
Spark Streaming-Understading BigData(16)
Intro
학교 수강과목에서 학습한 내용을 복습하는 용도의 포스트입니다.
빅데이터 개념과 오픈소스인 아파치 하둡과 맵리듀스 및 스파크를 이용한 빅데이터 적용을 공부합니다.
맵 리듀스의 경우 사용하기에 다소 진입장벽이 있는편입니다.
스파크처럼 통합 환경을 제공하지 않아 원하는 유틸리티나 라이브러리를 별도로 연결해서 사용해야하기 때문입니다. 이를 해소하는 것이 스파크라는 분산 데이터 처리 통합 엔진입니다.
따라서 맵 리듀스로 먼저 공부해보고, 스파크로 넘어갑니다.
스파크 엔진의 경우 Java가 아닌 Scalar라는 언어로 사용하며, 기존 우리가 알고 있는 SQL을 통해 고급 질의가 가능하며, 시각화나 스트림 처리 및 기계학습등 까지의 높은 수준의 분석을 제공하는 통합 프레임 워크입니다.
빅데이터 컴퓨팅(분산시스템상의 분산처리 환경)의 기본 개념과 원리를 이해하고 이를 실습해보는 과정에서 2대 이상의 리눅스 클러스터 서버를 구축 및 활용할 것입니다.
빅데이터이해(1) 보러가기
빅데이터이해(2) 보러가기
빅데이터이해(3) 보러가기
빅데이터이해(4) 보러가기
빅데이터이해(5) 보러가기
빅데이터이해(6) 보러가기
빅데이터이해(7) 보러가기
빅데이터이해(8) 보러가기
빅데이터이해(9) 보러가기
빅데이터이해(10) 보러가기
빅데이터이해(11) 보러가기
빅데이터이해(12) 보러가기
빅데이터이해(13) 보러가기
빅데이터이해(14) 보러가기
빅데이터이해(15) 보러가기
이번 시간에는 스파크 스트리밍에 대해서 배웁니다.
스파크 스트리밍 아키텍처를 학습하고나서 데이터 조사부터 센서데이터를 응용하여 스트리밍 처리를 하는 과정에 대해 학습해보겠습니다.
스트림 처리 아키텍처
일반적으로 스트림 처리 아키텍처(streaming processing architecture)는 외부의 소스에서 데이터 스트림을 수집하게됩니다.
스트림이란 연속적으로 발생하는 데이터를 말하는데요, 데이터 소스들은 예를 들어 센서네트워크, 모바일응용, SNS, 웹 클라이언트, 서버의 로그, IoT에서의 Things 등이 있겠습니다.
데이터는 Kafka, Flume, Redis, MAPR Streams, 또는 내장된 파일 시스템 등과 같은 메시징 시스템을 경유하여 전달하게됩니다.
이 포스팅에서는 다루진 않겠지만 메시징 시스템은 IoT의 구현에 있어서 중요한 부분을 차지합니다.
동시다발적으로 발생되는 스트림 데이터는 스파크 스트리밍 등과 같은 스트림 처리 시스템 상에서 처리하게 됩니다.
본문에서는 메시징 시스템 없이 우회해서 처리하는 내용에 대해서 다룹니다.
그렇게 처리된 데이터는 HBase, Cassandra, MAPR-DB 등과같은 NoSQL 데이터베이스에 저장되게 됩니다.
빅데이터 파이프라인의 마지막 단계인 분석단계에서는 DB에 저장된 내용들을 가지고 대시보드, 분석 툴 등과 같은 종단의 응용을 구축하곤 합니다.
심지어는 Spark로 다시 피드백 되어 분석될 수도 있구요.
스파크는 이와 같이 연속적인 스트림 데이터를 처리하기 위해 특정 구간 단위로 분할하여 즉, 배치로 처리하게 됩니다.
스파크 SQL 관점에서 보면 데이터프레임이나 데이터세트등은 테이블과 같이 생겼다했었는데요, 일종의 구조적 스트리밍인 것입니다.
다시 말해 스파크는 라이브 데이터 스트림을 연속적으로 추가되는 테이블로 관리하게 됩니다.
단 행 개수에 제한이 없는 unbounded table인 것이죠.
신용카드 트랜잭션 등이 그 예입니다.
새로운 트랜잭션 데이터가 들어오면 각 레코드가 테이블의 행으로 추가되지요.
구조적 스트리밍을 처리한다는 이야기는 SQL 관점에서는 질의에 해당합니다.
특정 시점에서의 데이터 처리를 할 수 있어야합니다.
고정된 데이터가 아니기 때문에 고려해줘야하는 문제입니다.
신용카드 사기로 의심되는 결과를 출력하는 응용을 작성한다고 했을 때 특정 시점에서의 데이터를 분석해야하는데, 현재 레코드와 이전 기록을 비교하여 분석해야합니다.
그러나 특정 시점 질의 후에도 데이터는 연속적으로 추가되어야할 필요가 있습니다.
그러다가 새로운 질의 요청 시에는 이전 질의 이후에 추가된 데이터에 대해서만 증분질의(incremental query) 처리를 해줘야합니다.
