
Spark MLib-Understading BigData(17)
Intro
학교 수강과목에서 학습한 내용을 복습하는 용도의 포스트입니다.
빅데이터 개념과 오픈소스인 아파치 하둡과 맵리듀스 및 스파크를 이용한 빅데이터 적용을 공부합니다.
맵 리듀스의 경우 사용하기에 다소 진입장벽이 있는편입니다.
스파크처럼 통합 환경을 제공하지 않아 원하는 유틸리티나 라이브러리를 별도로 연결해서 사용해야하기 때문입니다. 이를 해소하는 것이 스파크라는 분산 데이터 처리 통합 엔진입니다.
따라서 맵 리듀스로 먼저 공부해보고, 스파크로 넘어갑니다.
스파크 엔진의 경우 Java가 아닌 Scalar라는 언어로 사용하며, 기존 우리가 알고 있는 SQL을 통해 고급 질의가 가능하며, 시각화나 스트림 처리 및 기계학습등 까지의 높은 수준의 분석을 제공하는 통합 프레임 워크입니다.
빅데이터 컴퓨팅(분산시스템상의 분산처리 환경)의 기본 개념과 원리를 이해하고 이를 실습해보는 과정에서 2대 이상의 리눅스 클러스터 서버를 구축 및 활용할 것입니다.
빅데이터이해(1) 보러가기
빅데이터이해(2) 보러가기
빅데이터이해(3) 보러가기
빅데이터이해(4) 보러가기
빅데이터이해(5) 보러가기
빅데이터이해(6) 보러가기
빅데이터이해(7) 보러가기
빅데이터이해(8) 보러가기
빅데이터이해(9) 보러가기
빅데이터이해(10) 보러가기
빅데이터이해(11) 보러가기
빅데이터이해(12) 보러가기
빅데이터이해(13) 보러가기
빅데이터이해(14) 보러가기
빅데이터이해(15) 보러가기
빅데이터이해(16) 보러가기
이번 시간에는 스파크 머신러닝 라이브러리에 대해 학습합니다.
MLib 개요에 대해 학습하고, 머신러닝 분류, 클러스터링, 협업 필터링을 소개하며 협업 필터링 실습도 함께 다뤄보겠습니다.
MLib
MLib는 스파크 머신러닝 라이브러리로 클러스터 상에서 병렬로 실행되는 머신러닝 알고리즘을 제공합니다.
파티션된 데이터에 대해 학습하고 스파크에서 학습된 결과를 가지고 분석하고 사용할 수 있습니다.
기본적인 구조로는 하둡분산파일 시스템에 데이터 소스가 있으며 spark core, dataframe api, mlib까지 계층을 이루고 있는 아키텍처를 이해할 필요가 있습니다.
MLib에서는 고전적인 머신러닝을 다루고 있습니다.
기본적인 통계, 분류 및 회귀 문제, 협업필터링, 클러스터링 차원축소, 특징 추출 및 변형 등의 알고리즘을 제공합니다.
기본 통계
평균, 최대/최소값, 분산 등의 요약 통계값(Summary Statistics)을 계산할 수 있으며 두 데이터 집합들 간의 연관된 정도를 분석하는 상관분석 기법으로 피어스 상관분석과 스피어만 상관분석을 제공합니다.
통계적 가설의 유의성(significance) 여부 판단을 위한 카이제곱 검정을 제공합니다.
난수 데이터 생성(Random Data Generation)도 제공합니다.
R 언어를 통해 분산 처리를 할 수 도 있겠지요.
분류 및 회귀 분석
분류(Classification) 모델로는 로지스틱 회귀(Logistic Regression), 결정 트리 분류기(Decision Tree Classifier), 랜덤 포레스트 분류기(Random Forest Classifier), 선형 SVM(Linear Support Vector Machine), 나이브 베이wm 분류(Naive Bayes Classification) 등을 제공합니다.
회귀 분석(Regression Analysis) 모델로는 선형회귀(Linear Regressior)가 제공됩니다.
또한 어떤 항목에 대한 관측값과 목표값을 연결시켜주는 예측 모델로 결정트리를 사용할 수도 있습니다.
협업 필터링
추천 시스템(recommender system)에 자주 사용되는 협업필터링(Collaborative Filtering)을 제공합니다.
많은 사용자들로부터 얻은 과거의 정보(경향)로부터 사용자의 미래의 관심사를 예측하는 알고리즘으로 ALS(Alternative Least Squares)가 사용됩니다.
클러스터링
유사한 데이터들을 같은 그룹으로 군집화해주는 모델로 Kmeans 알고리즘과 잠재 디리클래 할당(Latent Dirichlet Allocation, LDA)를 제공합니다.
차원축소
차원 축소란 고차원의 데이터를 저차원의 데이터로 변환하는 알고리즘으로 원본데이터에서 특징을 추출하는데 적용됩니다.
주성분 분석(Principal Component Analysis, PCA)이나 특이값 분해(Singular Value Decomposition)가 제공됩니다.
특징 추출 및 변환
MLib는 원본 데이터로부터 특징을 추출, 변환, 선택하는 기능을 제공하고있습니다.
기계학습에서 원본 데이터로부터 학습 및 분석에 유용한 유도된 값들인 특징을 추출합니다.
