
monitoring Spark Applications-Understading BigData(15)
Intro
학교 수강과목에서 학습한 내용을 복습하는 용도의 포스트입니다.
빅데이터 개념과 오픈소스인 아파치 하둡과 맵리듀스 및 스파크를 이용한 빅데이터 적용을 공부합니다.
맵 리듀스의 경우 사용하기에 다소 진입장벽이 있는편입니다.
스파크처럼 통합 환경을 제공하지 않아 원하는 유틸리티나 라이브러리를 별도로 연결해서 사용해야하기 때문입니다. 이를 해소하는 것이 스파크라는 분산 데이터 처리 통합 엔진입니다.
따라서 맵 리듀스로 먼저 공부해보고, 스파크로 넘어갑니다.
스파크 엔진의 경우 Java가 아닌 Scalar라는 언어로 사용하며, 기존 우리가 알고 있는 SQL을 통해 고급 질의가 가능하며, 시각화나 스트림 처리 및 기계학습등 까지의 높은 수준의 분석을 제공하는 통합 프레임 워크입니다.
빅데이터 컴퓨팅(분산시스템상의 분산처리 환경)의 기본 개념과 원리를 이해하고 이를 실습해보는 과정에서 2대 이상의 리눅스 클러스터 서버를 구축 및 활용할 것입니다.
빅데이터이해(1) 보러가기
빅데이터이해(2) 보러가기
빅데이터이해(3) 보러가기
빅데이터이해(4) 보러가기
빅데이터이해(5) 보러가기
빅데이터이해(6) 보러가기
빅데이터이해(7) 보러가기
빅데이터이해(8) 보러가기
빅데이터이해(9) 보러가기
빅데이터이해(10) 보러가기
빅데이터이해(11) 보러가기
빅데이터이해(12) 보러가기
빅데이터이해(13) 보러가기
빅데이터이해(14) 보러가기
이번 시간에는 지난 시간에 이어서 스파크 응용 모니터링에 대해 배웁니다.
job을 실행하는 과정을 웹 상에서 모니터링하는 과정을 학습할건데요, 그 원리를 이해할 필요가 있으므로 아래와 같은 순서대로 배워보겠습니다.
- 스파크 실행 모델
- 스파크 웹 모니터링
- 스파크 응용 디버그 및 튜닝
스파크 실행 모델
머넞 스파크가 실행하는 단계 및 각 실행 시에 주요 컴포넌트 즉 구성 요소에 대한 내용을 소개하겠습니다.
기본적으로 스파크의 가장 하부구조에 있는 RDD(Resillient Distributed Dataset)라는 API를 통해서 실행되게 됩니다. 가장 기본적인 빌딩 블록으로 분산 객체 컬렉션이지요.
RDD는 그 이름을 해석하면 탄력성있는 분산 데이터셋을 말하는데요, 병렬로 처리할 수 있는 파티셔닝된 레코드의 컬렉션입니다.
이 때 레코드라함은 java, scala, python 등의 객체를 일컫는 말입니다.
우리는 실습할 때 데이터세트나 데이터프레임을 이용하여 연산해왔지만, 그들의 연산에 있어서도 하부 구조의 RDD를 사용하며 계산이 실질적으로 이루어집니다.
여러 대의 컴퓨터 각각을 클러스터 노드라고 하는데, 한 노드에서 실행되는 단위(stage)를 RDD라고 할 수 있습니다.
태스크(Task)
실행의 가장 아래 단위는 Task라고 부르게 됩니다.
분할된 데이터 단위 즉 파티션에 적용되는 연산을 태스크라고 부르는 것입니다.
그런데 현재 컴퓨터들 대부분은 멀티 코어 시스템이므로 정확하게 말하면 파티션은 클러스터의 코어에서 병렬 실행되는 데이터 단위입니다.
하나의 컴퓨터(노드)에도 여러개의 파티션이 존재할 수 있습니다.
지난 시간 배웠던 대로 이어서 이해하자면 spark-submit을 통해 앱이 제출되면 클러스터매니저에 의해 실행자에서 실행할 데이터 블록과 다수의 변환 등이 할당되는데 이들 조합이 바로 task입니다.
스테이지(Stage)
스테이지란 다수의 노드에서 병렬로 동일한 연산을 수행하는 태스크들의 그룹을 말합니다.
한 스테이지는 하나의 RDD라고 볼 수 있습니다.
RDD는 앞서 말했듯이 객체이므로 연산과 데이터의 조합입니다.
단 여기서 말하는 RDD는 파이프라이닝으로 통합되기 전의 RDD입니다.
잡(Job)
잡은 RDD를 계산하는데 필요한 작업을 말하며, 특정 액션을 수행하는 스테이지들의 집합입니다.
일반적으로 액션 당 하나의 잡이 생성되게 됩니다.
셔플(shuffle)
스테이지들 간의 네트워크를 통한 데이터 전달이 이루어지는 것을 개념적으로 말하는 것이 바로 셔플입니다.
파이프라이닝(pipelining)
노드 간의 데이터의 이동(셔플) 없이 각 노드가 데이터를 직접 공급할 수 있는 스테이지(RDD)들을 통합하여 단일 스테이지(RDD)로 구성하는 작업을 말합니다.
DAG(Directed Acyclic Graph)
RDD 상에서 적용되는 연산을 표현한 논리적인 그래프를 말합니다.
각 스테이지는 vertex로서 표현되지요.
액션이 수행되기 전까지는 변환된 데이터들은 계보 그래프로만 나타난다고 말했는데 그 때 말한 그래프가 이 그래프입니다.
스파크 실행단계(spark Execution Phases)
-
단계 1: 논리적 계획(Logical Plan)
사용자 코드로부터 DAG를 정의합니다. -
단계 2: 물리적 실행 계획(Physical Execution Plan)
액션이 호출될 때 DAG는 물리적인 실행 계획으로 변환됩니다.
물리적 계획에서는 실행을 위한 계산 및 메모리 자원 등을 할당합니다. -
단계 3: 스케줄(Schedule)
태스크들은 클러스터 상에 스케줄되고 실행됩니다.
스테이지들은 순서대로 실행되며 잡(액션 단계까지를 job이라고 부름)의 최종 스테이지가 종료될 때 액션은 완료됩니다.
SFPD 데이터세트 연산을 예로 들어 한 번 더 살펴봅시다.
sfpdDS.groupBy(“category”) 변환을 적용한 관계형 그룹 데이터세트를 categoryDS라고 하고 이에 대한 count 액션을 수행하는 과정을 예로 들어봅시다.
sfpd 예의 논리적 계획을 볼 것입니다.
sfpd 예의 사용자 프로그램이 물리적인 실행 단위로 변환되는 모델을 소개합니다.

sfpd 예의 논리적 계획 첫번째 데이터 적재입니다.
sfpd.csv 파일로 부터 sfpdDS를 생성합니다.
두번째 계획은 groupBy 변환입니다.
category 열의 값에 따라 그룹화하여 categoryDS 관계형 그룹 데이터세트를 생성합니다.
groupBy하는 과정에서 셔플이 일어나게 됩니다.
세번째 계획은 count 변환입니다.
count 액션을 수행하는데, 해당 연산은 변환으로 취급되어 categoryCount라는 새로운 데이터세트를 생성하게됩니다.
따라서 실질적으로는 아직 어떤 액션도 수행되지 않습니다.
이 때 데이터세트 객체들의 DAG가 정의되는데요, 각 데이터 세트는 각각 부모의 데이터세트들을 가리키는 포인터를 유지합니다.
마지막 계획은 collect 액션입니다.
collect 액션이 실행되면 실제 계산을 수행합니다.
스파크 스케줄러가 데이터세트를 계산하는 물리적인 실행 계획을 생성하며 이 때 모든 부모 데이터세트들의 물리적 계획도 생성하게 됩니다.
물론 순서대로 실행됩니다.
그 다음으로 물리적인 실행 계획을 살펴봅니다.
액션이 호출될 때 DAG는 물리적 계획으로 변환합니다.
스케줄러는 필요한 데이터 세트를 계산하는 각 액션 당 job을 제출합니다.
job은 하나 이상의 스테이지들로 구성되고, 스테이지는 파티션 상에 병렬로 실행되는 태스크들로 구성됩니다.