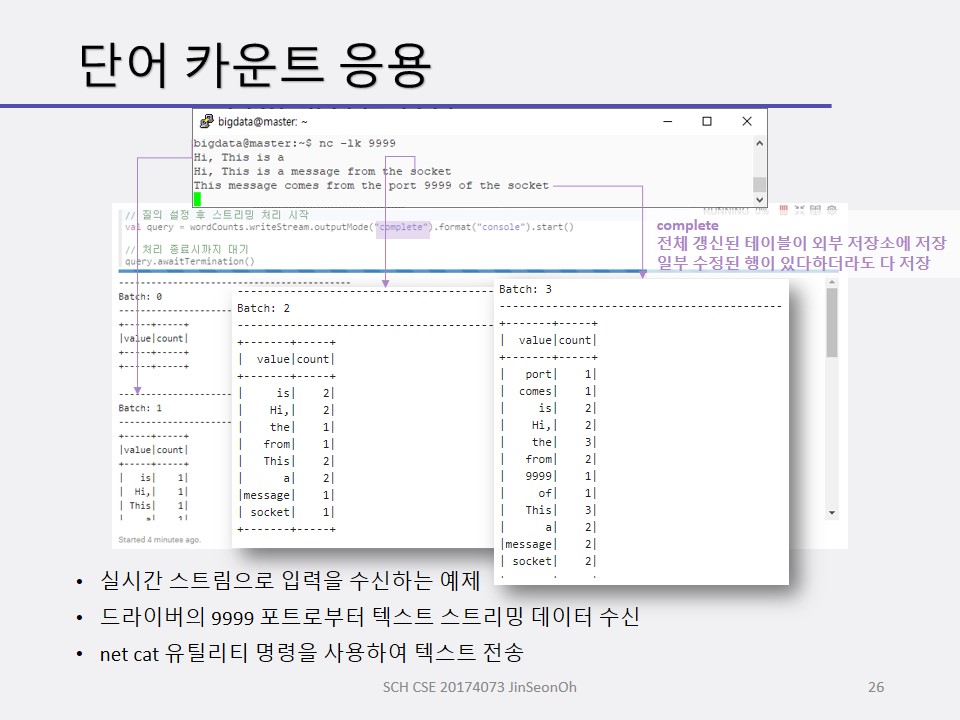
따라서 구조적 스트리밍 처리를 위해서는 특정 구간 내 데이터만 처리할 수 있도록 인터벌 처리를 필수적으로 해줘야하는데요, 각 인터벌(예를 들어 1초) 동안 새로운 행들이 입력 테이블에 추가되고 처리될 것이니 때에 맞춰 출력 테이블을 갱신해줘야합니다.
그렇게 출력된 테이블은 아래와 같이 3가지 모드로 저장됩니다.
- 완료(Complete)
- 추가(Append)
- 갱신(Update)
완료 저장 모드
완료 저장 모드는 전체 갱신된 테이블이 외부 저장소에 저장됩니다.
일부 수정된 행이 있다하더라도 다 저장하게 되지요.