TF-IDF(Term Frequency-Inverse Document Frequency), Word2Vec, Tokenizer, VectorSlicer 등이 제공됩니다.
머신러닝 소개
머신러닝은 문제를 해결하기 위한 맞춤 코드(custom code)가 아닌 일련의 데이터에 대해 무어낙 흥미로운 것을 알려줄 수 있는 generic algorithms(일반화된 알고리즘)입니다.
코드를 작성하는 대신 데이터를 일반화된 알고리즘에 공급하면, 데이터를 기반으로 한 자체 로직이 생성되게 되지요.
문제마다 알고리즘을 별도로 두는 것이 아니라 범용적으로 사용이 가능한 알고리즘인 것이지요.
분류 알고리즘 예제를 보겠습니다.
데이터를 서로 다른 그룹으로 분류해야한다합시다.
필기체 숫자를 인식에 사용되는 동일한 분류 알고리즘을 그대로 이메일의 스팸 분류에 적용합니다.
동일한 알고리즘이지만 다른 학습 데이터를 제공하면 다른 분류 로직을 자동으로 생성하게됩니다.
머신러닝은 이러한 종류의 일반화된 알고리즘을 의미하는 포괄적인 용어라고 할 수 있습니다.
머신러닝을 크게 지도학습과 비지도학습으로 구분해볼 수 있습니다.
지도학습(supervised learning)의 경우 결과에 대한 사전 지식이 필요합니다.
그래서 훈련 데이터에 라벨링이 되어있어야 합니다.
즉, 각 질문(input)에 대해 무엇이 정답(output)인지 훈련 데이터가 알고 있어야합니다.
회귀 분석, 분류, 협업필터링, 딥러닝 등이 이에 해당합니다.
비지도학습(unspervised learning)은 구체적 결과에 대한 사전 지식이 없지만 데이터를 통해 유의미한 지식을 얻고자 하는 경우에 사용됩니다.
데이터만이 존재하며 정답 레이블은 없습니다.
클러스터링이 대표적인 예이며, 차원 축소도 이에 해당합니다.
분류
지도학습의 분류 알고리즘에 대해 자세히 살펴봅시다.
구글의 gmail은 이메일의 스팸 여부를 분류(classification) 알고리즘을 사용하여 감지합니다.
이메일의 데이터(송신자, 수신자, 제목, 메시지)에 근거하여 분류합니다.
훈련된 라벨링 된 데이터가 알고리즘에 제공되는 점에서 지도학습에 해당합니다.
훈련데이터로 학습이 끝나면, 새롭게 입력된 데이터에 대해 미리 정의된 카테고리 중 하나로 분류됩니다.
대표적인 분류 문제가 스팸 메일 감지, 카드 사기 감지, 감성 분석(sentiment analysis) 등입니다.
분류기 모델을 구축하기 위해서는 첫째로 특징 추출이 필요합니다.
특징을 추출하고 특징 벡터로 변환합니다.
이후에 모델을 훈련하는데요.
훈련데이터의 입력 특징과 라벨된 출력 값들 사이의 연관성으로 분류기 모델을 훈련시킵니다.
그렇게 모델이 구축되었으면 분류 테스트를 진행합니다.
새로운 입력 데이터에 대해 특징들을 추출하고 모델에 적용 평가하여 미리 정의된 카테고리 중 하나로 분류합니다.
클러스터링
구글 news는 제목과 내용에 기반하여 뉴스 기사들을 카테고리로 그룹화하는데 클러스터링 알고리즘을 사용합니다.
클러스터링 알고리즘은 입력된 데이터(뉴스 기사 등)들의 유사성(similarity)을 분석하여 그룹화된 카테고리로 분류합니다.
하지만 라벨이 붙지 않은 훈련데이터로부터 패턴을 찾아내는 것이므로 비지도 학습에 해당합니다.
패턴이란 높은 유사성을 갖는 것을 말하면 클러스터는 그러한 개체들끼리 군집화하는 일을 합니다.
대표적인 문제로는 검색 엔진의 검색 결과들의 그룹화, 고객 관리를 위한 고객들의 그룹화, 사기 감지(fraud detection)를 위한 비정상성 감지, 도서를 장르 별로 분류 하는 것 등이 있겠습니다.
클러스터링의 대표 알고리즘으로는 kmeans 알고리즘이 있습니다.
kmeans 알고리즘에 대한 자세한 설명은여기를 누르시면 볼 수 있습니다.
회귀
회귀의 대표 모델로 선형 회귀 분석을 학습하겠습니다.
선형 회귀 분석은 데이터 포인트들 간의 관계를 고려하여 기울기를 결정하는 직선을 정의합니다.
선형 특성상 이상치(outlier)에 민감하므로 기울기에 영향을 주게 된다는 단점을 갖습니다.
추천
대표적인 추천 알고리즘인 협업 필터링을 학습하겠습니다.
아마존의 사용자의 이력과 다른 사용자와의 유사성에 근거하여 사용자의 구매 의사가 있는 상품을 추천하는 알고리즘으로 협업 필터링(Collaborative Filtering)을 적용합니다.
협업 필터링 알고리즘은 많은 사용자들의 선호도 정보(preference information)에 기반으로 항목을 추천합니다.
유사성(similarity)에 기반을 두고 있는 것인데요, 과거에 같은 항목들을 선호하는 사람들은 미래에도 비슷한 항목들을 선호한다는 가정을 갖습니다.