태스크들이 모여 스테이지를 이루고 스테이지들이 모여서 하나의 잡이되지요.
각 스테이지들은 순서대로 처리되어 각 태스크가 스케줄되고, 클러스터 상에서 실행됩니다.
물리적 실행 계획 첫 번째, 스테이지와 태스크입니다.
스테이지는 데이터 세트의 RDD의 각 파티션에 대한 태스크를 가집니다.
스테이지는 특정 파티션의 데이터 상에서 같은 일을 하는 태스크를 수행합니다.
일반적으로 스테이지 수는 DAG의 RDD에 기반한 데이터세트의 수와 일치합니다.
각 태스크는 아래의 공통 단계를 수행합니다.
- 데이터 저장소 또는 기존 데이터세트로부터 입력과 셔플의 결과를 읽어들입니다.
- 필요한 데이터세트를 계산하기 위해 필요한 변환과 액션을 수행합니다.
- 셔플, 외부 저장소, 드라이버(ex) count, collect) 등으로 출력됩니다.
예를 들어 스테이지 1에서는 데이터를 적재하고, 베이스 데이터 세트를 생성한다고 합시다.
스테이지 내의 모든 태스크들은 같은 일을 수행합니다.
4개의 태스크들이 각각 3개의 스텝을 병렬 실행합니다.
스텝 1은 데이터를 읽고, 스텝 2에서 map과 filter 변환을 수행하고, 스텝 3에서 셔플하기 위해 출력합니다.
스테이지 2에서도 각 태스크들이 셔플된 후 연산이 이루어지며 최종 출력되게 됩니다.
스파크 웹 모니터링
스파크 웹 UI는 스파크 작업(job)의 진행과 성능에 관한 정보를 제공하고 있습니다.
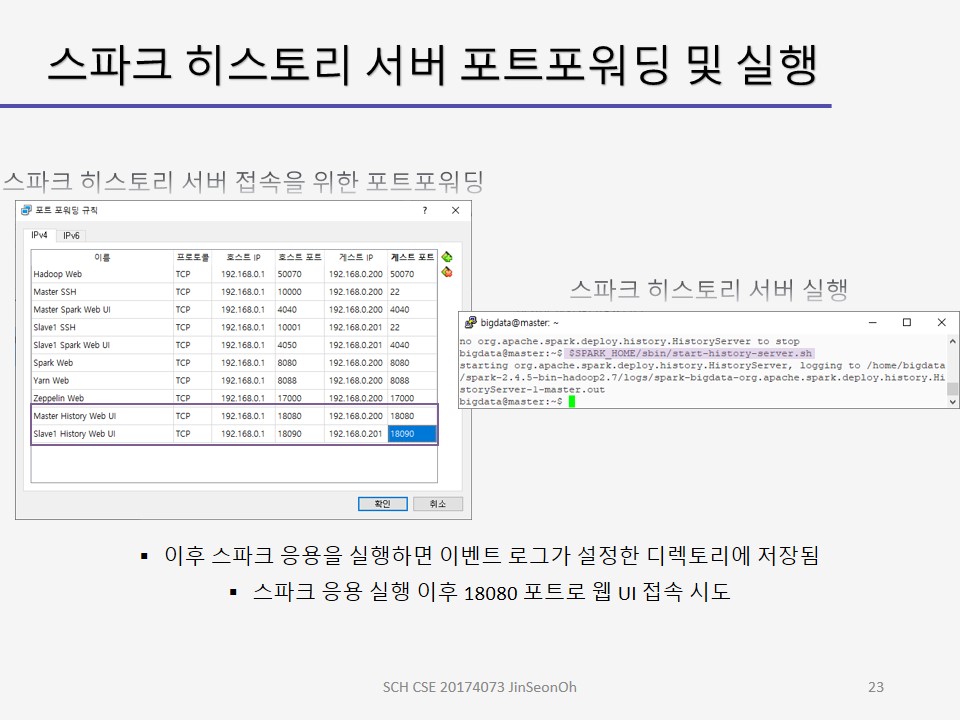
디폴트로 드라이버의 4040 포트를 통해 실행 중인 응용의 정보를 표시합니다.
같은 호스트에 여러 개의 SparkSession이 실행 중이면 4040, 4041, 4042 등의 연속적인 포트로 표시됩니다.
하둡 YARN 클러스터인 경우 YARN 자원 관리자 8088 포트를 통해 접근도 가능합니다.
둘 중 하나를 통해 살펴 볼수 있습니다.
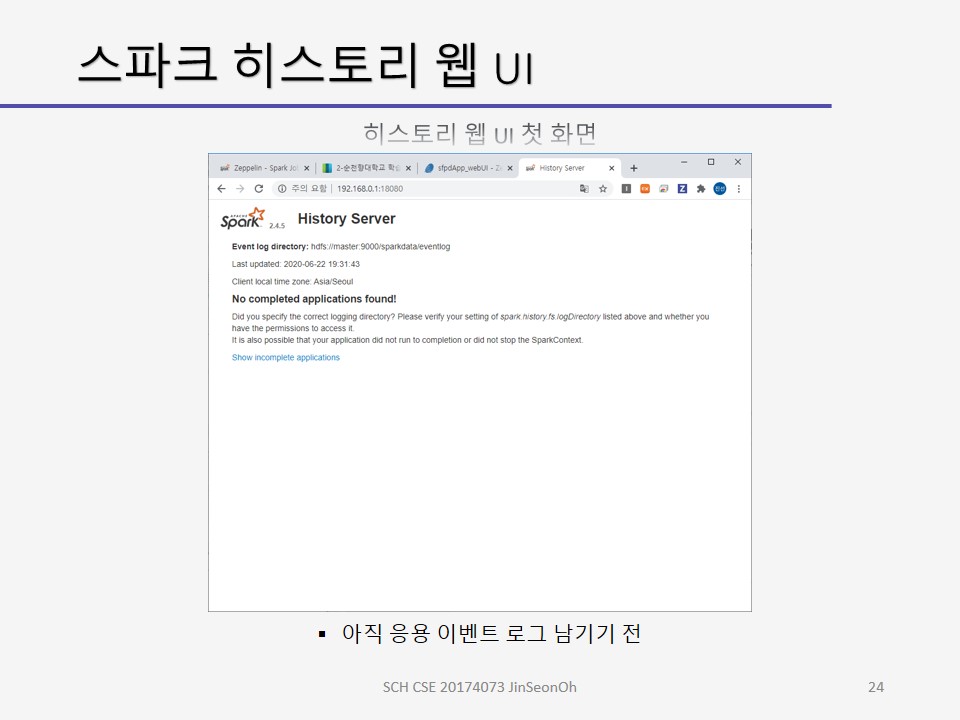
이 글에서는 스파크 웹 UI를 통해 모니터링 하는 예를 살펴볼 것입니다.
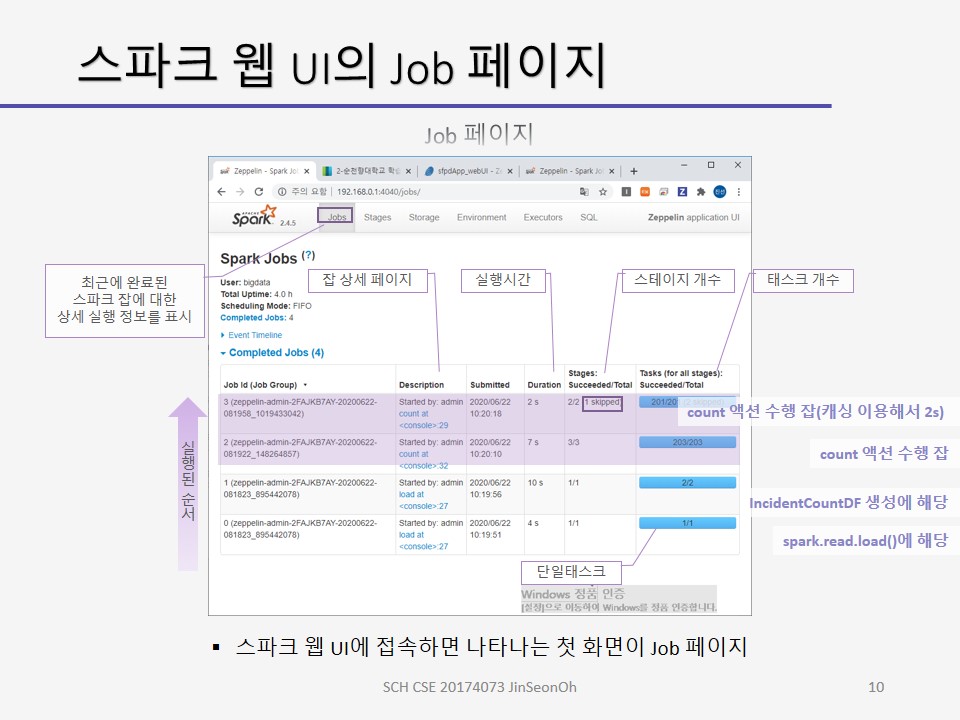
스파크 웹 UI에 접속하면 나타는 화면이 Job 페이지입니다.
