Building Spark Applications-Understading BigData(14)
Intro
학교 수강과목에서 학습한 내용을 복습하는 용도의 포스트입니다.
빅데이터 개념과 오픈소스인 아파치 하둡과 맵리듀스 및 스파크를 이용한 빅데이터 적용을 공부합니다.
맵 리듀스의 경우 사용하기에 다소 진입장벽이 있는편입니다.
스파크처럼 통합 환경을 제공하지 않아 원하는 유틸리티나 라이브러리를 별도로 연결해서 사용해야하기 때문입니다. 이를 해소하는 것이 스파크라는 분산 데이터 처리 통합 엔진입니다.
따라서 맵 리듀스로 먼저 공부해보고, 스파크로 넘어갑니다.
스파크 엔진의 경우 Java가 아닌 Scalar라는 언어로 사용하며, 기존 우리가 알고 있는 SQL을 통해 고급 질의가 가능하며, 시각화나 스트림 처리 및 기계학습등 까지의 높은 수준의 분석을 제공하는 통합 프레임 워크입니다.
빅데이터 컴퓨팅(분산시스템상의 분산처리 환경)의 기본 개념과 원리를 이해하고 이를 실습해보는 과정에서 2대 이상의 리눅스 클러스터 서버를 구축 및 활용할 것입니다.
빅데이터이해(1) 보러가기
빅데이터이해(2) 보러가기
빅데이터이해(3) 보러가기
빅데이터이해(4) 보러가기
빅데이터이해(5) 보러가기
빅데이터이해(6) 보러가기
빅데이터이해(7) 보러가기
빅데이터이해(8) 보러가기
빅데이터이해(9) 보러가기
빅데이터이해(10) 보러가기
빅데이터이해(11) 보러가기
빅데이터이해(12) 보러가기
빅데이터이해(13) 보러가기
이번 시간에는 지난 시간에 이어서 스파크 응용 구축에 대해 배웁니다.
스파크 프로그램 수명주기, 스파크 응용 실행 환경, SFPD 스파크 응용 순서대로 학습하겠습니다.
Life Cycle of Spark Program
여태까지 우리가 배웠떤 스파크 프로그램이 실행되는 단계는 아래와 같습니다.
스파크응용을 관리하고 정보를 유지하면서 작업들을 각 분산 노드에 배포하는 역할의 응용을 Driver Program이라고 합니다.
이러한 Driver Program 상에 베이스 데이터세트를 생성해줍니다.
우리가 원하는 활용도에 맞게 데이터를 변환하고 액션하게 됩니다.
이 때 우리는 베이스 데이터세트를 변경하는 것이 아니라 immutable하기 때문에 새로운 데이터세트를 정의하는 것입니다.
지연 변환이 적용될 것이구요.
그 과정에서 재사용될 데이터세트의 경우 캐싱을 해줍니다.
실제 액션을 수행하게 되면 지연된 변환 과정이 수행되고 결과를 산출합니다.
스파크의 구성요소로는 스파크 세션이 있는 Driver Program이 있고, 물리적인 자원을 관리 및 할당하는 클러스터 관리자, Worker node가 있습니다.
그래서 크게 실행자 프로세스를 실행하는 worker node, Driver Program 두 가지로 구성된다고 말할 수 있습니다.
스파크는 마스터-슬레이브 구조로 구성되어있습니다.
그리고 하나의 중앙 중재자 역할의 드라이버가 있고, 많은 분산 작업자들이 있습니다.
드라이버와 작업자들은 각각 자신의 자바프로세스를 실행합니다.
이러한 드라이버와 실행자를 묶어서 우리는 스파크 응용이라고 부릅니다.
스파크에 대한 응용을 실행하기 위해서는 응용을 드라이버프로그램에 submit 해주어야합니다.
사용자는 spark-submit 명령으로 스파크 응용을 제출합니다.
이 명령어로 드라이버 프로그램이 시작되며 main() 메소드를 호출하게되고 main() 메소드에서는 SparkSession을 생성하게 됩니다.