예를 들어 ted는 영화 a,b,c를 선호하며 carol은 b,c를 선호하고 bob은 b를 선호한다고 할 때 bob에게 c 영화를 추천하는 것이지요.
b를 선호한 사용자들이 c도 선호했으니까요.
즉 협업 필터링 알고리즘은 사용자들의 선호도 정보를 입력 받아 추천 또는 예측에 사용되는 모델을 생성하는 것이지요.
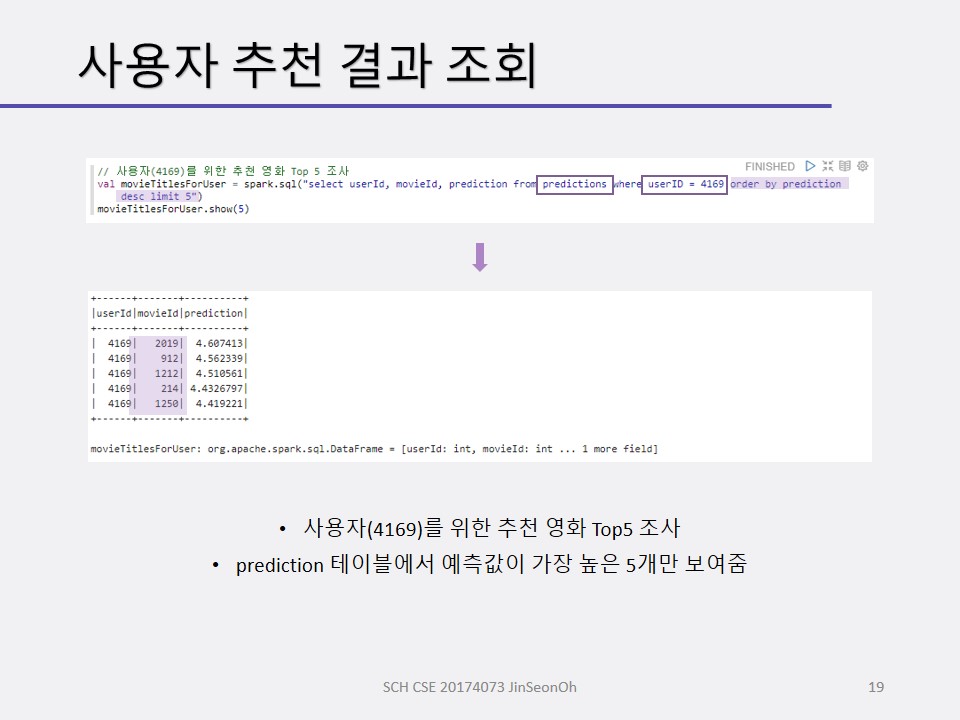
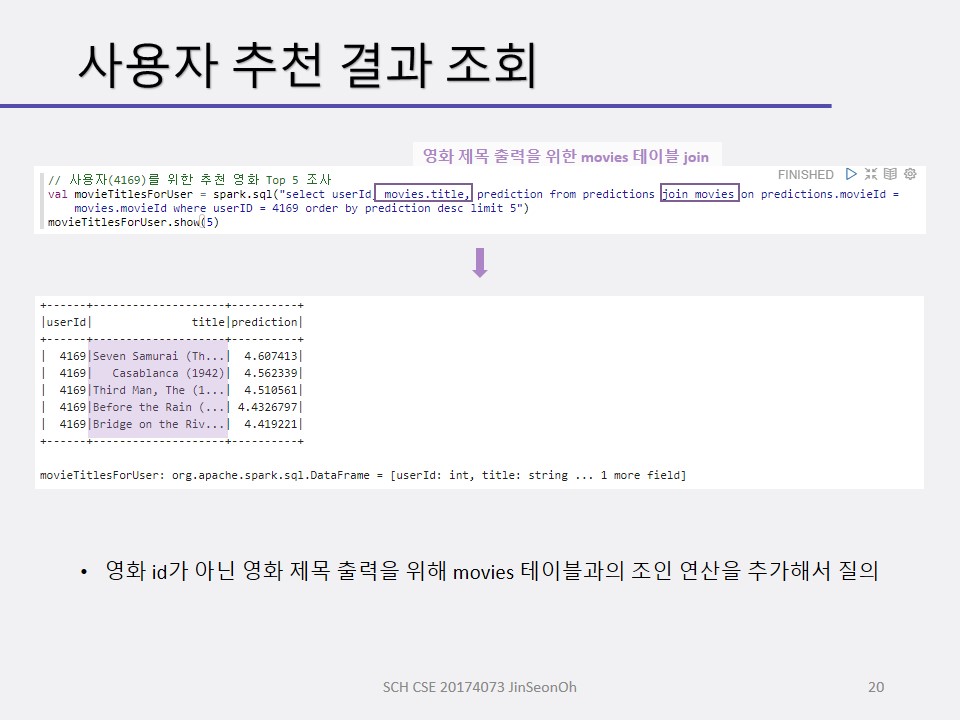
사용자 선택 예측을 위한 협업 필터링 실습
영화 추천 예를 볼 것입니다.