추가 저장 모드
추가 저장 모드는 새롭게 추가된 출력 테이블 행들만 저장됩니다.
이전 인터벌의 결과는 이미 저장되었기 때문에 저장할 필요가 없는 경우에 사용하는 모드이며 수정 갱신된 행은 저장하지 않습니다.
갱신 저장 모드
갱신 저장 모드는 갱신된 출력 테이블의 행들만 저장됩니다.
수정 갱신 또는 추가된 행들이 저장되게 됩니다.
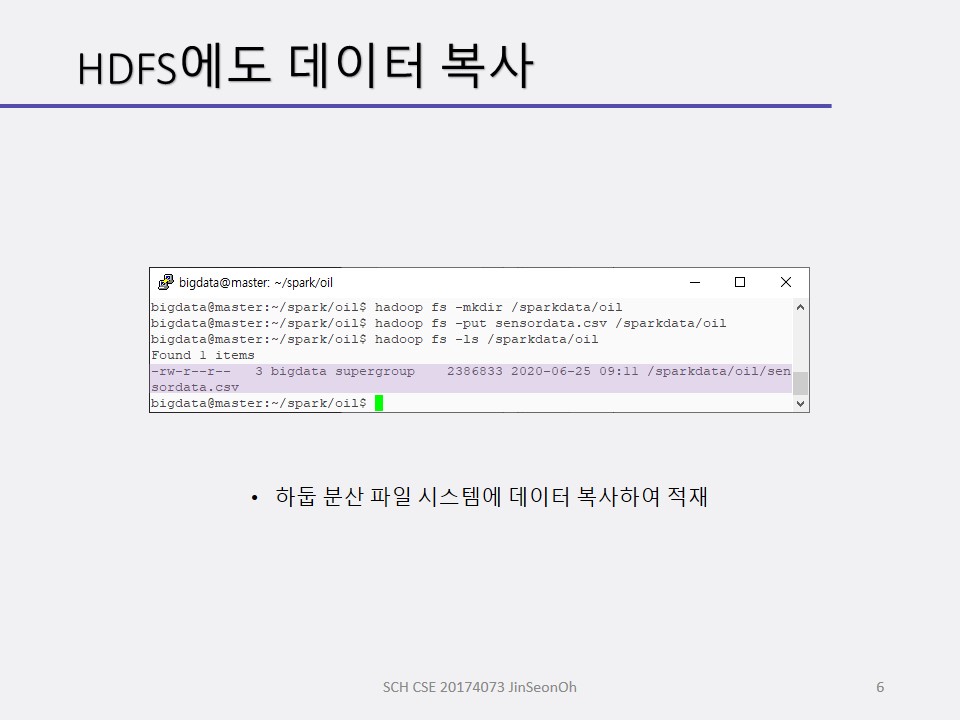
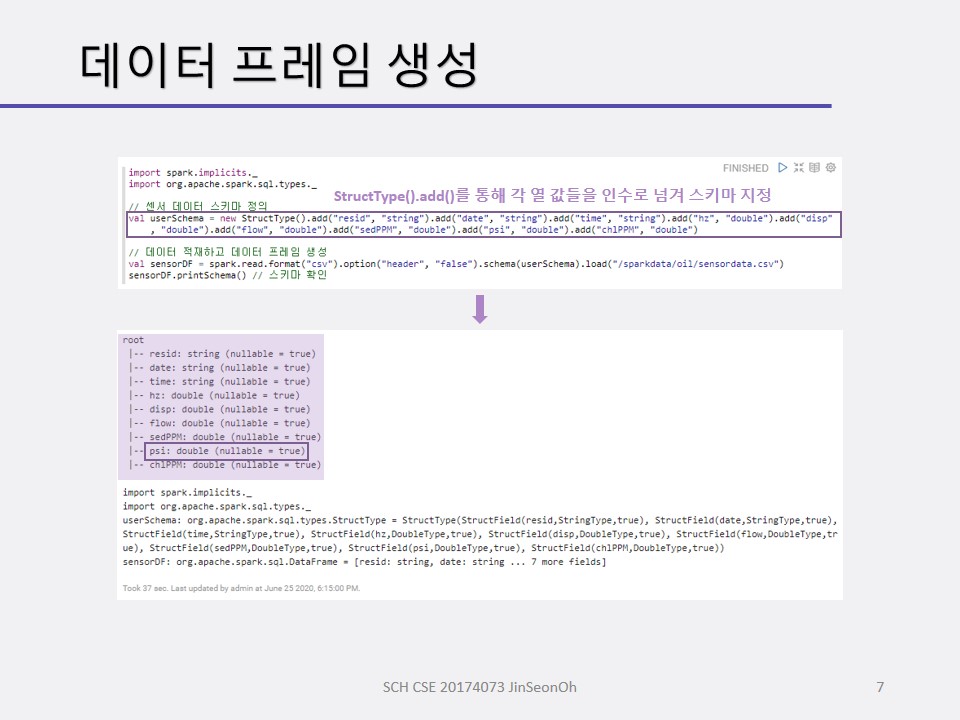
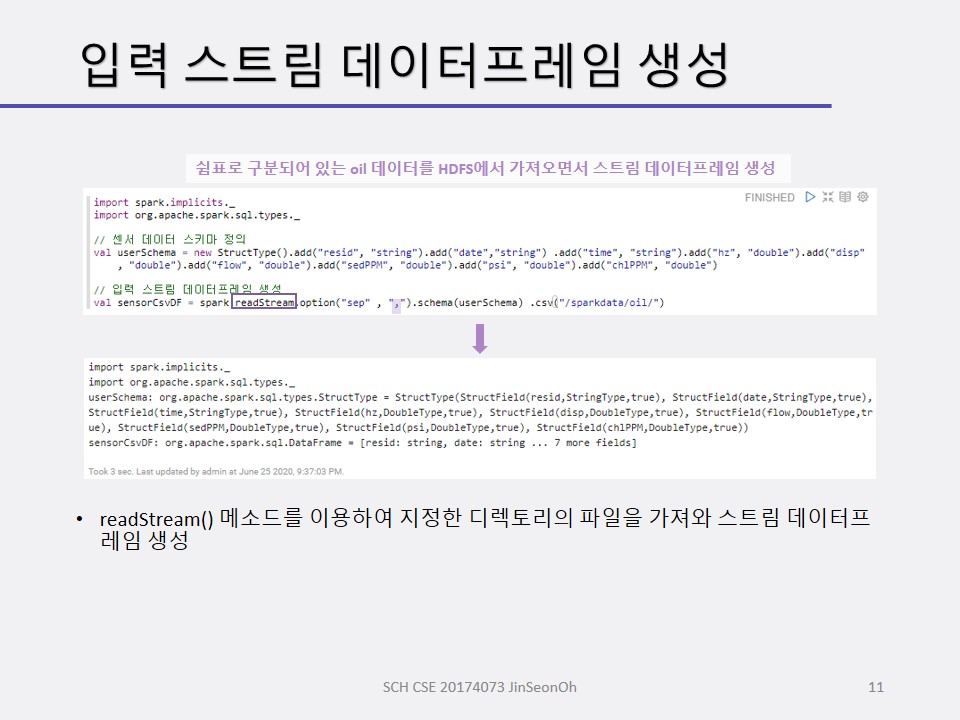
