
Perceptron LAB_Machine Learning(13)
Intro
학교 수강과목에서 학습한 내용을 복습하는 용도의 포스트입니다.
기존에 수강했던 인공지능과목을 통해서나 혼자 공부했던 내용이 있지만 거기에 머신러닝 수업을 들어서 보충하고 싶어서 수강하게 되었습니다.
gitlab과 putty를 이용하여 교내 서버 호스트에 접속하여 실습하는 내용도 함께 기록하려고 합니다.
위 링크들 중 Perceptron 모델에 대한 설명은 Machine Learning(8)에 있습니다.
Perceptron LAB
실습을 하기 위해 데이터를 다운받아주세요.
데이터 디스크립션 읽어보고 data folder에 들어가서 iris.data를 다운받아주세요!
1.데이터를 로컬의 data/에 담고 git add/commit/push 실습
데이터를 먼저 다운로드 받습니다.
저는 아래 캡처화면과 같이 리눅스의 wget 명령어를 통해 url로부터 호스팅되어있는 iris 데이터를 다운로드 받았습니다.
wget https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data
ls 명령어를 통해 데이터셋이 잘 다운로드 되었음을 확인하였습니다.
이후에는 git과 친해지기 위한 실습으로, 수정사항을 커밋하고 내역을 깃랩 원격 레포지토리로 푸시해보는 것입니다.
제 깃랩 레포지토리 링크를 여기에 걸어두겠습니다.
2.jupyter notebook 켜서 python 예제코드 작성
터미널에 jupyter notebook을 입력해주시고, 윈도우 호스트에서 웹브라우저를 통해 발행받은 토큰을 입력하여 새 python 코드(prac004.ipynb)를 생성합니다.
이 때 아래 캡처를 참고하여 소스코드와 데이터 리소스의 상대적 위치를 확인해주시기 바랍니다!
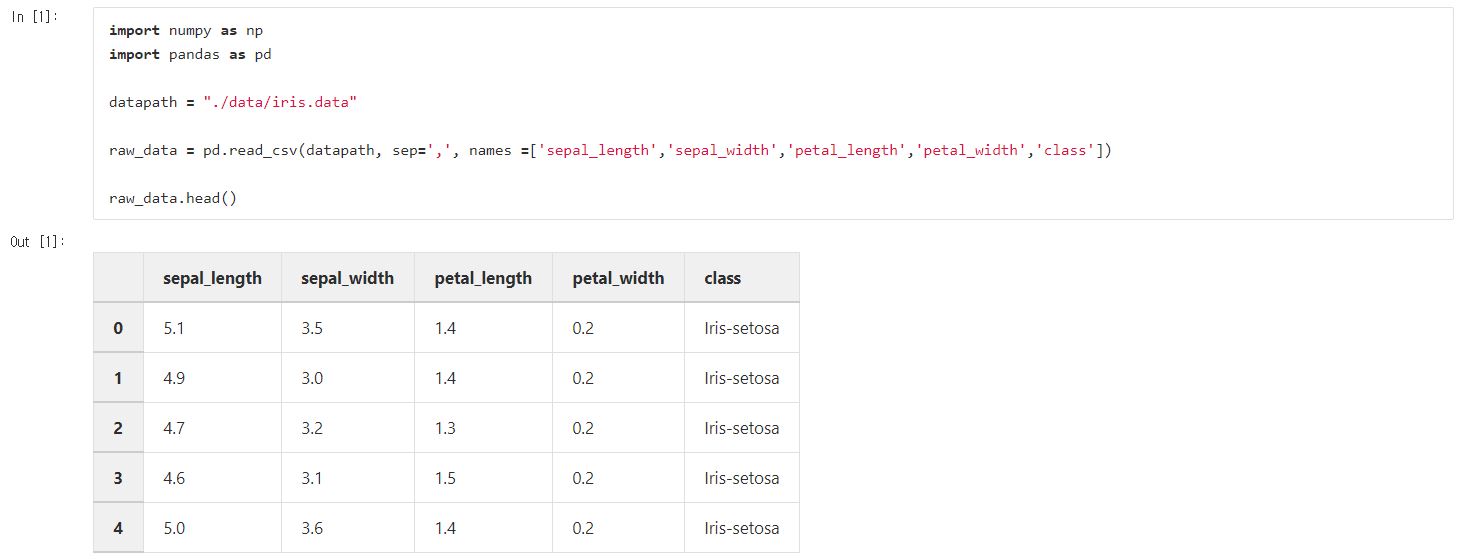

데이터의 head만 출력해보면 UCI 홈페이지에서는 attribute가 4개라했는데 5개가 나오죠. 맨 오른쪽 문자열이 우리가 맞히게 될 label에 해당된다는 것을 뜻합니다.