협업 필터링 알고리즘은 사용자의 영화 선호도를 입력 받아 훈련시켜 모델을 생성하고, 이 모델을 사용하여 사용자의 영화 선호도를 예측합니다.
협업필터링의 estimation 방법인 교차 최소 제곱(Alternating Least Squares) 알고리즘을 먼저 보겠습니다.
다수의 사용자와 항목(영화) 사이에서 관측된 상호 작용(observed interaction, 영화 추천)을 상대적으로 적은 수의 관측되지 않은 숨은 원인(unobserved underlying reason)으로 설명하고자 할 때 사용합니다.
관측된 상호 작용은 희소 행렬(sparse matrix)에 의해 표현됩니다.
희소 행렬이란 작고 밀도가 높은 행렬 곱으로 분해된 행렬을 말합니다.
협업필터링에서는 교차 최소 제곱에 의해 에러값을 최소화 시키는 방향으로 희소행렬들의 각 성분을 결정하게 됩니다.
USER와 ITEM간의 관측된 상호작용에 대한 행렬이 아래와 같다고 합시다.
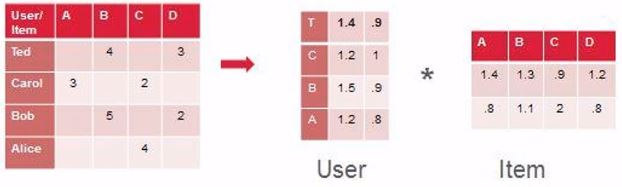
보여지는 행렬은 저렇게만 있지만 숨은 잠재요인과의 관계를 뽑아보겠다는 것이 모티브가 된다했었지요?
그래서 USER와 잠재요인 간의 희소행렬, 잠재요인과 ITEM 간의 희소행렬을 표현해냅니다.
각 잠재요인 관련 행렬의 성분들의 초기값은 보통 랜덤으로 주어질 것이고요, 교대로 두 요인 행렬 중 하나를 고정시키고 다른 요인 행렬의 해(solution)을 구합니다.
