
Artificial Neural Network LAB_Machine Learning(14)
Intro
학교 수강과목에서 학습한 내용을 복습하는 용도의 포스트입니다.
기존에 수강했던 인공지능과목을 통해서나 혼자 공부했던 내용이 있지만 거기에 머신러닝 수업을 들어서 보충하고 싶어서 수강하게 되었습니다.
gitlab과 putty를 이용하여 교내 서버 호스트에 접속하여 실습하는 내용도 함께 기록하려고 합니다.
위 링크들 중 ANN 모델에 대한 설명은 Machine Learning(9)에 있습니다.
ANN LAB
실습을 하기 위해 데이터를 다운받아주세요.
데이터 디스크립션 읽어보고 data folder에 들어가서 ionosphere.data를 다운받아주세요!
데이터를 먼저 다운로드 받습니다.
저는 아래 캡처화면과 같이 리눅스의 wget 명령어를 통해 url로부터 호스팅되어있는 ionosphere 데이터를 다운로드 받았습니다.
wget https://archive.ics.uci.edu/ml/machine-learning-databases/ionosphere/ionosphere.data
터미널에 jupyter notebook을 입력해주시고, 윈도우 호스트에서 웹브라우저를 통해 발행받은 토큰을 입력하여 새 python 코드(prac005.ipynb)를 생성합니다.
이 때 아래 캡처를 참고하여 소스코드와 데이터 리소스의 상대적 위치를 확인해주시기 바랍니다!
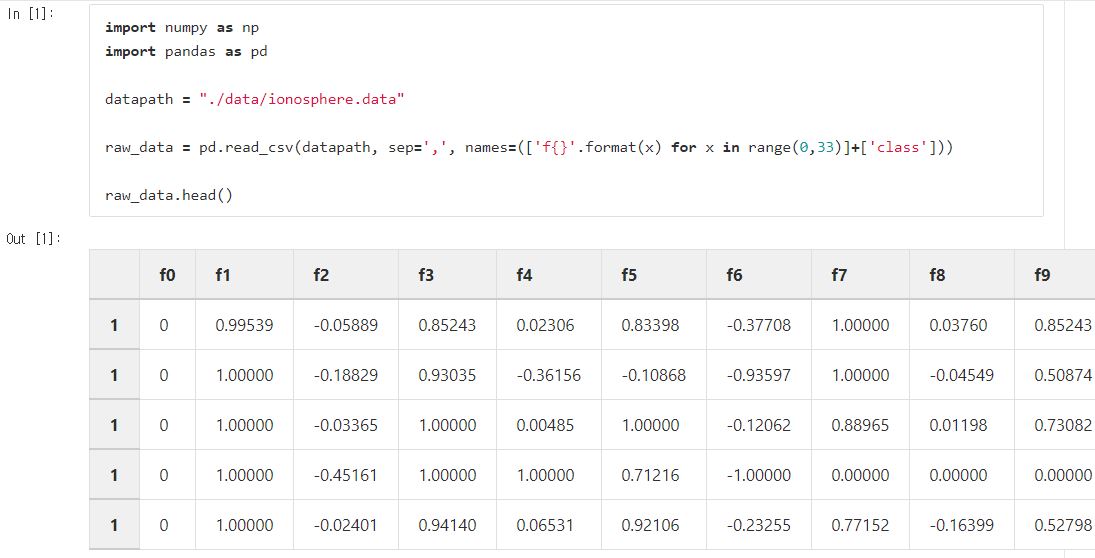
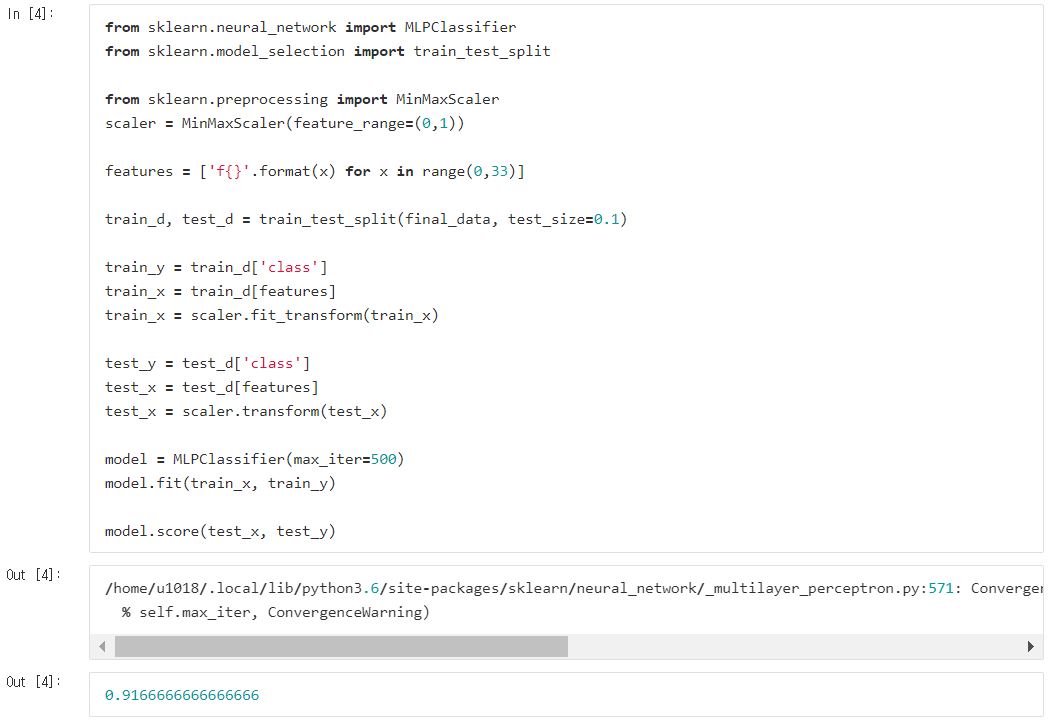
python의 list comprehension을 이용하여 열의 이름을 f0~fn까지 두고 마지막 레이블 열을 class라고 명명해주었습니다.
이후 레이블인코더를 통해 레이블을 0과 1로 바꿔주었습니다.

ANN(=MLP) 모델을 통해 학습시킨 뒤 성능을 측정해줍니다.
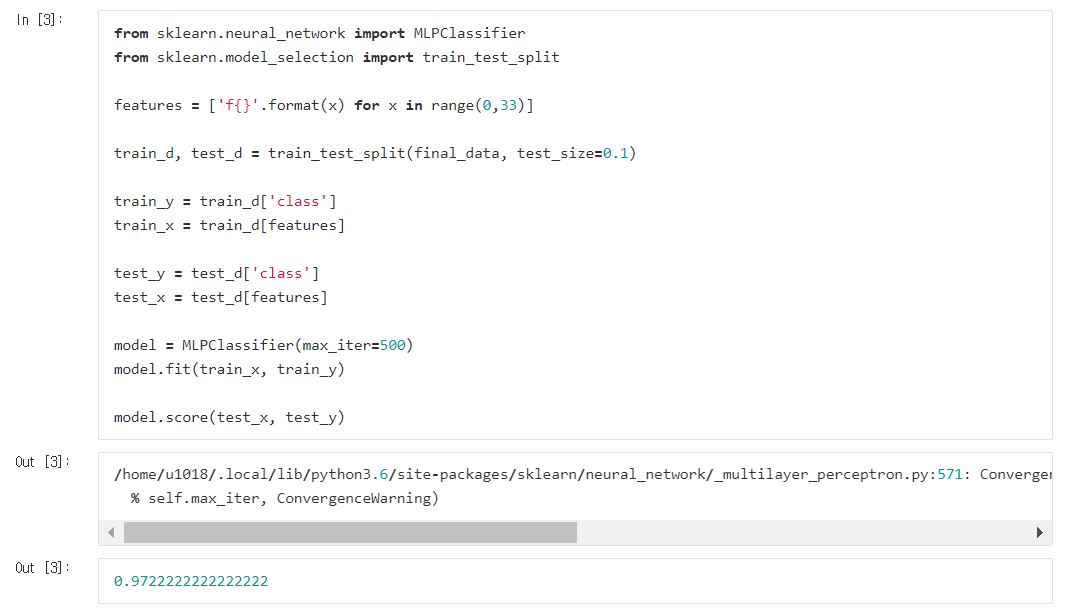
97퍼센트나 나왔네요!
이번 실습도 마찬가지로 계속 바뀝니다.
데이터가 셔플(default True)되어 번번히 새로운 학습데이터를 이용하게 되므로 성능이 매번 다르게 나오기도 하겠지만, 데이터를 고정시키더라도 모델 파라미터 초기값을 랜덤으로 설정해주기 때문에 다른 결과를 얻게 되는 것입니다.