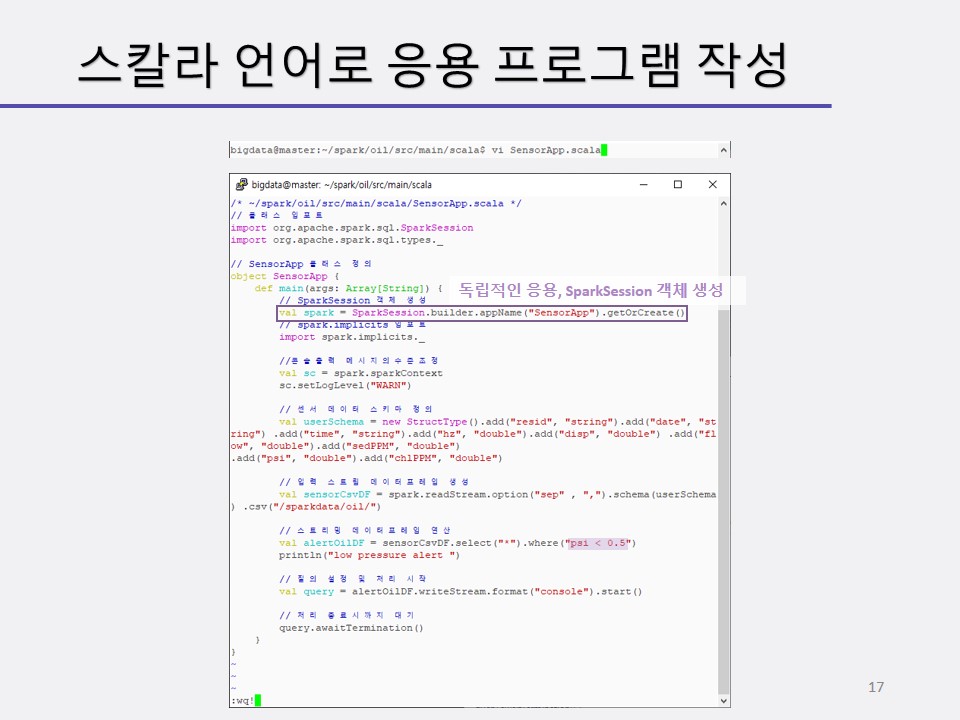
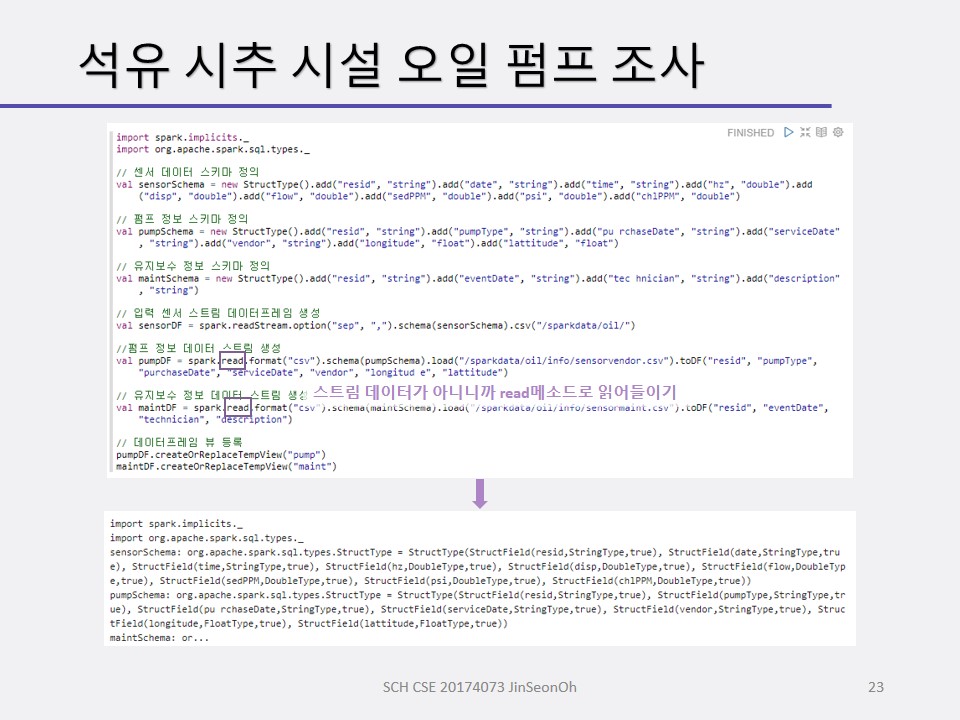
구조적 스트리밍 처리를 할 때 우리는 스파크의 데이터프레임 또는 데이터세트로 생성하며 불러들이게 될 것입니다.
readStream() 메소드가 그 역할을 해줍니다.
자세한 사용 예는 맨 아래의 실습에서 살펴보겠습니다.
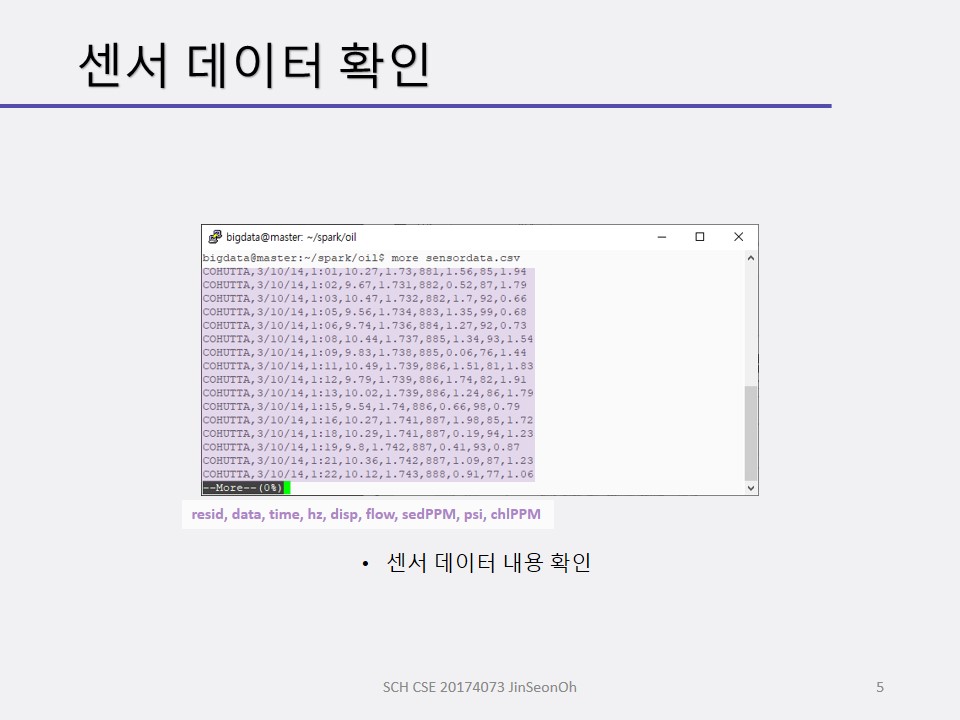
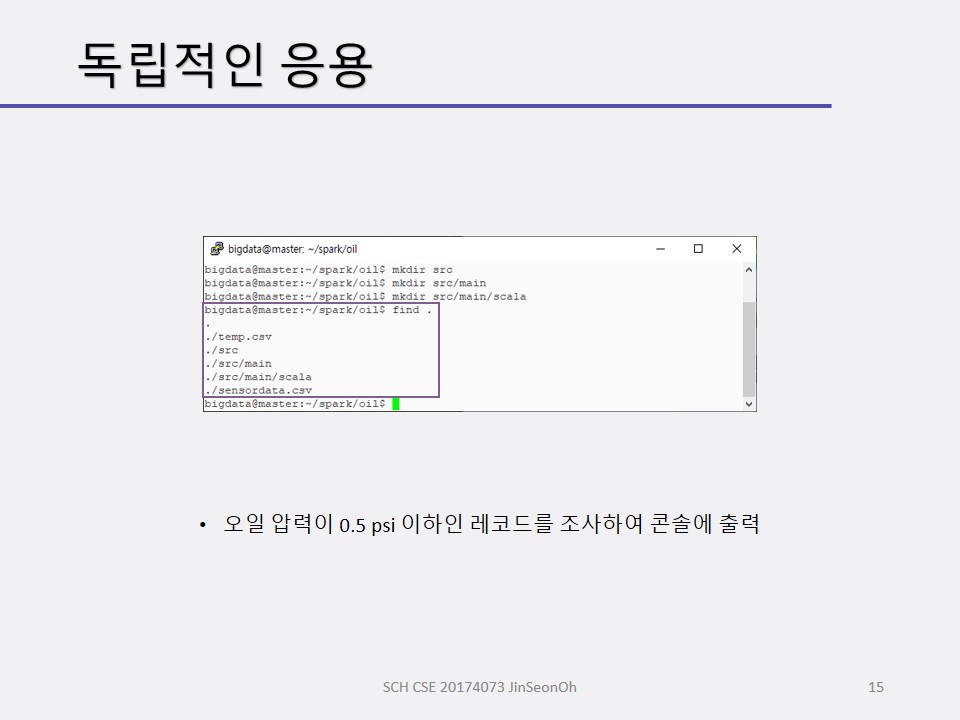
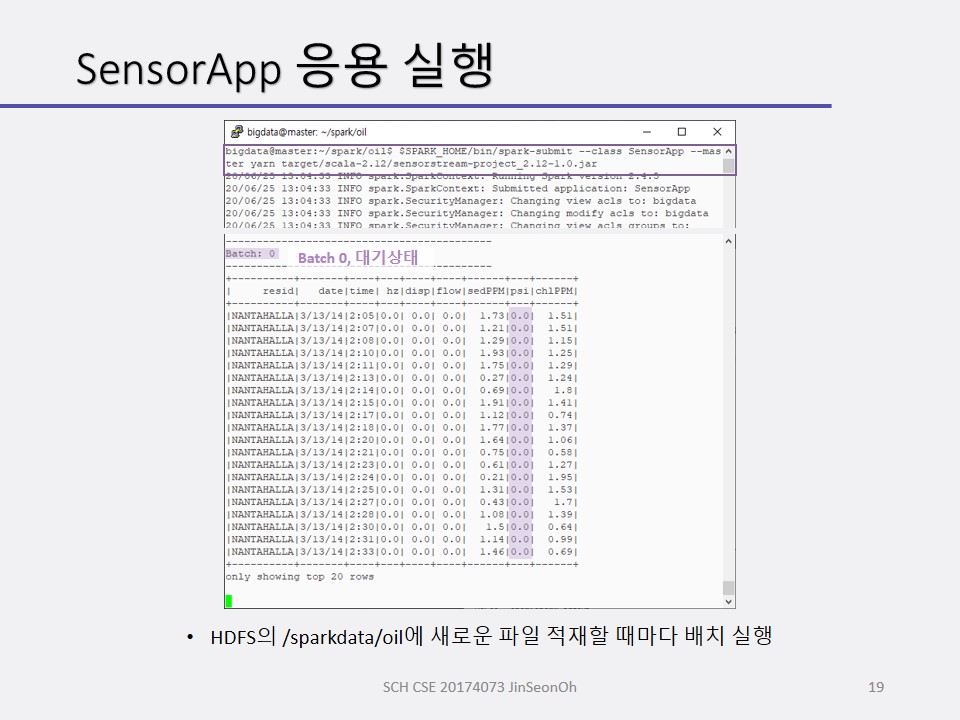
센서 데이터 응용_데이터 조사
센서 데이터 모니터링 예제는 시계열 데이터 입니다.
석유 시추 시설의 센서 데이터를 모니터링 하는 예제를 볼 겁니다.
석유 시추 설비의 오일 펌프 센서들이 스트리밍 데이터를 생성합니다.
스파크가 처리하여 HBase에 저장하거나 할 수 있는데, 우리는 스트리밍 처리까지만 다뤄보겠습니다.
일별 스파크 처리 내용은 요약 통계로 집계(aggregate)하게 됩니다.
더 응용해보고 싶다면 압력값이 특정 값 이하로 떨어지는 경우에 대해 데이터를 필터링하거나 알람도 저장할 수 있을 것이고 다양한 분석 및 리포팅 툴이 저장된 내용을 사용할 수도 있을 겁니다.