교차 최소 제곱은 수렴 시까지 반복적으로 수행되는 알고리즘(iterative algorithm)입니다.
두 행렬 간(관측행렬과 잠재행렬들의 행렬곱 결과 행렬)의 대응되는 원소 간의 차의 제곱의 합을 최소화하는 방향으로 학습이 진행됩니다.
즉, 잠재요인 행렬들의 각 성분들이 우리가 맞출 파라메터들이 되는 것이지요.
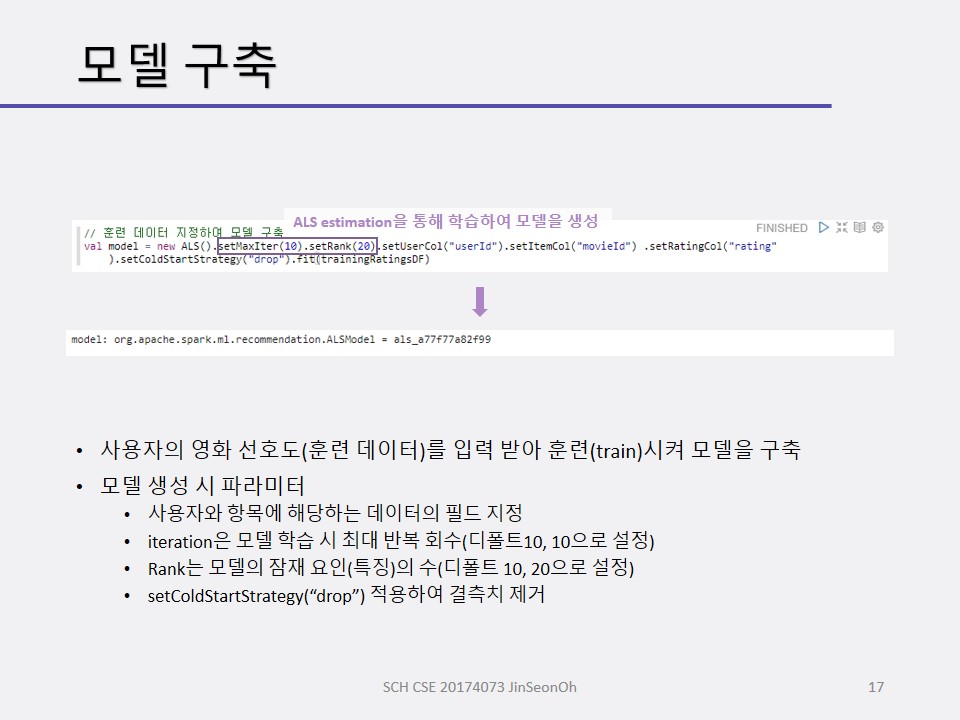
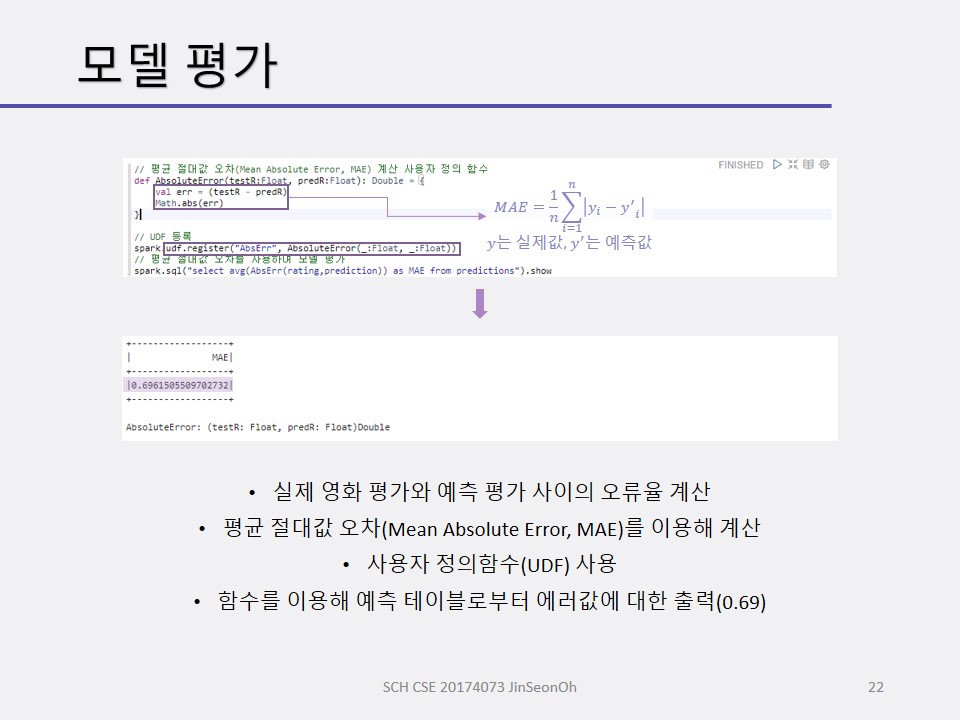
간단히 살펴보았지만 학습한 이유는 협업필터링 알고리즘은 이미 MLib에 함수로 구현이 되어있고 사용이야 뚝딱할 수 있지만 왜 이런 결과가 나왔는지, 어떤결과를 의도하려면 각 파라미터들을 어떻게 조정해서 넣는 것이 좋을지 그 의미를 알고 사용하기 위해서 사전학습을 해본 것입니다.
우리는 아래와 같은 머신러닝 처리 절차에 의해 영화 추천 예제로 실습을 진행할겁니다.
- 샘플 데이터를 적재하고 ALS 알고리즘의 입력 형식을 변환
- 모델을 훈련/구축 및 테스트 용으로 데이터를 분할
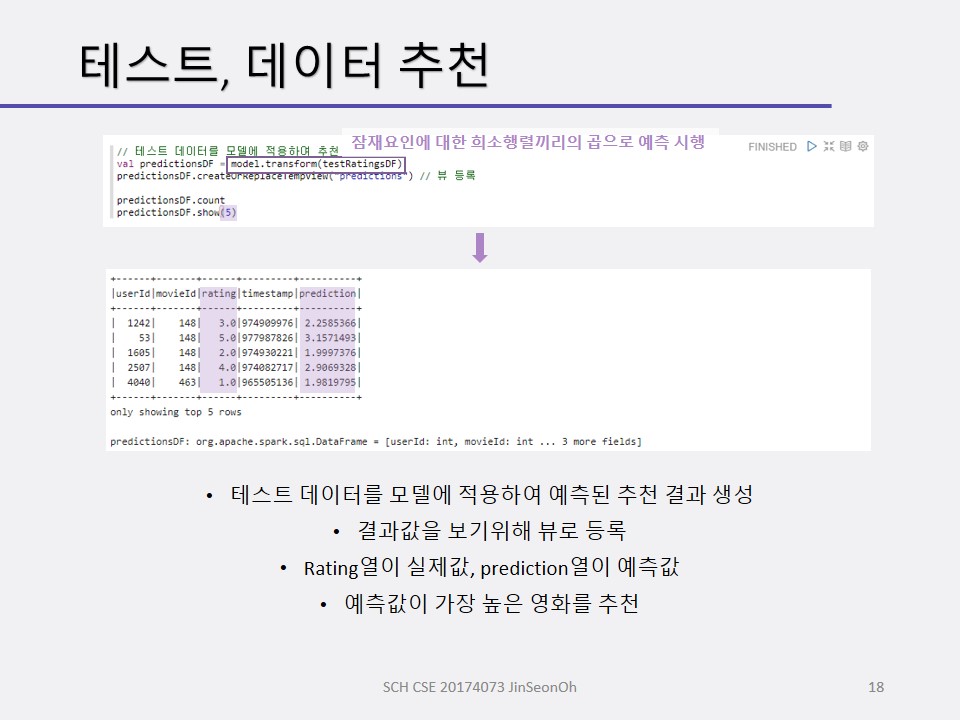
- 모델을 훈련하고 구축(훈련 데이터로 예측하고 결과 관측)
- 테스트 데이터로 모델 테스트
스파크 스칼라 API 문서는 아래 사이트를 참조하시기 바랍니다.