SparkSession은 클러스터 관리자의 위치를 드라이버에게 알려줍니다.
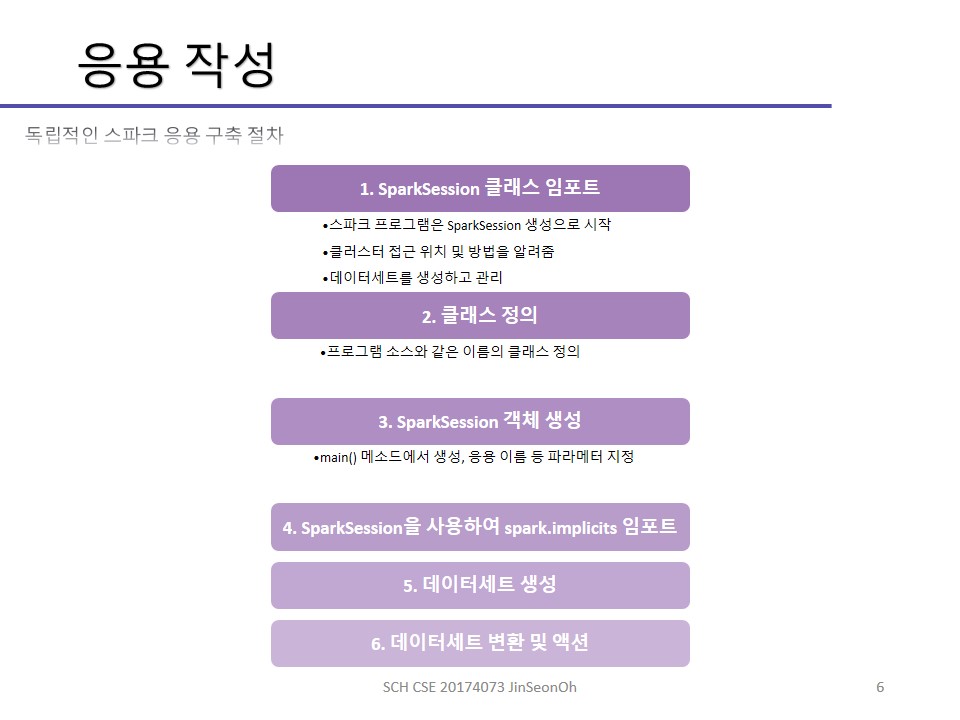
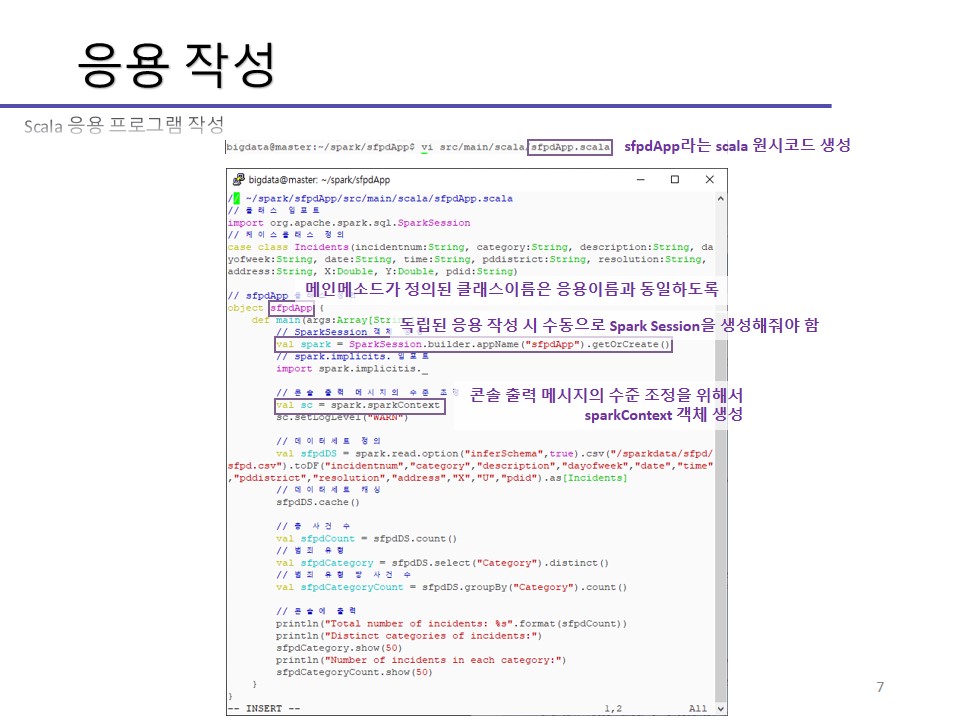
그래서 독자적인 응용으로 빌드하고 구축할 때는 main()을 작성해주어야 합니다.