잡페이지는 최근에 완료된 스파크 잡에 대한 상세 실행 정보를 표시합니다.
Job ID 0은 처음 실행된 잡을 말하며 첫번째 코드의 spark.read.load 메소드에 해당합니다.
stage/total 항에 1/1이라고 써있으면 단일 태스크를 말합니다.
Job ID 1은 IncidentCountDF 생성에 해당하며, Job ID 2는 collect 액션에 해당합니다.
collect 액션의 경우 2개의 스테이지, 201개의 태스크로 구성되었다는 것을 알 수 있으며 실행 시간은 12초 소요되었다고 기록되어있습니다.
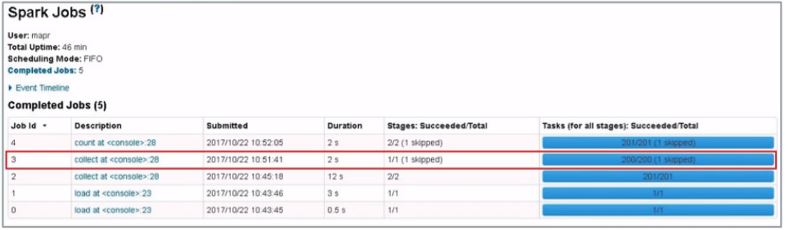
Job ID 4는 count 액션에 해당합니다.
2개의 스테이지, 201개의 태스크들로 구성되며, 실행 시간은 캐싱된 데이터프레임을 사용했기 때문에 2초만 소요된 것으로 확인되었습니다.
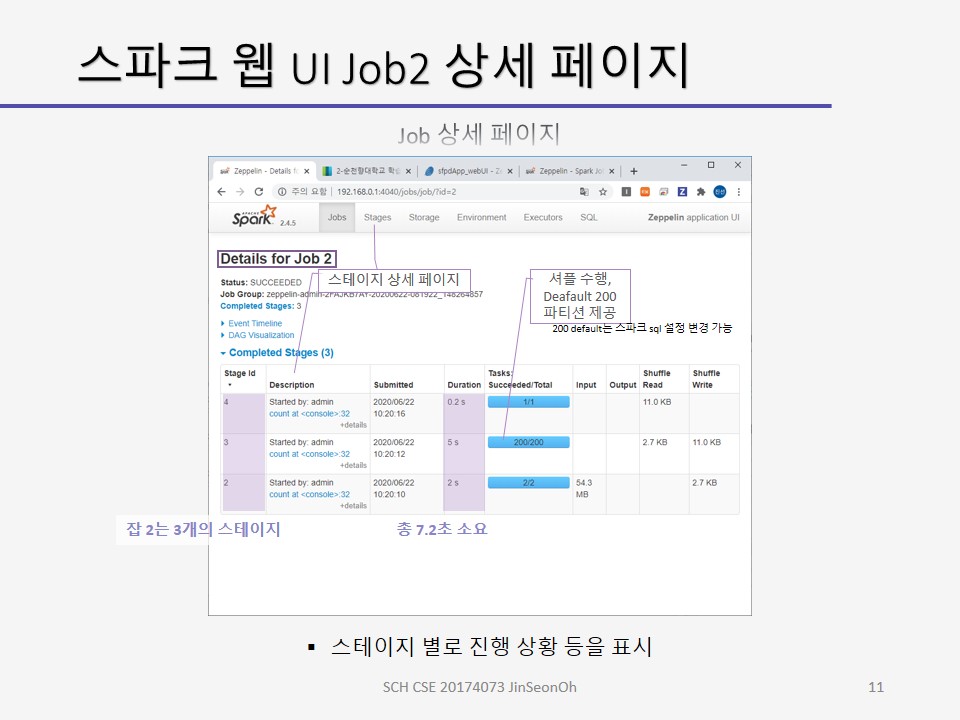
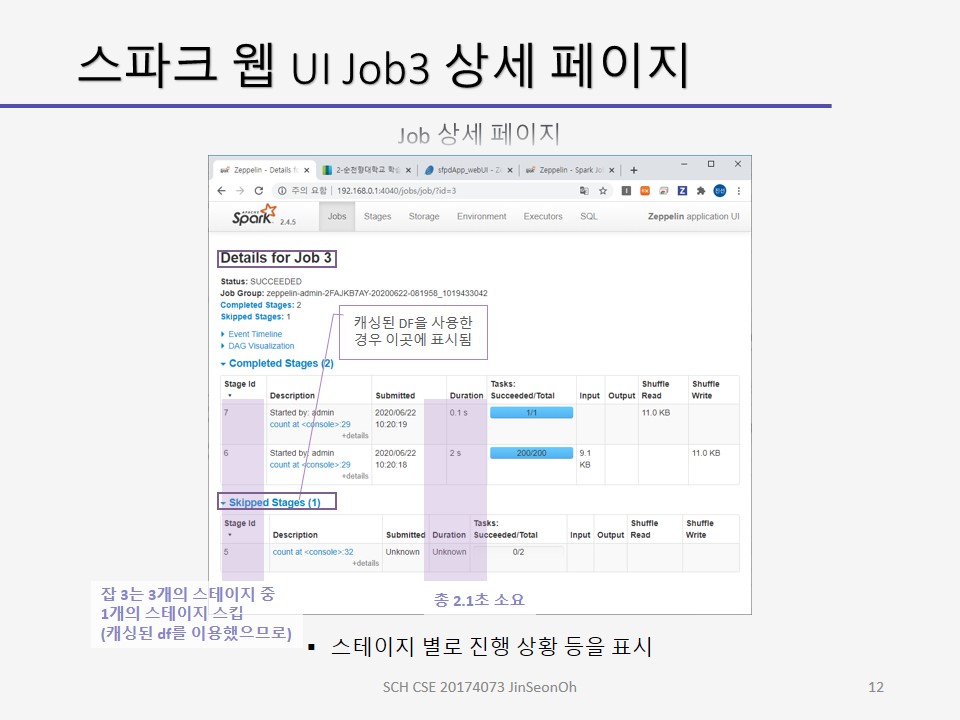
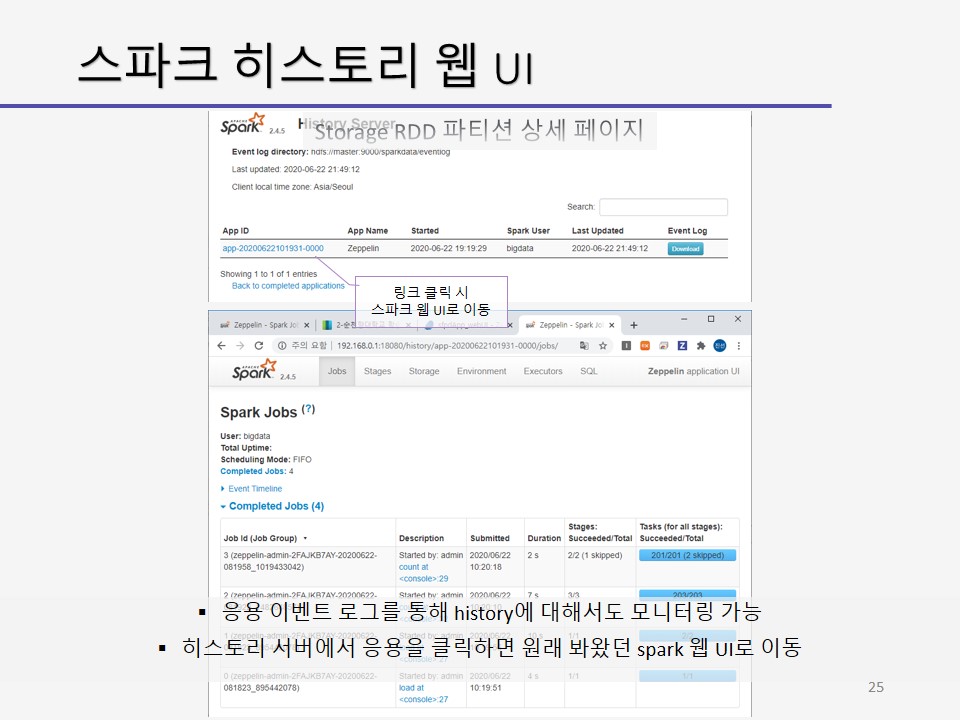
잡 페이지에서 Description 열의 링크를 누르면 잡 상세 페이지(Job Details)가 표시됩니다.