https://spark.apache.org/docs/latest/api/scala/index.html


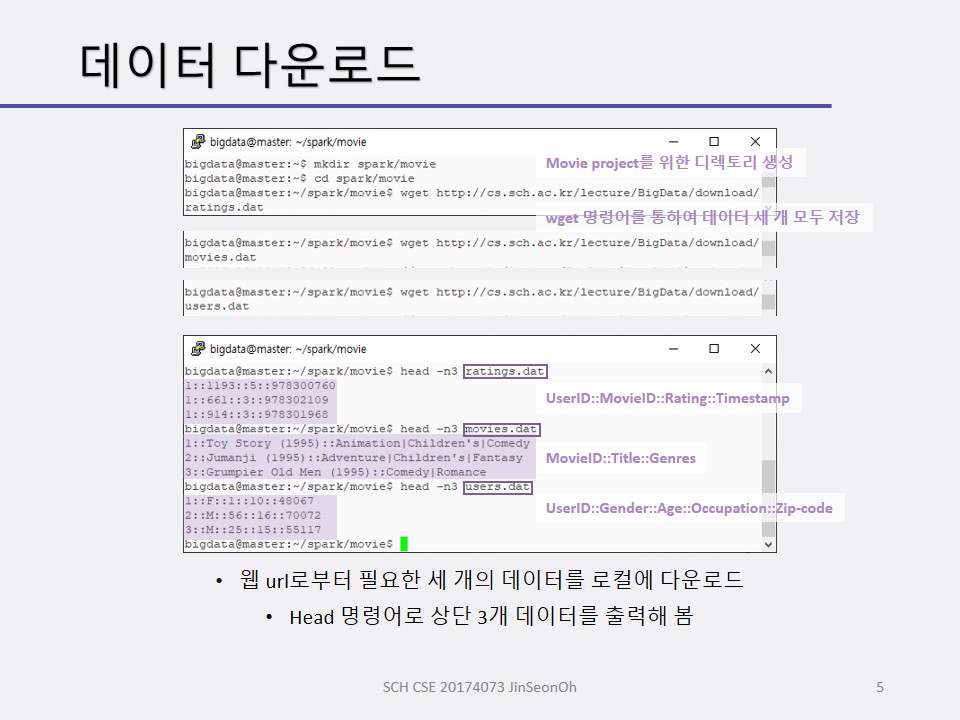
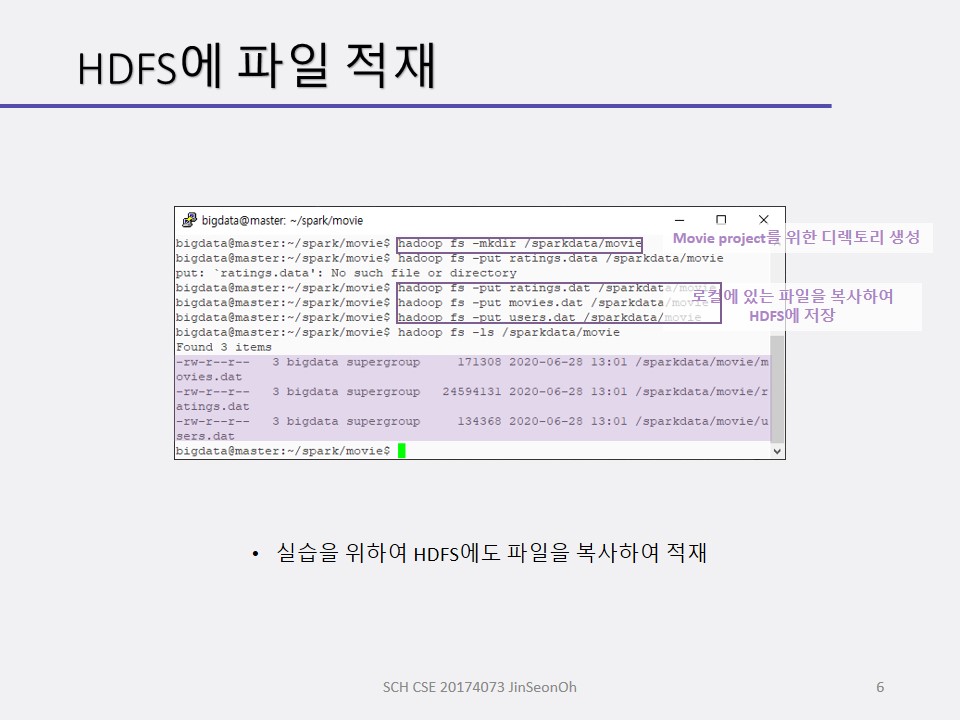