사람마다 다르게 불러서 그래요!

실제로 UCI에 나와있는 것도 보면classifictaion으로 나와있습니다.
구분자는 콤마로 보이구요.
read_csv()는 판다스의 dataframe객체를 생성해서 반환해줍니다.
그 때 인수로 주게 되는 컬럼명은 임의로 줄 수 있습니다.
.head() 메소드는 데이터의 위 일부만 보여줍니다. Default는 5줄입니다.
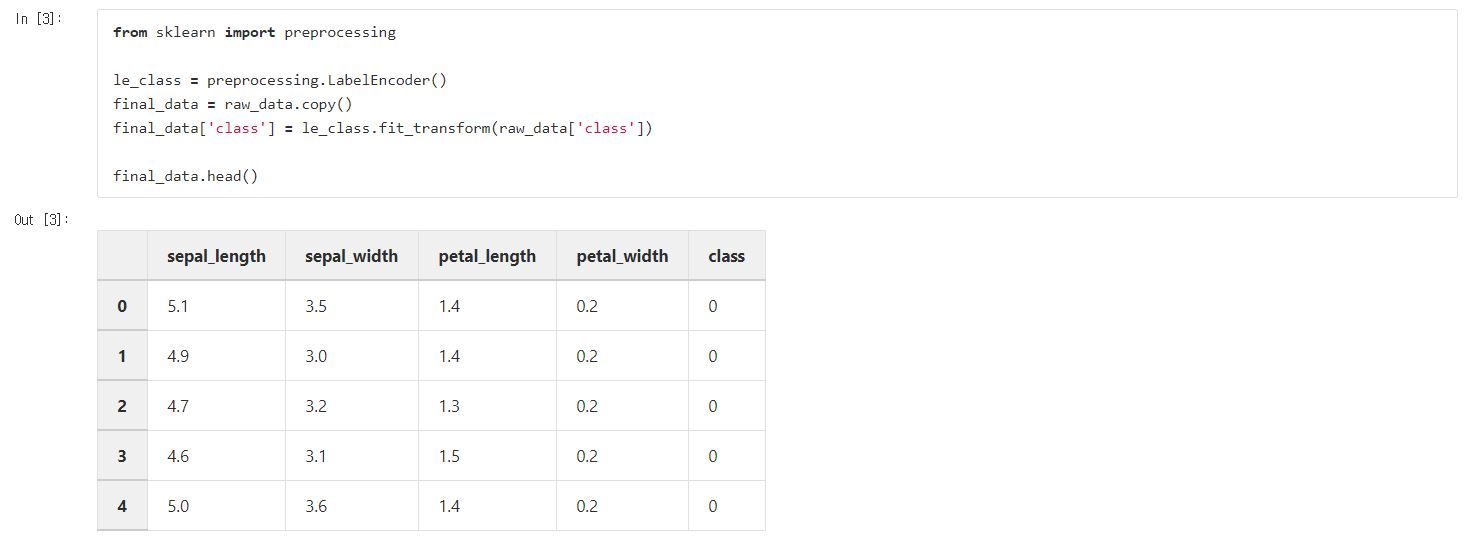
Preprocessing을import 해줍니다.