상세 페이지에서는 잡의 스테이지 별로 진행 상황 등을 표시합니다.
skipped stages 는 캐싱된 데이터프레임을 사용한 경우등이 이 곳에 표시됩니다.
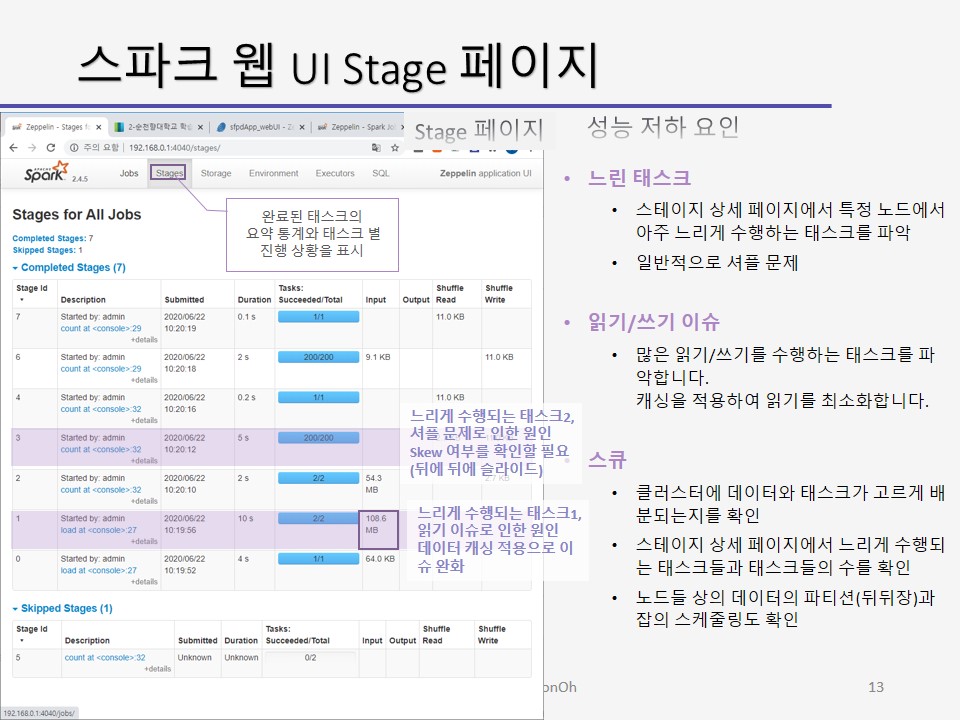
잡 상세 페이지에서 Description 열의 링크를 누르면 스테이지 상세 페이지가 표시됩니다.
또는 메인 페이지에서 stages 메뉴로도 표시되고 있습니다.
스테이지의 완료된 태스크의 요약 통계와 태스크 별로 진행 상황을 표시합니다.
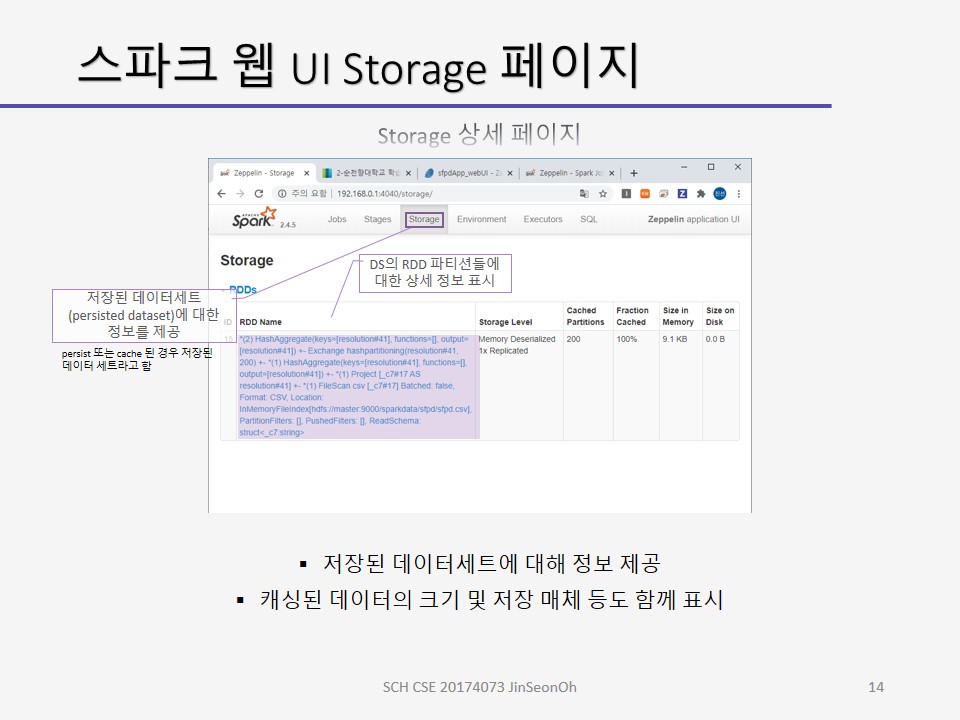
스토리지 페이지는 저장된 데이터세트(persisted dataset)에 대한 정보를 제공합니다.
persist 또는 cache 된 경우 저장된 데이터 세트라고 합니다.
캐싱된 데이터의 크기 및 저장 매체등도 함께 표시됩니다.
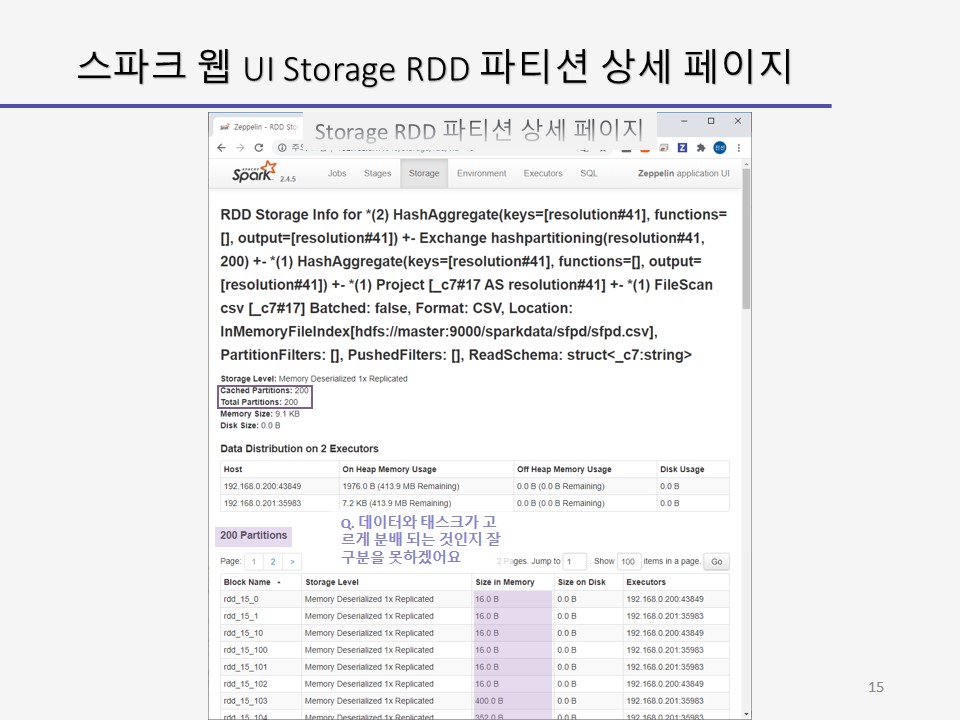
스토리지 페이지에서 RDD Name 열을 클릭하면 데이터 세트의 RDD 파티션들에 대한 상세 정보들이 표시 됩니다.