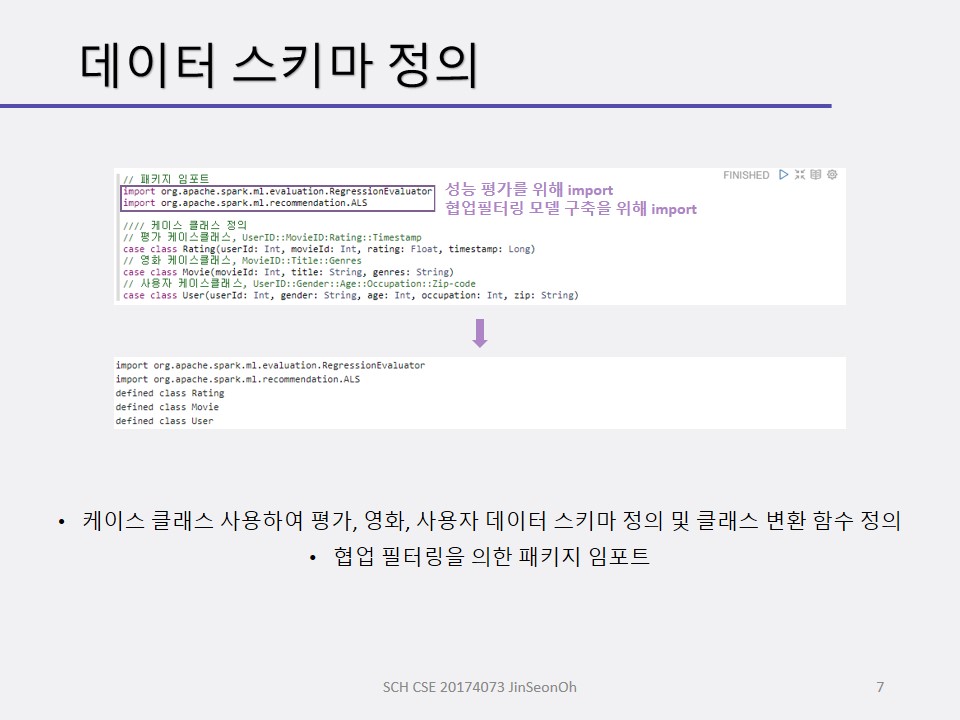


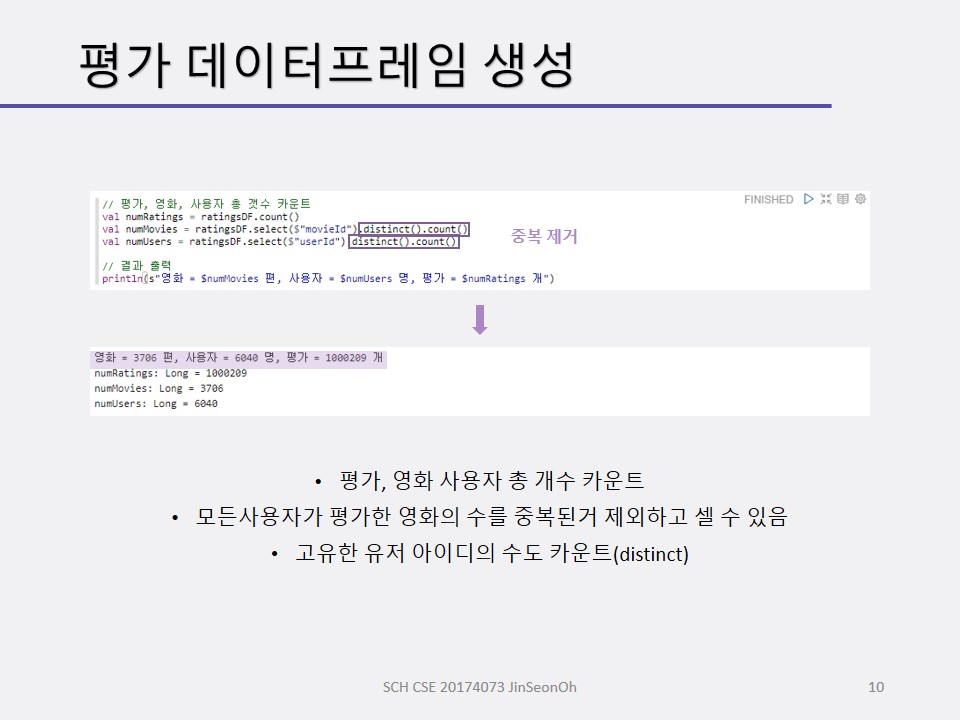

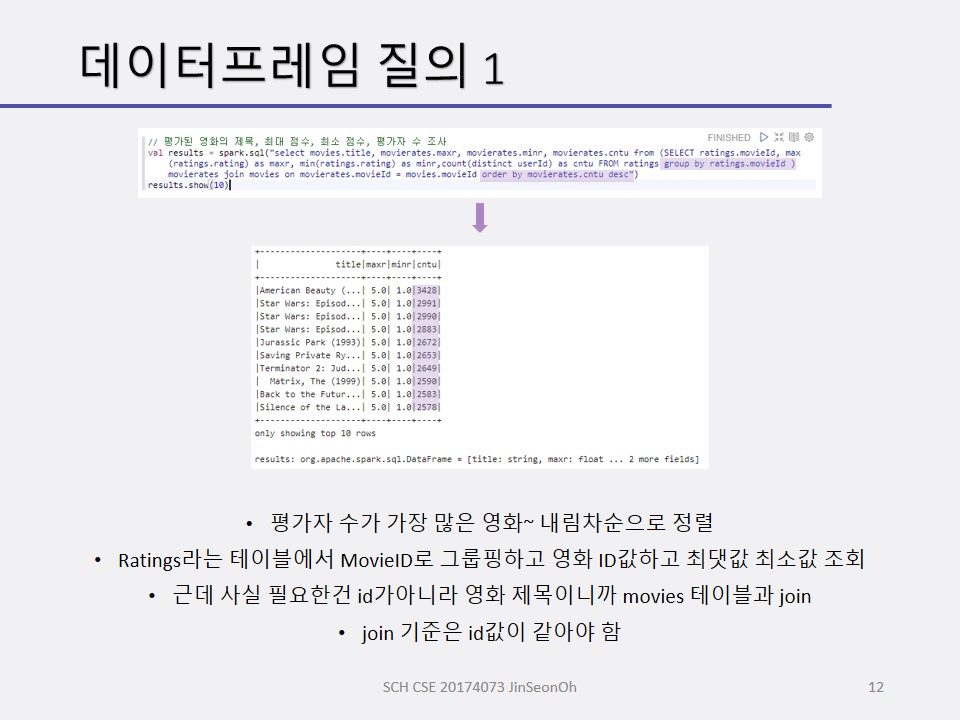