드라이버 프로그램은 자원을 요청하고 실행자의 실행을 위해 드라이버 클러스터 관리자에 연결합니다.
이후 클러스터 관리자는 드라이버 프로그램을 위한 실행자를 실행합니다.
정리하자면 드라이버는 응용을 실행하는데, SparkSession을 생성하고 데이터세트를 정의하고, 변환을 수행하며 액션을 적용하게 됩니다.
이러한 내용이 기술된 Jar 또는 python 파일의 작업을 태스크 형식으로 실행자에게 전송하게 됩니다.
실행자의 태스크들을 실행할 때에는 태스크 단위로 분산되어 병렬 실행하게 됩니다.
응용의 종료 시에는 Main() 메소드가 SparkSession.stop을 호출하여 응용을 종료하게 됩니다.
한 번 더 정리하면 아래와 같습니다.
- 사용자는 응용을 작성한 후 spark-submit 명령을 입력
- Driver Program 실행하여 데이터세트 생성, 변환, 액션을 수행 빌드 내용을 물리적 자원 관리하는 Cluster Manager에게 연결
- Cluster Manager는 자원을 분산 할당
- 실행자가 실행됨
스파크 응용 실행 환경
스파크는 클러스터 관리자를 통해 실행자를 실행시킨다고 했습니다.
클러스터 관리자는 스파크의 플러그가 가능한 컴포넌트들이어서 Hadoop YARN, Apache Mesos 등과 같은 다양한 자원들의 관리가 가능합니다.
또한 스파크 자체의 내장 클러스터 관리자도 제공되고 있습니다.
총 네가지 실행 모드가 있습니다.
- Local Mode
Runs in the same JVM 환경 - Standalone Mode
스파크 자체 모드, Simple cluster manager 환경 - Hadop YARN Mode
이 실습에서 다루는 모드, Resource manager in Hadoop 2 환경 - Apache Mesos Mode
General cluster manager 환경
Local Mode
로컬 모드의 경우 하나의 JVM에서 드라이버와 작업자가 실행되는 환경을 말합니다.
모든 데이터세트들이 같은 메모리 공간에 생성되며 중앙의 마스터가 없고, 사용자가 실행을 시작하게 되므로 개발 단계에서 프로토타이핑, 디버깅, 테스팅 용도에 적합하다는 특징을 갖습니다.
Standalone deploy Mode
독립형 모드의 경우 스파크가 제공하는 독립적인 클러스터 모드로 마스터와 작업자들을 수작업으로 실행하거나, 스파크에서 제공하는 스크립트를 사용하여 실행합니다.
클러스터의 각 노드에서 스파크의 컴파일된 버전을 배치해야할 필요가 있습니다.
마스터의 spark://IP:PORT URL을 SparkSession 생성자에 전달하여 스파크 클러스터에서의 응용을 실행합니다.
Hadoop YARN Mode
하둡 클러스터의 YARN에서 실행되며 클러스터 모드와 클라이언트 모드 두가지의 동작 모드가 존재합니다.
이중 클러스터 모드는 드라이버가 YARN 클러스터의 응용 마스터를 실행하게됩니다.