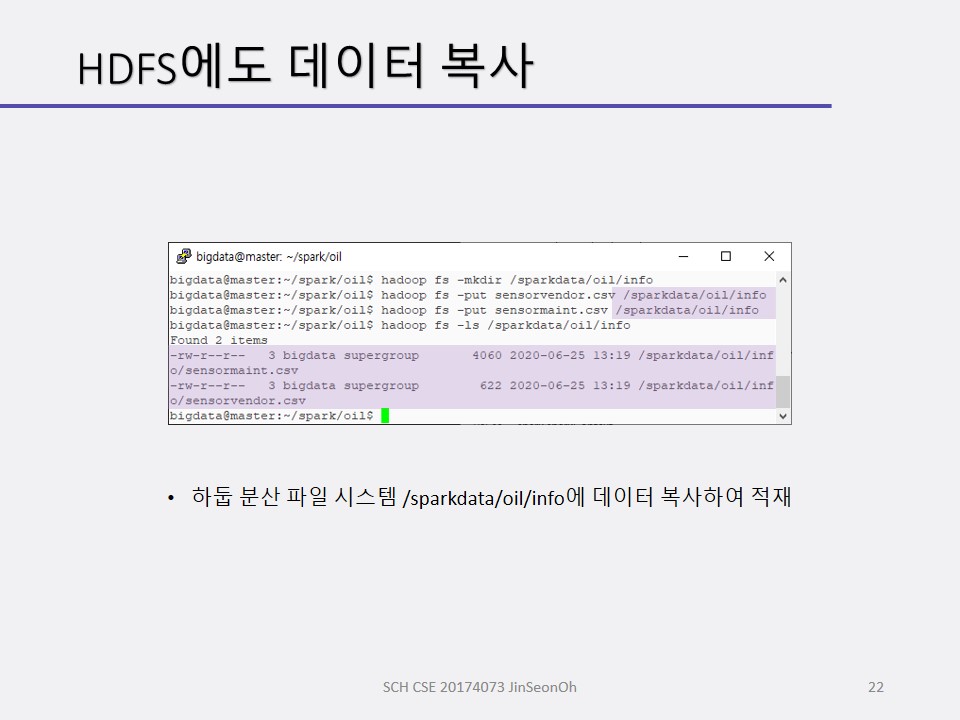
우리의 예에서는 메시징 큐에서 데이터를 받아오는 것이 아니라 csv 파일 형태의 오일 펌프 센서 데이터를 실시간이라고 생각하고.. 이용하게 됩니다.
스트리밍 처리 전에 센서 데이터를 조사할 것입니다.
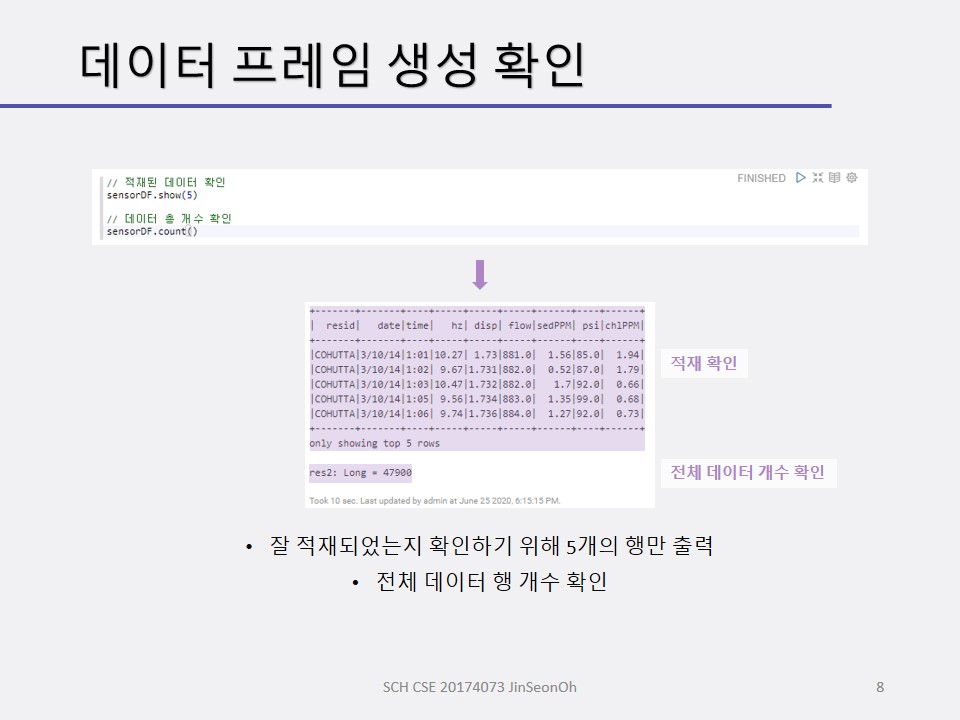
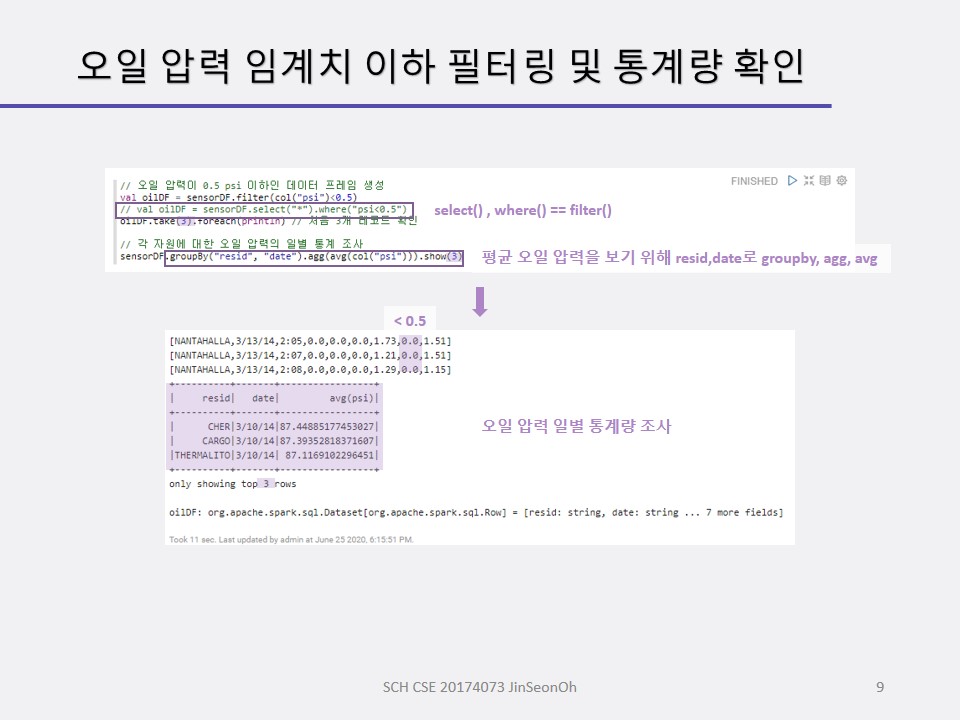
센서 데이터 스키마를 정의하고 적재하여 데이터 프레임을 생성해보며 적재된 데이터( 총 개수 등)를 확인하고 오일 압력이 0.5 psi(pound per square inch) 이하인 레코드를 조사해볼 것입니다.
