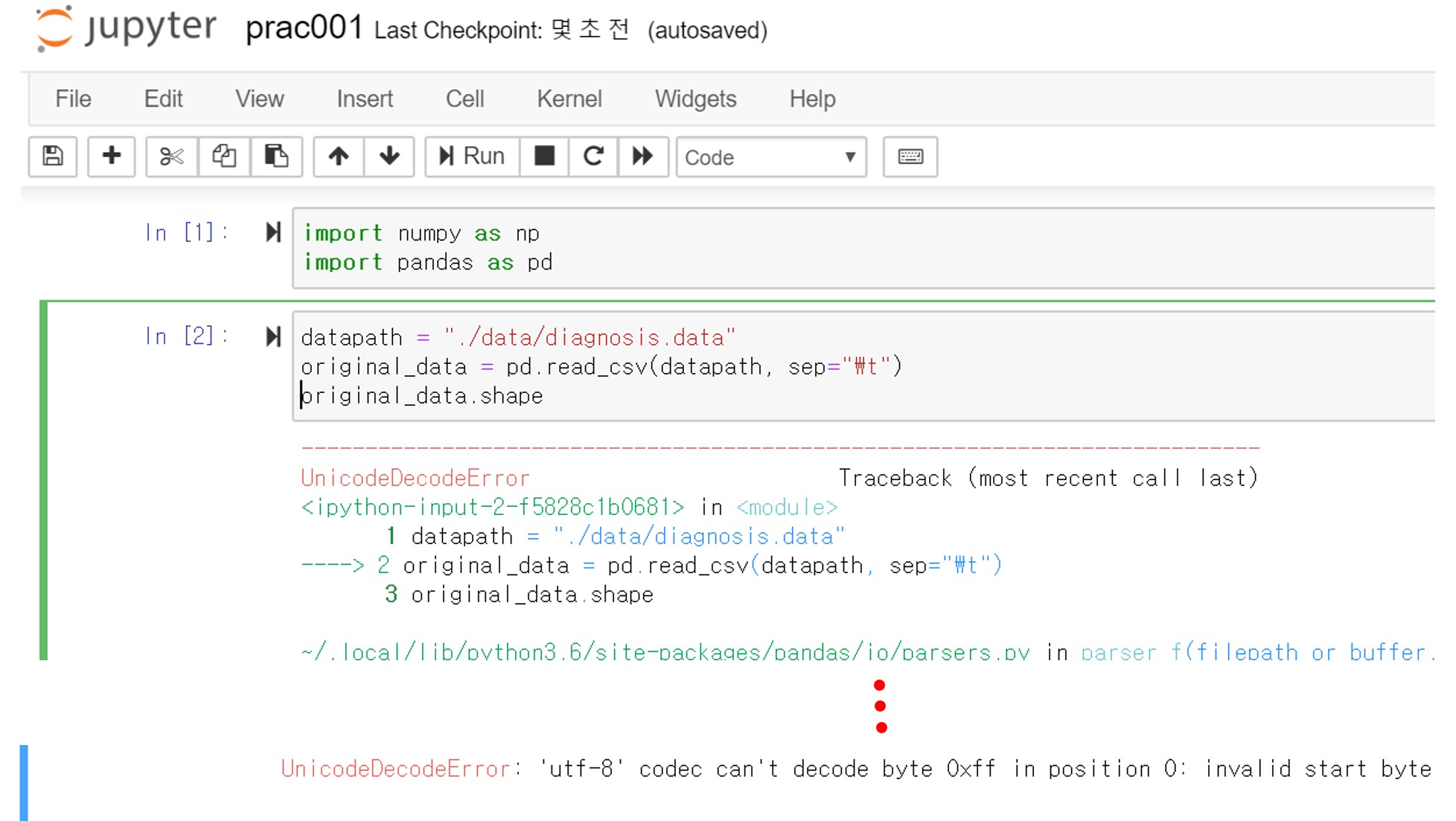
정말로 인코딩이 맞지 않은 건지 확인해봅시다!
그리고 파일 형식을 utf8로 바꿔봅시다.