비동기 프로세스로 실행되어 작업이 종료될 때까지 기다리지 않습니다.
개발 완료 후 배포 버전에 적합합니다.
클라이언트 모드의 경우 드라이버가 클라이언트 프로세스로 실행하고, 동기형 프로세스이며, 개발 진행 상태의 상호작용의 쉘이나 디버깅 등에 적합합니다.
Apache Mesos Mode
아파치 Mesos 클러스터 관리자를 사용합니다.
아파치 Mesos는 버클리대에서 개발한 클러스터 관리자로 데이터 센터 내의 자원을 공유/격리를 관리하는 기술로 개발되어 오픈소스로서 많이 사용되고 있습니다.
우리는 이중에서 하둡얀 모드로 실습하고 있습니다.
우리가 스파크 프로그램을 작성하고 jar파일로 빌드를 한 후에는 spark-submit 명령을 통해 응용을 실행하게 되는데요, spark 설치 디렉토리의 bin\spark-submit이라는 스크립트로 제공되고 있습니다.
 spark
-submit은 응용을 실행하는 스크립트로서 여러 옵션을 기술하게 되는데, class의 경우 응용의 시작점을 즉 main class를 기술합니다.
spark
-submit은 응용을 실행하는 스크립트로서 여러 옵션을 기술하게 되는데, class의 경우 응용의 시작점을 즉 main class를 기술합니다.
master 옵션은 클러스터의 마스터 URL 또는 실행 모드를 기술하며
deploy-mode는 동작모드를 지정하는 옵션입니다.
conf 옵션은 스파크 설정 프로퍼티를 위한 옵션으로서 key와 value 형태로 입력해주어야하고 application-jar는 응용의 jar 파일을 기술하는 부분이고, application-arguments는 main 메소드로 전달될 인수를 기술하는 부분입니다.
네 가지 실행 모드 별 실행 명령어의 예시 입니다.
로컬모드
$SPARK_HOME/bin/spark-submit-class <class path> --master local[n] <application-jar>