Labelencoder() 객체를 생성해줍니다.
Raw_data를 복제 뜹니다. (사실굳이 안해도 되지만)
혹시 모를 상황에 대비해 원본데이터는 따로 두고 데이터 전처리를 하기 위해서 복제를 한 것이라고 보시면 됩니다.
Labelencoder 객체에 대해 fit_transform()을 호출했네요.
Fit_transform()은인수로 들어온 attribute를 레이블로 취급하여 fit(학습의개념으로 많이 사용되는 용어지만 여기서는 Iris-setosa에게 0번을, Iris_virginica를 1번,Iris_versicolor를 2번으로 부여해주는 것을 말함)시키고, transform도 해주는거에요. 어떤 transform을 해주냐 하면 raw data의 클래스에 실질적으로 적용을 합니다.
{
0:“Iris_setosa”,
1:“Iris_virginica”
2:“Iris_versicolor”
}
이렇게 쌍만 만들어놓은 것이 fit, 실제로 클래스에 적용시킨 것이transform이요.
이렇게 변환하고 난 후 출력을 해보면 레이블이 바뀐 것을 확인할 수 있죠.
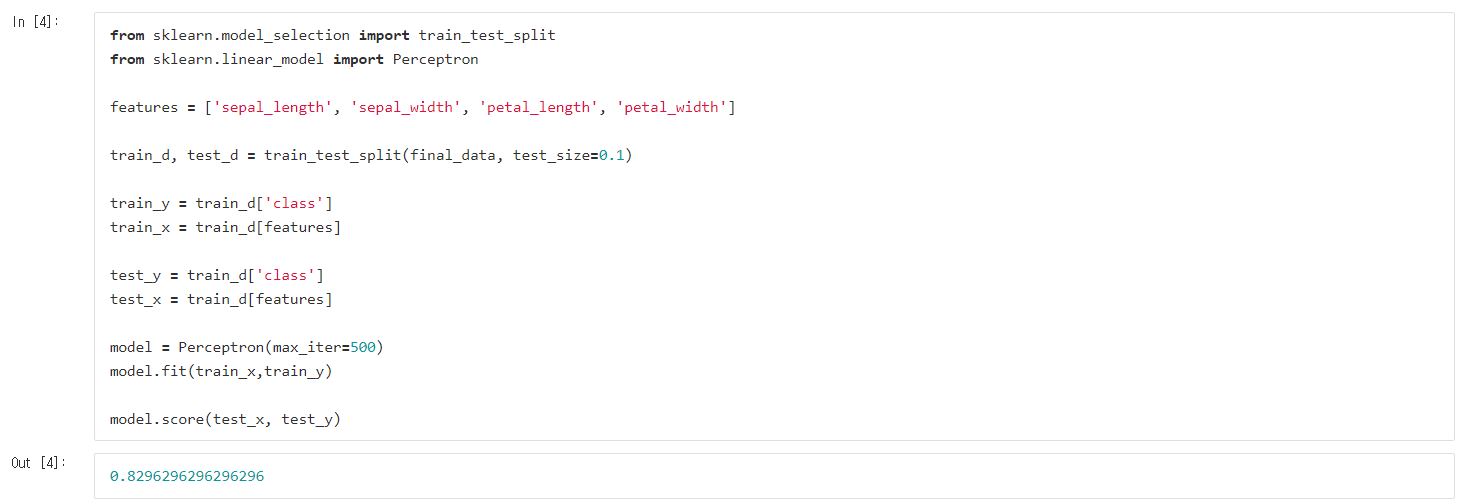
이후에는 perceptron을 통해서 학습시켜봅니다.
참고사항)
labelEncoder-> 레이블을 위한 인코딩
onehotEncoder -> feature들을 위한 인코딩
개인이 공부하고 포스팅하는 블로그입니다. 작성한 글 중 오류나 틀린 부분이 있을 경우 과감한 지적 환영합니다!