또한 오일 압력의 일별 통계를 조사하며 SQL을 사용하여 센서 데이터의 일별 통계값을 계산해보겠습니다.
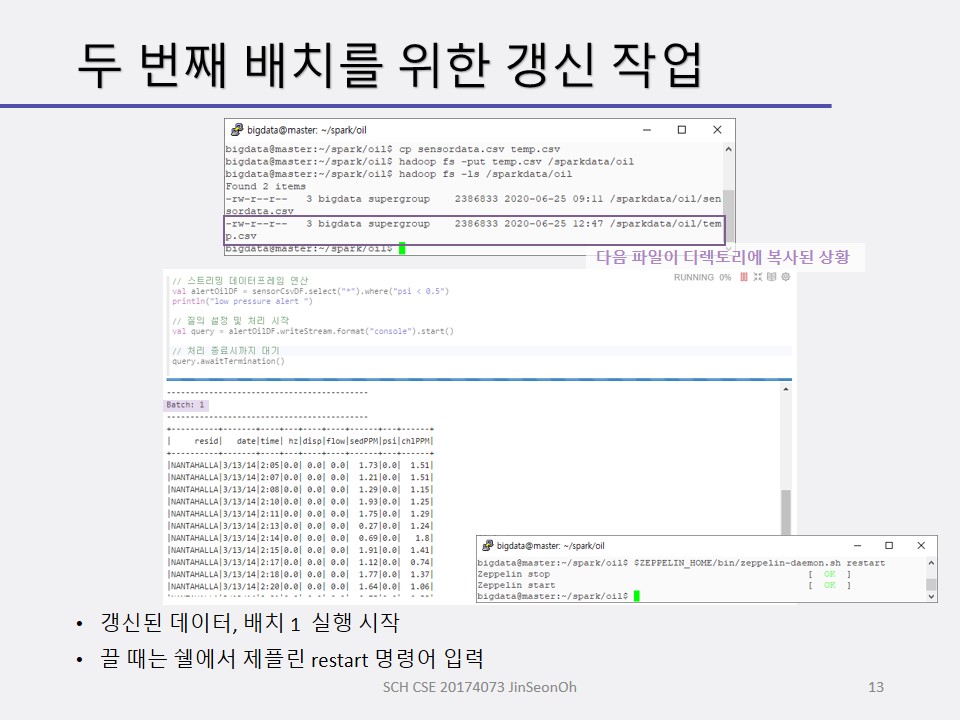
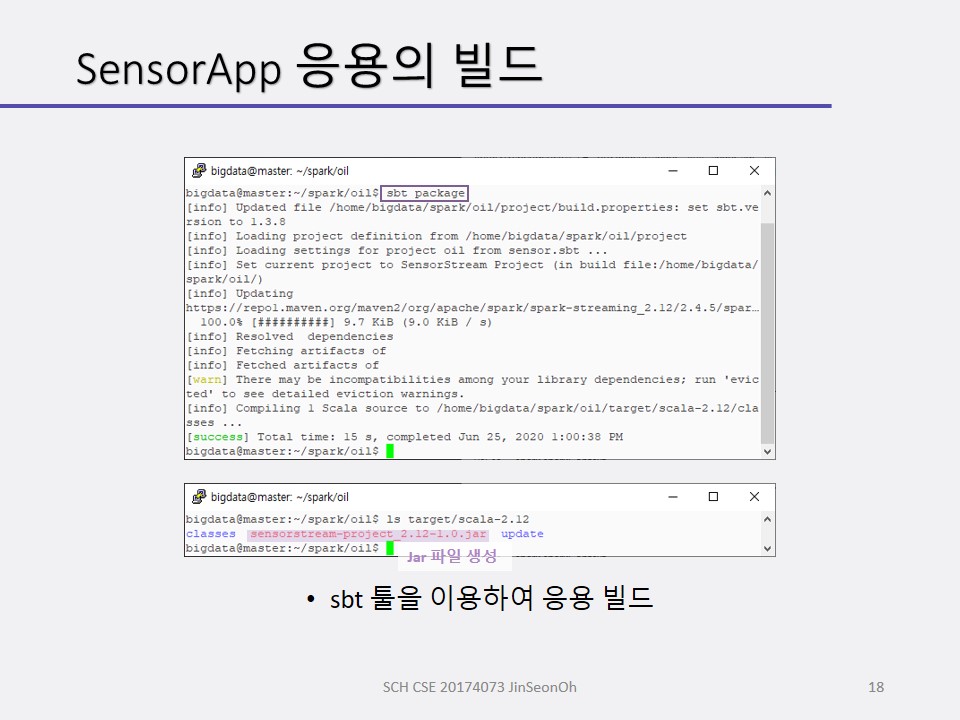
그 다음에 스트림 처리를 할 것입니다.