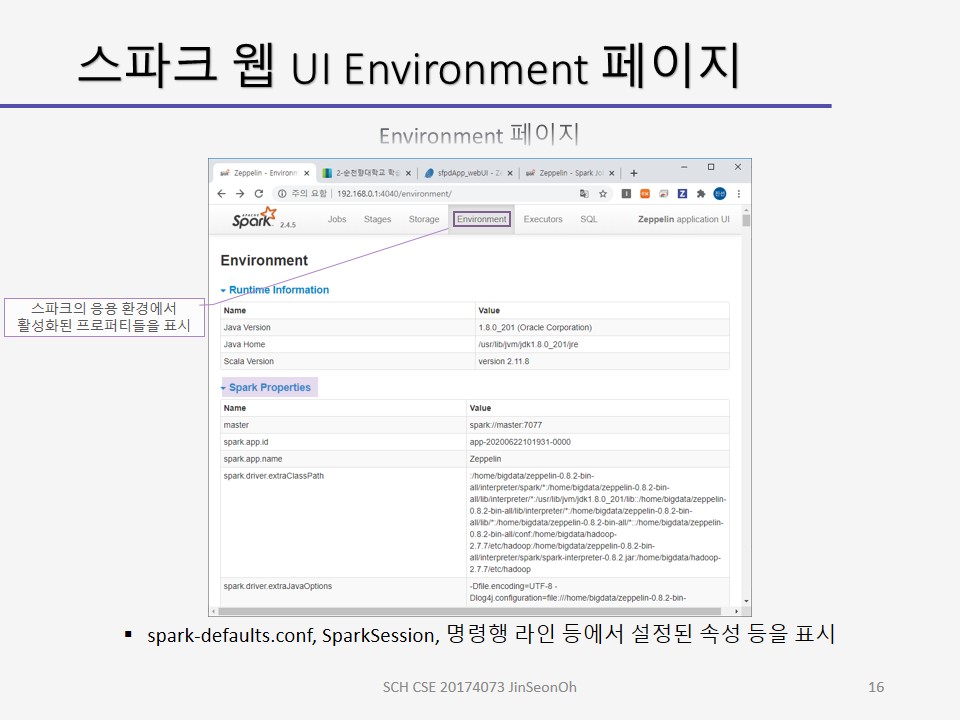
환경 페이지는 스파크의 응용 환경에서 활성화된 프로퍼티들을 표시합니다.
spark-defaults.conf, SparkSession, 명령행 라인 등에서 설정된 속성 등을 표시합니다.
참고) 스파크 설정 방법은 아래와 같습니다.
- Spark-shell/spark-submit의 명령행으로 설정하기
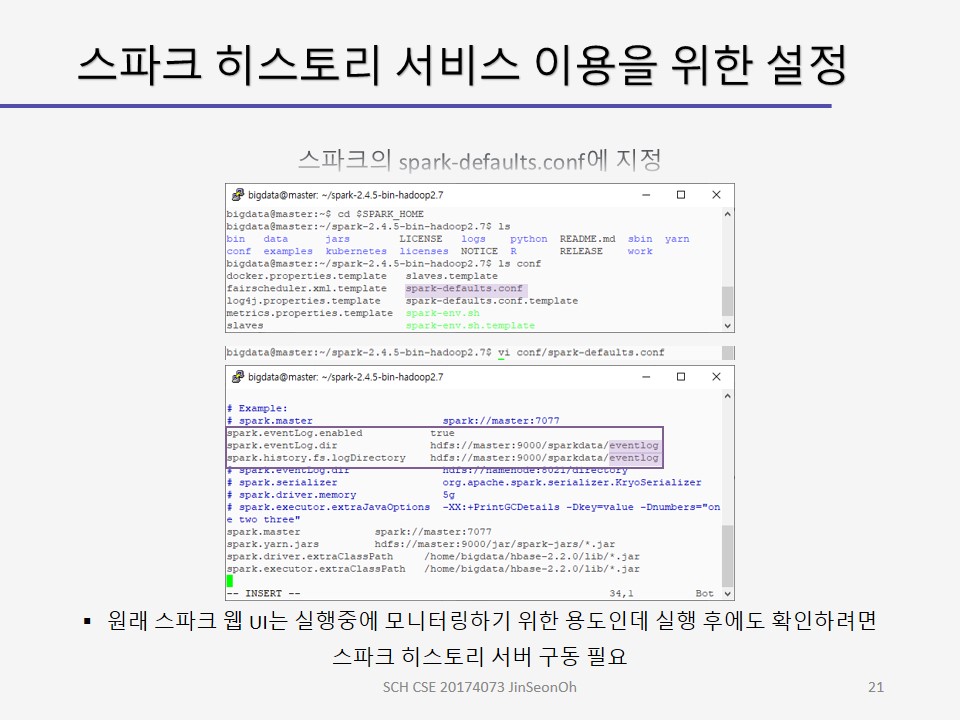
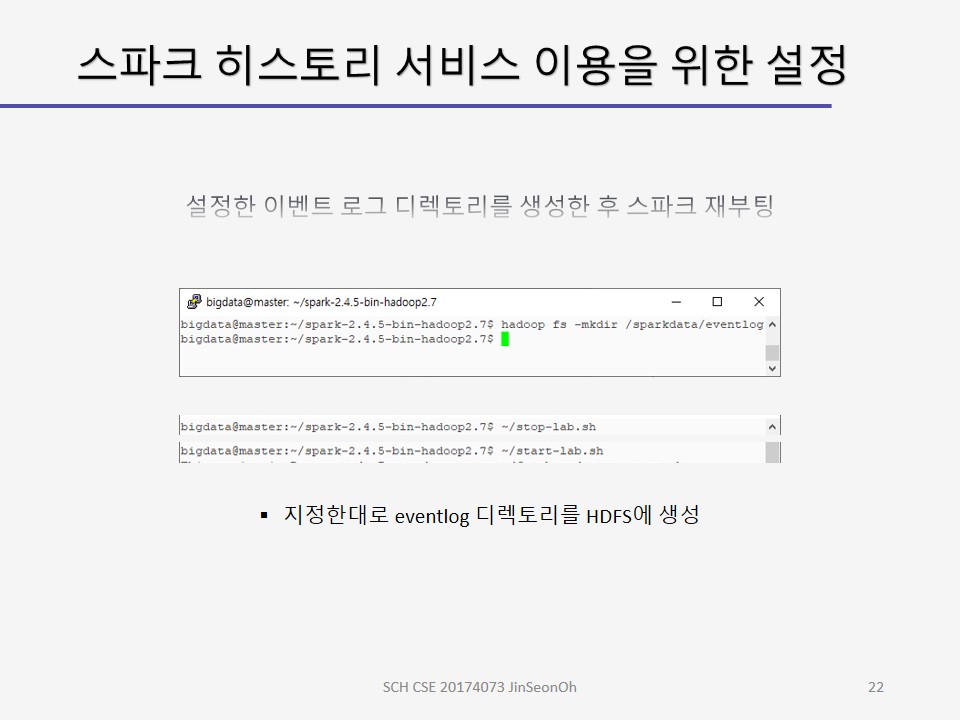
$SPARK_HOME/bin/spark-shell --master yarn --conf "spark.eventLog.enabled=true" --conf "spark.eventLog.dir=hdfs://master:9000/sparkdata/history" - 스파크의 spark-defaults.conf 에 지정하기
spark.eventLog.enabeld true spark.eventLog.dir hdfs://master:9000/sparkdata/history - 프로그램 상에서 SparkSession을 생성하도록 지정하기
val spark = SparkSession.builder.appName("sfpdApp").config(" spark.eventLog.enabled","true").getOrCreate()
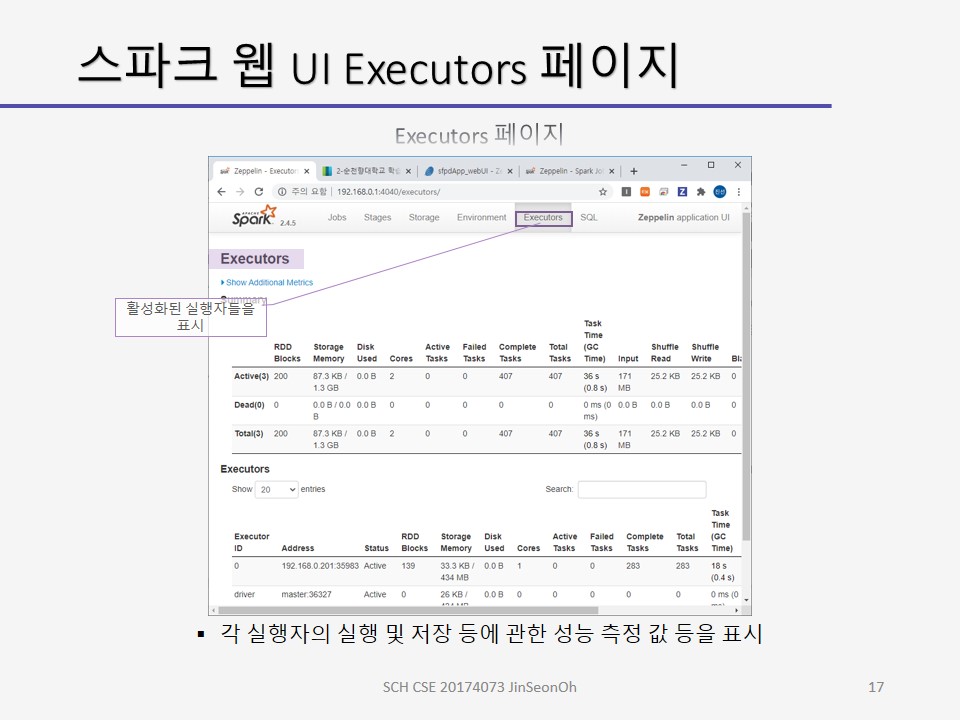
실행자 페이지는 활성화된 실행자들을 표시합니다.
각 실행자의 실행 및 저장 등에 관한 성능 측정값등을 표시합니다.
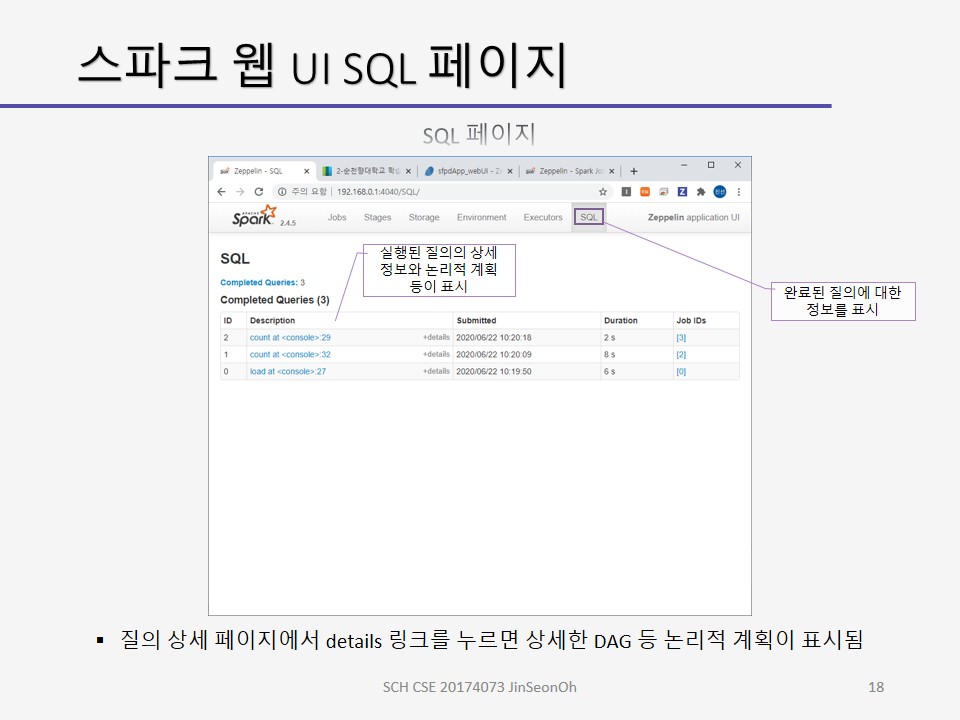
SQL 페이지는 완료된 질의에 대한 정보를 표시합니다.
description 열을 누면 실행된 질의의 상세 정보와 논리적 계획 등이 표시됩니다.
질의 상세 페이지에서 details 링크를 누르면 상세한 논리적 계획이 표시됩니다.
스파크 응용 디버그 및 튜닝
스파크를 이용하는데 성능 저하 문제에 봉착하게 된다면 아래 와 같이 해결해볼 수 있습니다.