이 때 n은 마스터가 멀티 코어의 경우 독립적으로 실행할 수 있는 태스크의 수를 기술하는 부분입니다.
독립형모드
$SPARK_HOME/bin/spark-submit-class <class path> --master spark:<master url> <application-jar>
YARN 클러스터
$SPARK_HOME/bin/spark-submit-class <class path> --master yarn --deploy-mode cluster <application-jar>
YARN 클라이언트
$SPARK_HOME/bin/spark-submit-class <class path> --master yarn --deploy-mode client <application-jar>
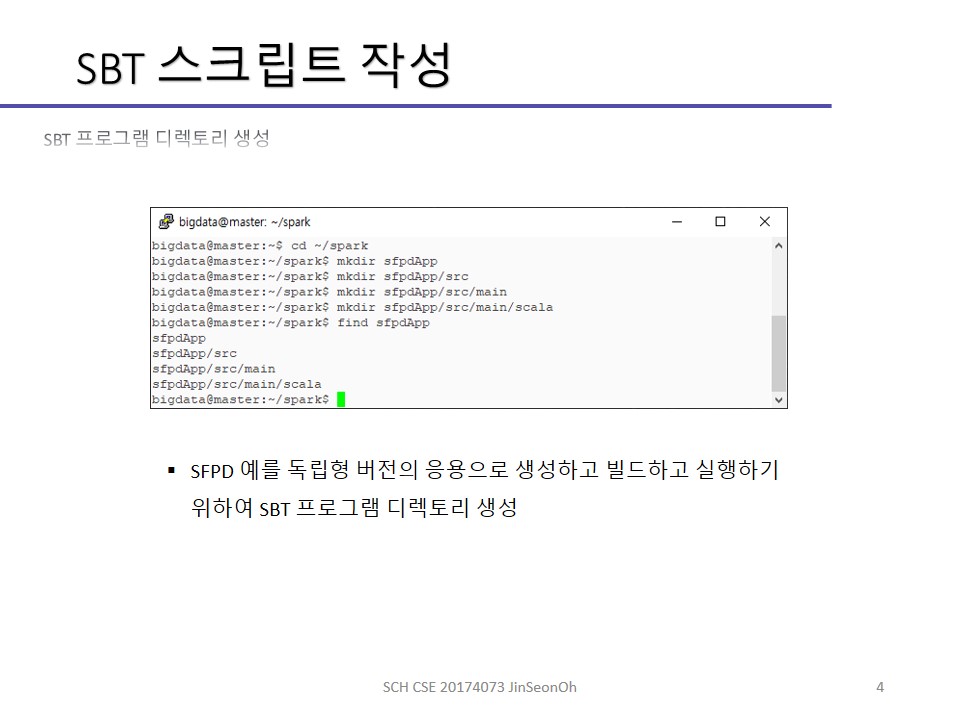
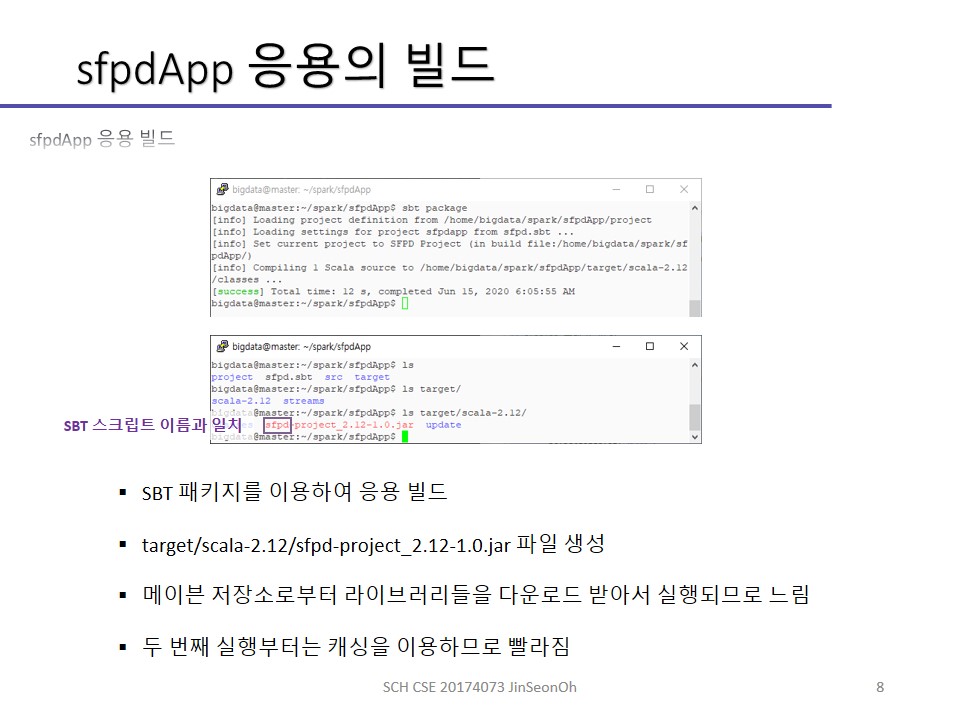
SBT라는 빌드툴을 이용해 응용을 실행하는 실습 과정을 아래에 캡처하여 실어놓겠습니다.
SBT 빌드툴을 이용하여 프로젝트 스크립트를 작성하는 내용과 관련하여 참고할만한 링크를 아래에 걸어드리겠습니다.
https://mvnrepository.com/artifact/org.apache.spark/spark-core
https://mvnrepository.com/artifact/org.apache.spark/spark-sql
그 중에서도 특히 2.4.5버전에 대한 글을 보시려면 아래 링크를 이용해주세요.
https://mvnrepository.com/artifact/org.apache.spark/spark-core_2.12/2.4.5
https://mvnrepository.com/artifact/org.apache.spark/spark-sql_2.12/2.4.5