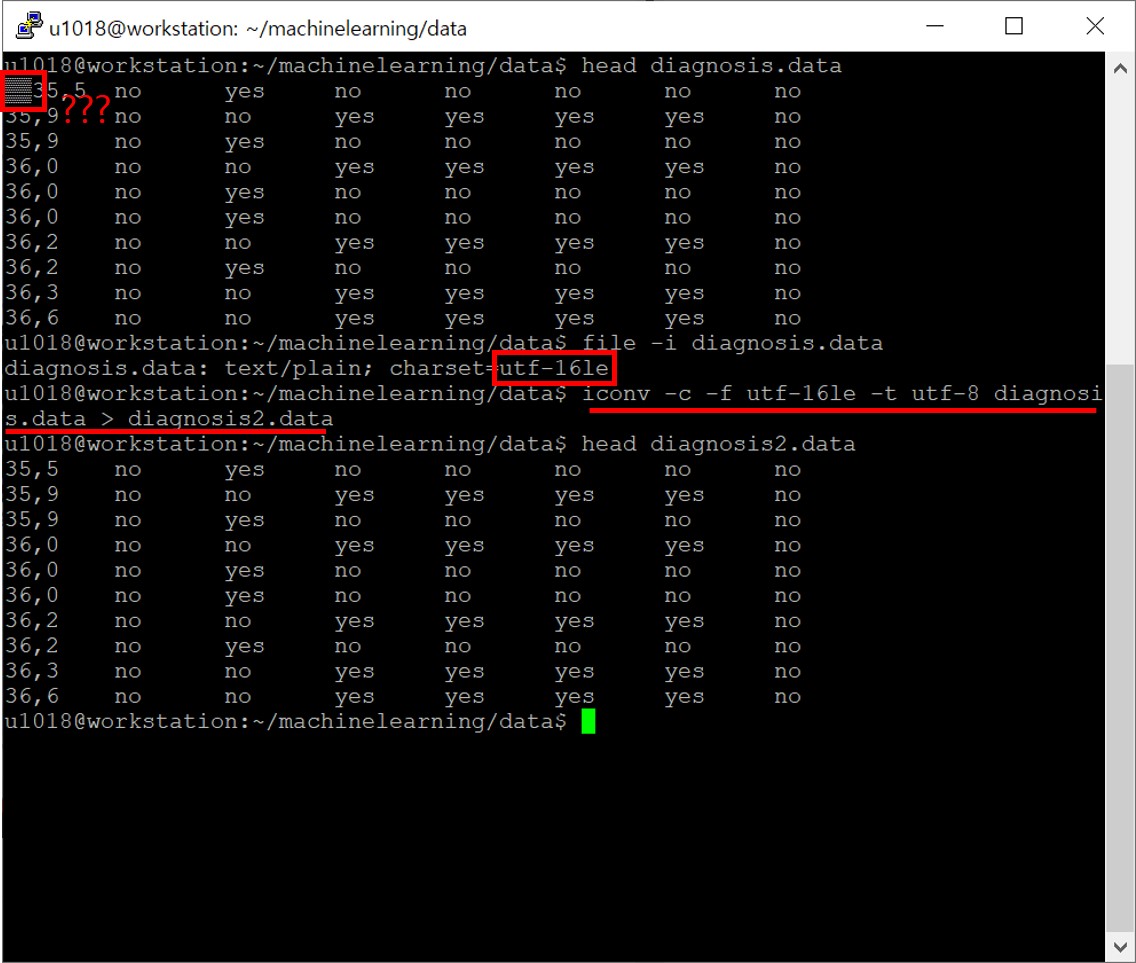
utf8로 인코딩한 복사본, diagnosis2.data를 가지고 실습을 진행하면 잘 될 것입니다.