우선 다른 태스크들 보다도 수행시간이 길어서 데이터 병렬 처리의 성능에 문제가 되는 소스 태스크를 스큐(왜곡,skew)라고 부릅니다.
우리는 스파크 웹 UI를 사용하여 스큐를 모니터링합니다.
스테이지 상세 페이지에서 다른 태스크보다 긴 수행 시간을 갖는 태스크를 조사하고 다른 태스크들보다 더 많은 데이터를 읽거나 쓰는 태스크를 조사할 수도 있으며 특정 노드들 상에서 태스크 수행이 지연되는지도 확인할 수 있고, 읽기, 계산, 쓰기의 각 단계(phase)에서의 수행 시간을 조사할 수도 있습니다.
대개 병렬 처리에 문제가 있던지 셔플로 인한 네트워크에 부하가 있다던지 메모리 저하 문제가 있다던지 여러 이유가 있을 수 있습니다.
하지만 성능 저하는 다음과 같은 공통적인 이슈에 기인합니다.
- 병렬성의 수준(Level of Parallelism)
파티션의 수가 너무 많다거나 또는 너무 적다거나하는 경우일 수 있습니다. - 셔플 동작 시 사용되는 직렬화 형식(Serialization Format)
객체로 표현되었기 때문에 byte 단위로 나열해서 표현하게 될 것입니다.
특별히 설정하지 않으면 Java의 직렬화를 따르게 되는데 Java의 직렬화 성능은 좋지 않습니다.
그래서 spark에서 크라이오(Kryo)라는 오픈소스를 이용하는 등 직렬화형식을 지정할 수 있습니다. - 최적화된 메모리 관리(Memory Management)
이 세 가지 원인이 성능 저하 이슈의 대부분의 이유가 됩니다.
먼저 병렬성의 수준을 결정하는 파티션(Partition)에 대하여 정리해봅시다.
데이터 세트의 RDD는 데이터의 부분들인 파티션으로 분할되게 됩니다.
스케줄러는 각 파티션에 대해 하나의 태스크를 생성합니다.
각 태스크는 클러스터의 단일 코어 상에서 실행됩니다.
병렬성의 수준이 성능에 영향을 미친다고 했습니다.
너무 큰 병렬성을 가지면 각 파티션과 관련된 오버헤드가 커져서 잡의 실행 시간이 증가할 우려가 있습니다.
그렇다고 너무 적은 병렬성을 가지면 자원이 쉬게 됩니다.