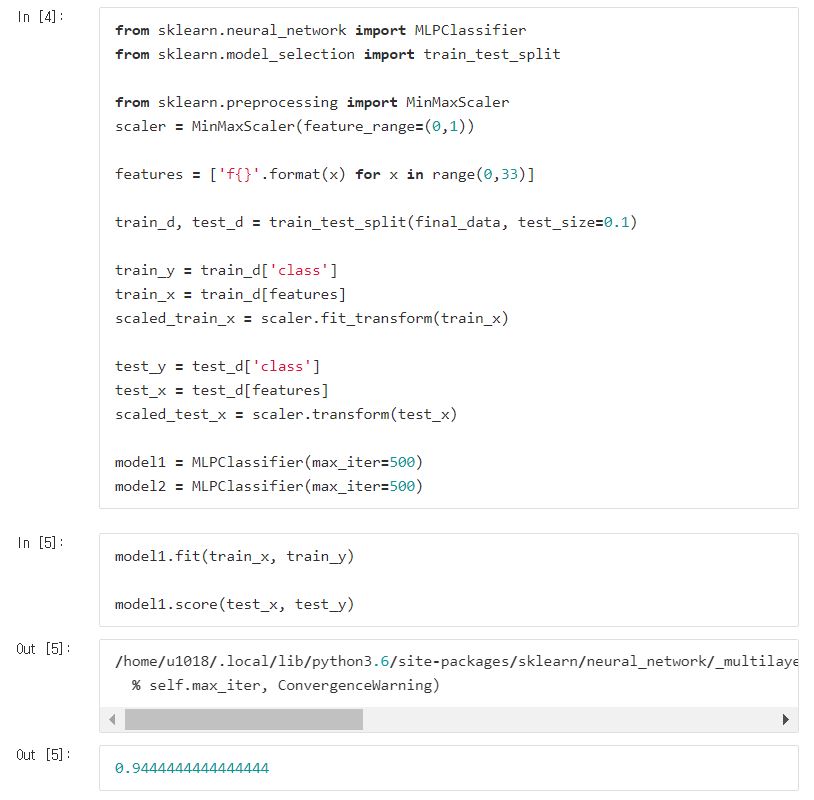
normalization을 적용해봅니다.
0에서 1사이의 값을 갖도록 feature scaling을 진행해주었습니다!
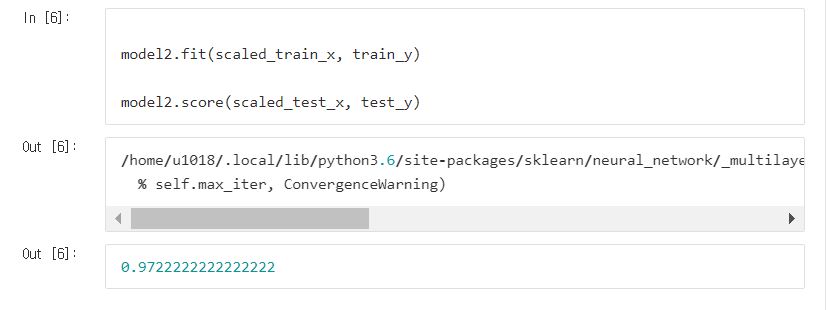
지금 실습에서는 서로 다른 데이터들을 가지고 평가했으니 줄어들었다고 오해하실 수도 있을테니 다시 테스트를 해보겠습니다.
스케일링된 데이터와 스케일링 되지 않은 데이터를 가지고 평가했을 때보면 확실히 normalize 된 데이터로 학습시켰을 때가 성능이 더 높네요!
위 실습 내용은 모두 깃랩에 푸시 해두었습니다.
실습 마지막 부분, Minmaxscaler를 통해 노말라이즈해주는 부분에서 주의할 것이 있습니다.
Fit_transform했던 위치와 transform 했던 위치를 잘봐주세요.
실습시에 이미 이야기했긴했지만 Fit_transform()은 학습도 하고 학습된걸기준으로 변환도 해주는거거든요?
0~1사이로 만들어주는거잖아요?
상한선과 하한선을 만들어야 변환이 가능해지겠죠,
그 상한선 하한선을 구하는 과정을 스케일러입장에서는 학습이라고 부릅니다
스케일러 입장에서는 fit 함수에 의해 인자로 들어온 애를 가지고 상한 하한을 두는거고요
Transform()으로 호출하는 경우는 앞서 만들어놓았던 fit 함수에의해 작업된 상한 하한선을 기준으로 변환만해주는거지요.
그게 핵심입니다.
test에서는 fit안하고 transform만해주는 것 말이죠.
왜냐면 바로 test이기 때문이죠.
Test 데이터는 unseen 데이터여야 하잖아요.
학습데이터를 기반으로 성능을 평가해야하기 때문인거지요.
Test 데이터의 상한하한선까지 신경을 써서는 절대 안됩니다.
개인이 공부하고 포스팅하는 블로그입니다. 작성한 글 중 오류나 틀린 부분이 있을 경우 과감한 지적 환영합니다!