실습 내용은 맨 아래에 캡처로 실어놓겠습니다.
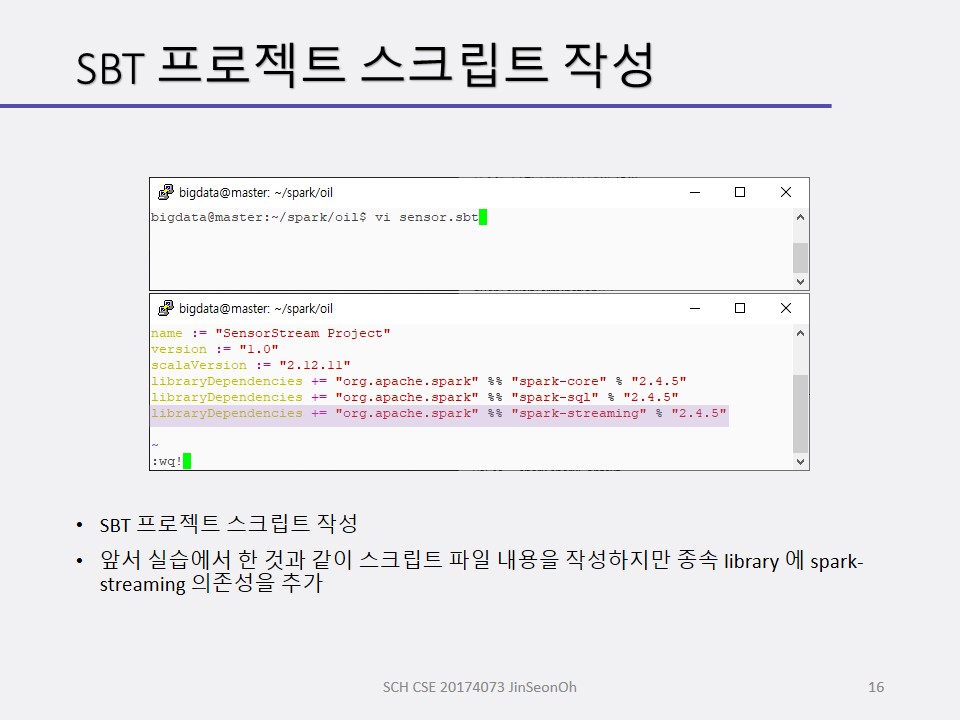
구조적 스트리밍 처리 절차
구조적 스트리밍 처리 절차는 다음과 같습니다.
- SparkSession 객체 생성 및 초기화
- readStream() 메소드를 사용하여 입력 스트리밍 데이터프레임 생성(파일, 소켓, kafka, flume 등 다양한 소스 및 옵션 지정 가능)
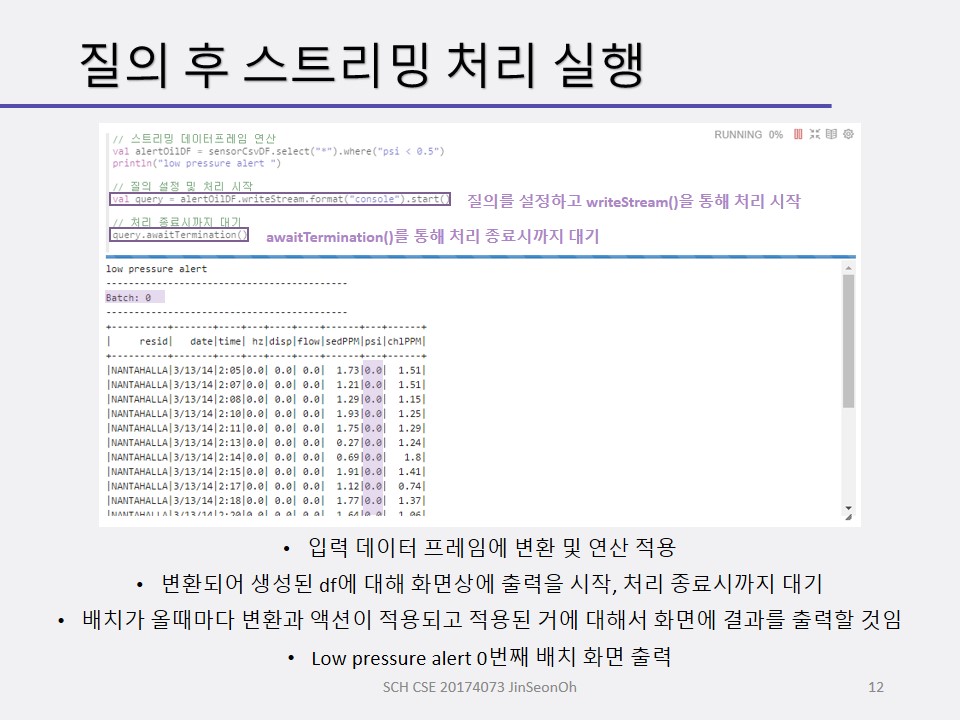
- 스트링 데이터프레임 변환 및 액션 연산 적용(새로운 스트리밍 데이터프레임 생성 포함)
- writeStream() 메소드를 사용하여 질의를 설정 및 처리 시작(출력형식지정가능)
- awaitTermination() 메소드를 사용하여 스트리밍 데이터 처리 종료 시까지 대기








개인이 공부하고 포스팅하는 블로그입니다. 작성한 글 중 오류나 틀린 부분이 있을 경우 과감한 지적 환영합니다!