자원이 너무 많이 또는 너무 적게 이용되지 않도록 파티션의 수를 조정할 필요가 있습니다.
그래서 병렬성의 수준을 튜닝(tuning level of parallelism)한다는 것은 결국 파티션의 수를 확인하고 조정하는 것을 말합니다.
현재 파티션의 수를 확인하는 것은 다음 메소드 중 하나를 사용하여 데이터세트의 RDD의 파티션 확인할 수 있습니다.
ds.rdd.partitions.size()
ds.rdd.getNumPartitions()
또는 스파크 웹 UI의 스테이지 페이지에서 태스크의 수를 확인할 수도 있습니다.
태스크마다 하나의 파티션을 갖기 때문에 태스크 수만 확인해도 됩니다.
파티션의 수를 조정하는 방법은 아래와 같습니다.
// 파티션 수 축소
// 너무 많은 태스크들이 쉬고 있을 경우
ds.rdd.coalesce()
// 파티션 수 증가
// 클러스터의 모든 코어를 사용하고 있지 않을 경우
ds.rdd.repartition()
셔플링 동작 시 등에서 직렬화 형식(Serialization Format)으로 인한 성능에 영향을 받을 수 도 있습니다.
셔플 동작 시 많은 양의 데이터가 네트워크 상에서 전송되는데, 스파크는 인코더가 객체들을 이진 형식으로 직렬화하여 전송하고 있습니다.
종종 직렬화 전송으로 인해 성능의 병목이 일어나기도 합니다.
스파크는 디폴트로 Java에 내장된 직렬화 방식(Java built-in serializer)를 사용합니다.
그것보다는 빠르고 효율적인 자바 직렬화 프레임워크인 Kryo 직렬화 방식이 더 효율적이므로 다운로드 받아서 설정을 변경해주면 됩니다.
다운로드 링크를 여기에 걸어놓겠습니다.
스파크의 메모리 사용 내용을 파악하면 메모리 관리(Memory management) 최적화에 도움이 될 것입니다.
스파크의 디폴트 메모리 사용처는 아래와 같습니다.
RDD 저장소에 60%, 셔플링에 20%, 사용자 프로그램에 20%입니다.
RDD 저장소, 셔플, 사용자 프로그램의 메모리 영역을 조정함으로써 메모리 사용 튜닝을 할 수 있습니다.
RDD 저장소의 경우에는 cache(), persist()를 사용하면 RDD 파티션을 메모리 버퍼에 저장할 수 있습니다.
persist()는 다양한 옵션을 가집니다.
디폴트는 persist(MEMORY_ONLY)이며 cache()와 같습니다.
만약 캐시할 메모리가 부족하면 새 RDD는 캐싱하고, 이전 RDD는 제거하고 필요하면 다시 계산하게 됩니다.
persist(MEMORY_AND_DISK)와 같은 옵션을 주게 되면 데이터를 디스크에 저장하고, 필요한 경우 메모리에 적재하여 계산을 줄일 수 있습니다.
persist(MEMORY_ONLY_SER) 옵션을 주게 되면, 직렬화된 형식으로 객체를 캐싱하므로 원본 객체 캐싱보다 더 느릴 수는 있으나 가비지 컬렉션(garbage collection)을 없애 시간을 줄일 수 있습니다.
이처럼 이슈를 잡아내고 튜닝하는 과정의 실습을 위하여 스파크 웹 UI를 활용할 것입니다.
가장 먼저 스파크 웹 UI의 잡, 스테이지를 모니터링하여 성능 저하 요인을 감지할 것입니다.
성능 저하 요인이라함은 느린 태스크, 읽기/쓰기 이슈, 스큐 등을 말합니다.
느린 태스크
스테이지 상세 페이지에서 특정 노드에서 아주 느리게 수행하는 태스크를 파악합니다.
일반적으로 셔플 문제로 인해 느리게 수행되곤 합니다.
읽기/쓰기 이슈
많은 읽기/쓰기를 수행하는 태스크를 파악합니다.
캐싱을 적용하여 읽기를 최소화합니다.
스큐
클러스터에 데이터와 태스크가 고르게 배분되는지를 확인합니다.
스테이지 상세 페이지에서 느리게 수행되는 태스크들과 태스크들의 수를 확인합니다.
노드들 상의 데이터의 파티션과 잡의 스케줄링도 확인합니다.
스파크의 로깅시스템은 log4j에 기반하고 있습니다.
log4j는 자바 기반의 로깅 유틸리티입니다.
참고 url
로킹 레벨이나 출력을 조정할 수 있으며 log4j 설정 예는 스파크 conf 디렉토리에 제공되고 있습니다.
로그 파일들의 위치는 아래와 같이 배포 모드에 따라 다릅니다.

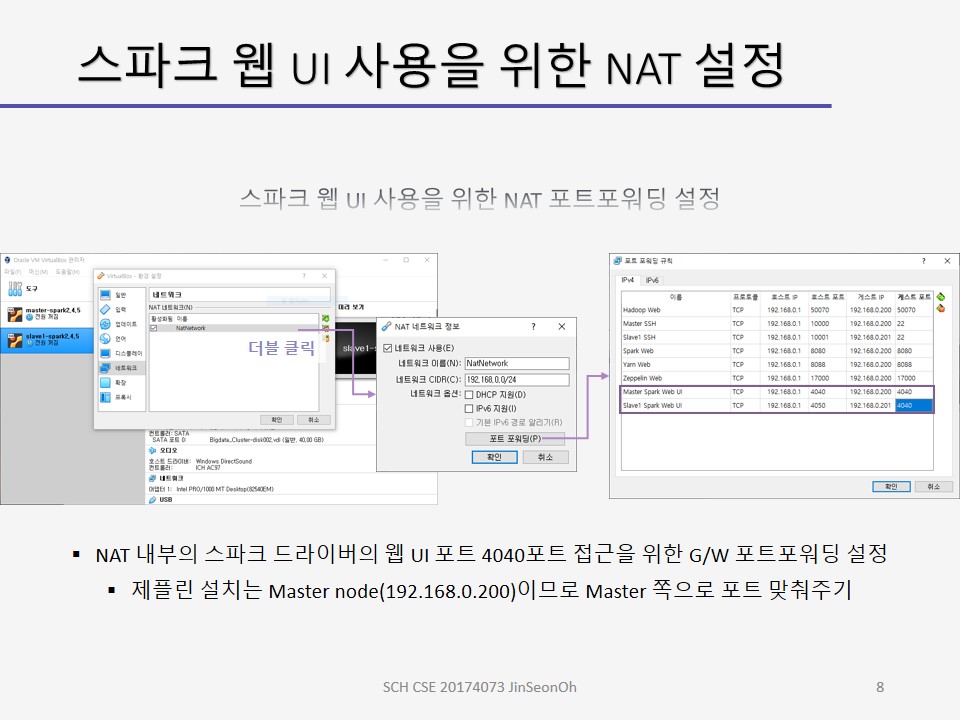
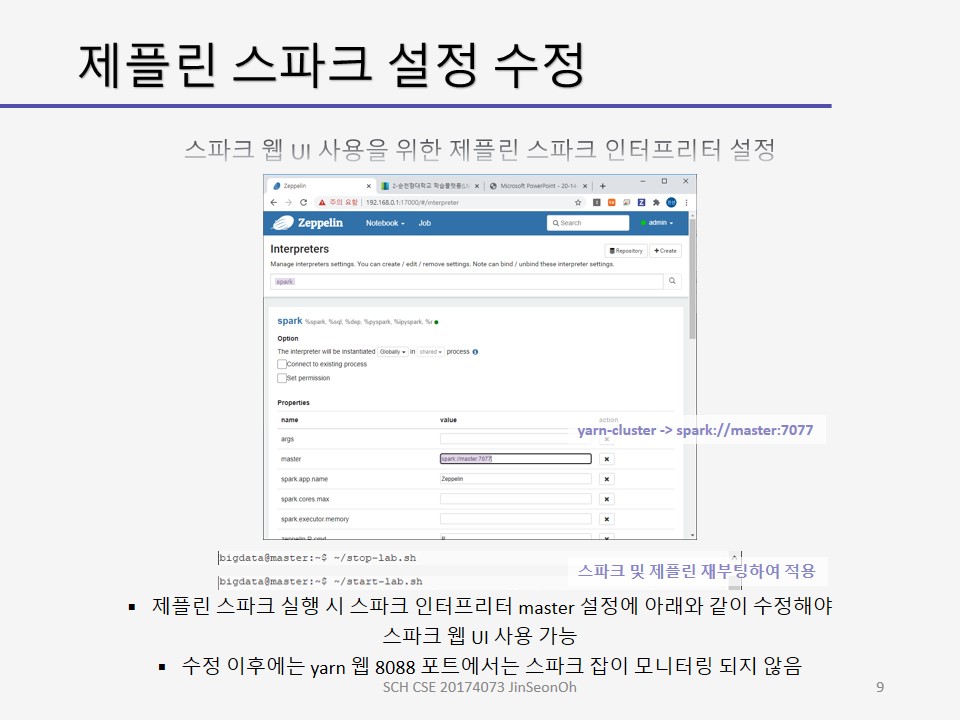
제플린 상에서 실습해보고 스파크 웹 UI를 통해 모니터링 하는 내용에 대한 캡처를 아래에 올려두겠습니다.