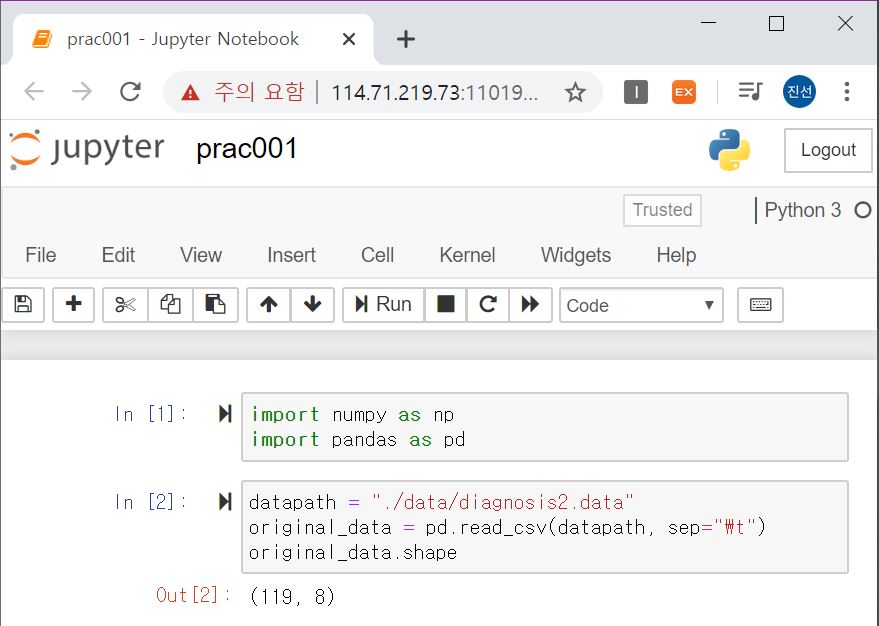
119 X 8의 shape을 가진 데이터라는 것을 알 수 있네요!
사실 이렇게 위 방법대로 바꾸는 방법도 있지만, pandas.read_csv() 의 인수로 encoding=”utf-16”으로 지정해 호출해도 된답니다 :D.
그런데 아까 데이터를 10행까지 찍어봐서 알 수 있었지만 열이름이
지정되지 않았을거에요. 바로 첫행부터 데이터가 차있죠.
열에 이름이 없을 경우엔 데이터를 feature별로 처리하기에 다소 불편함이 있겠죠?
특히나 이 실습은 Decision Tree인데 말이죠!
그래서 names라는 매개변수를 정해서 넘겨주면 됩니다!
각 데이터 열의 이름은 초기 설명드렸던 데이터 디스크립션을 보고 지정해주시면 됩니다.
그리고 나서 다시 실행시켜보면 데이터 shape의 행이 아까보다 1 증가되었음을 확인하실 수 있습니다.
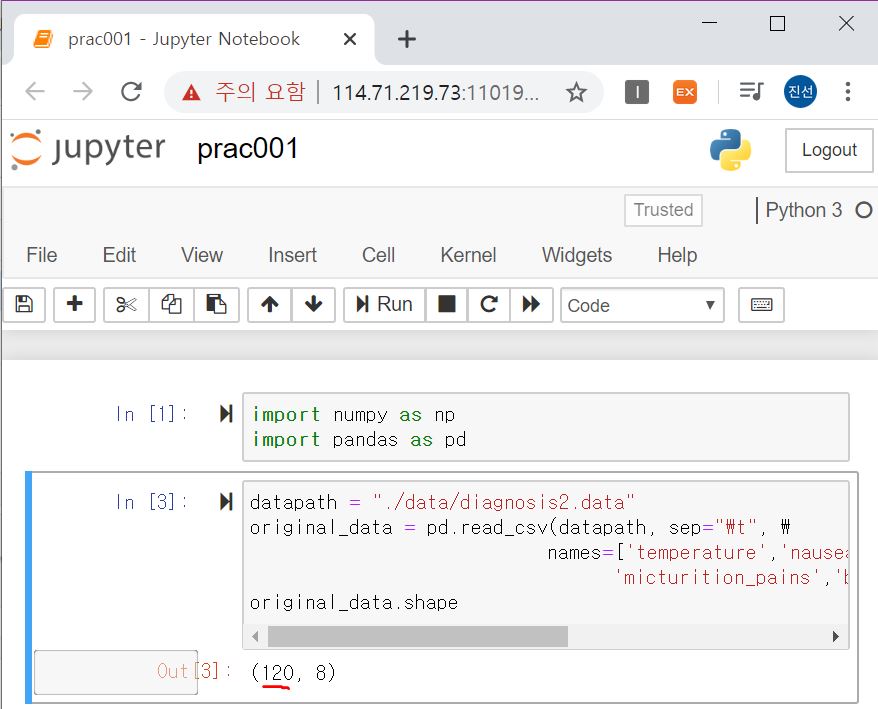
데이터 전처리 작업에 대한 설명은 소스코드에 주석으로 설명을 대체하며, 궁극적으로 모델을 적용해보도록 합시다!
실습 소스코드 링크
(수정중)