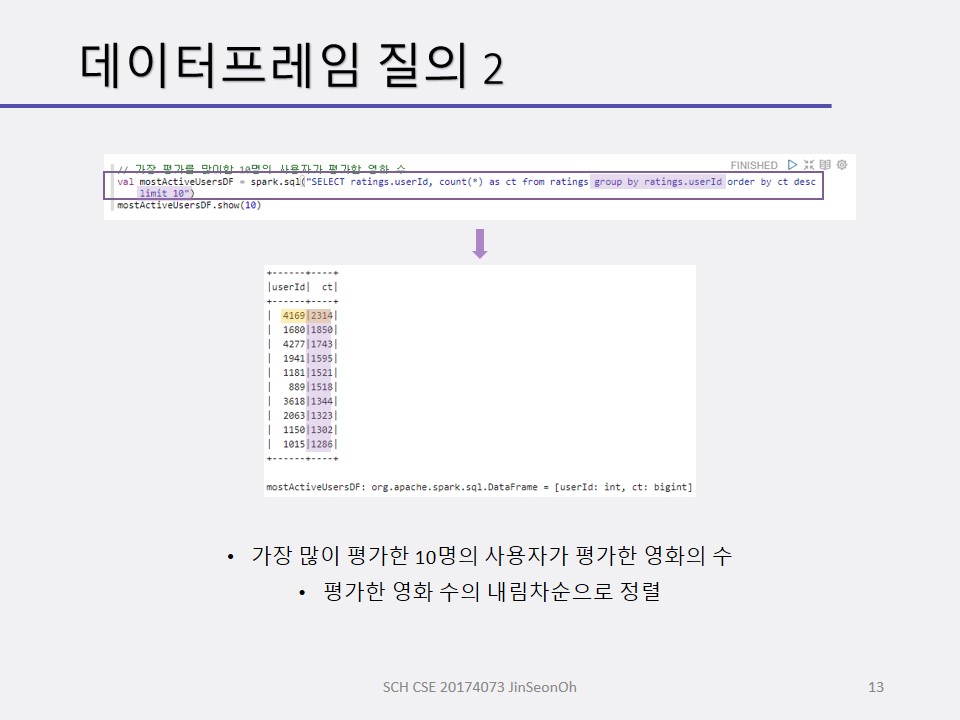
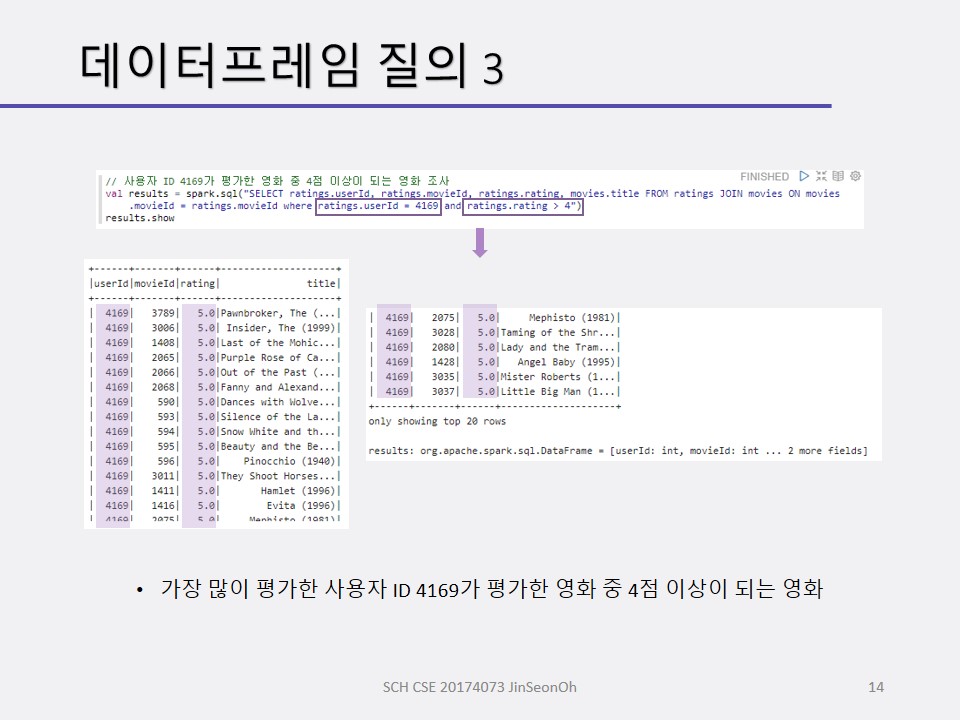




개인이 공부하고 포스팅하는 블로그입니다. 작성한 글 중 오류나 틀린 부분이 있을 경우 과감한 지적 환영합니다!