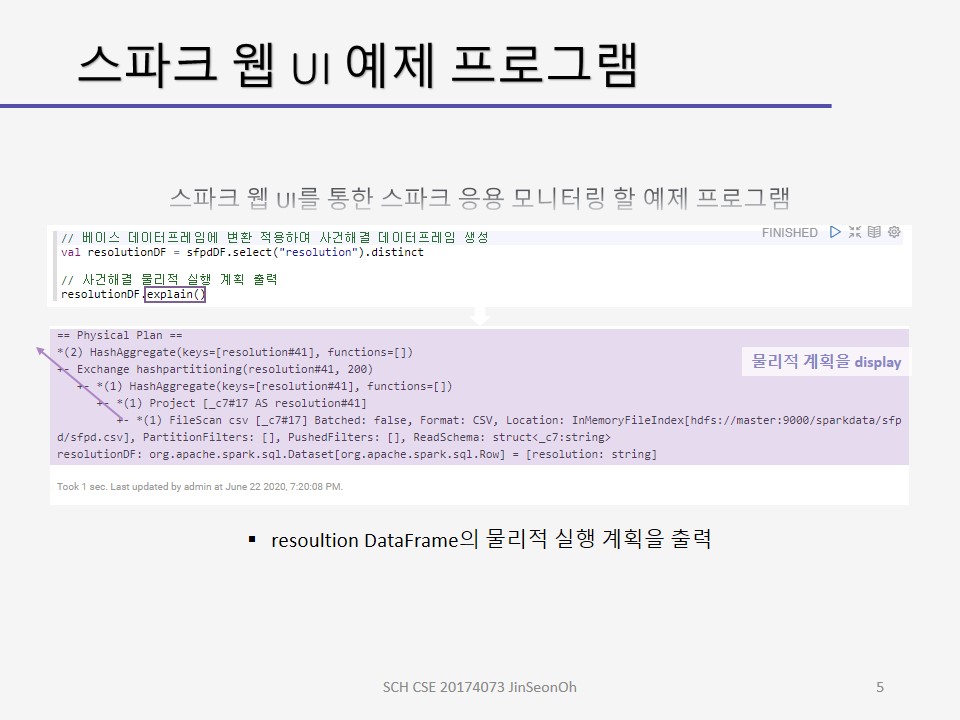
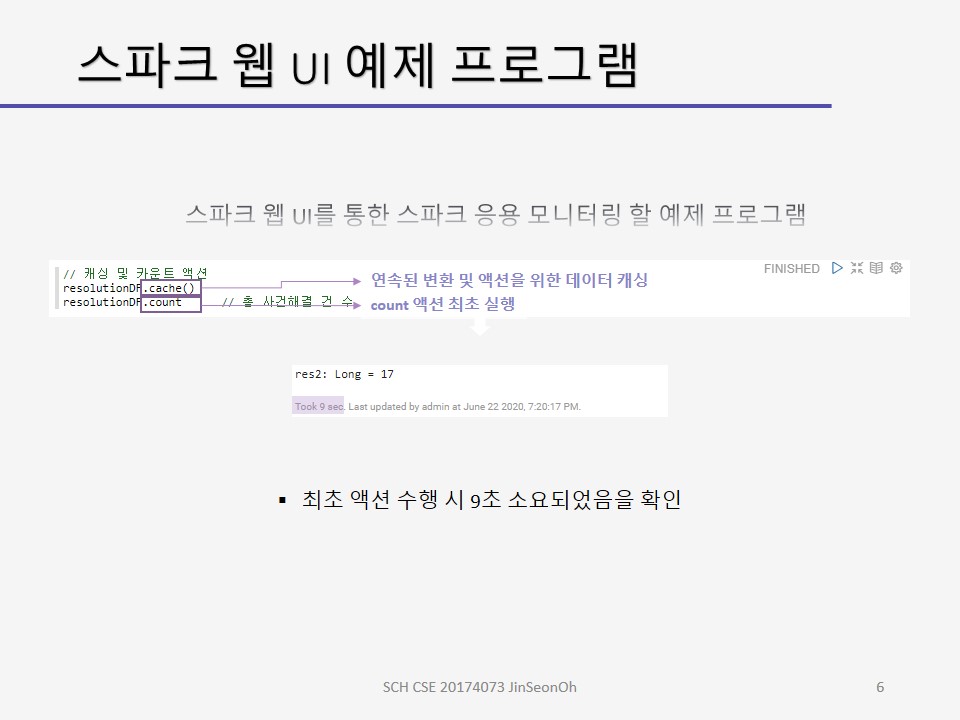
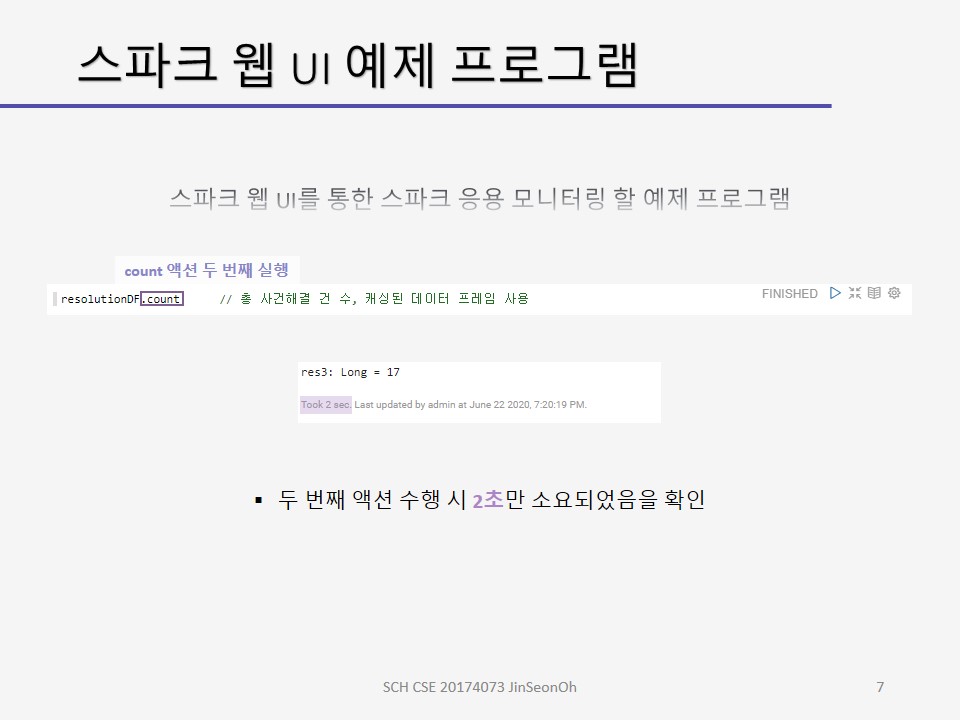


개인이 공부하고 포스팅하는 블로그입니다. 작성한 글 중 오류나 틀린 부분이 있을 경우 과감한 지적 환영합니다!